df.index # ~ df.keys()
#list()
df.keys()이렇게 키와 인덱스에도 접근이 가능하다.

df에서 인덱스로 접근은 조금 다른 방식으로 진행된다.
넵다 df[0]은 오류가 발생한다.

이렇게 진행해야 제대로 된 값을 출력하는 것을 볼 수 있다.

이렇게 key 값으로도 접근이 가능하다.
두 개 이상의 열을 확인할 때는 이중 list를 사용해서 두개 다 표현해준다.

특정 row와 col에 접근할 땐 이렇게 해야 한다.

df["age"]=[10,10,10,30,30]이렇게 해서 나이를 추가할 수 있다.
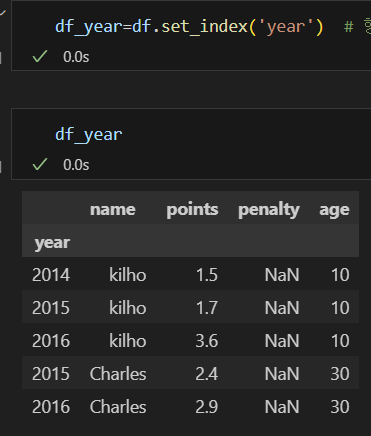
이젠 인덱스를 특정한 열로 변경을 해본다.
boolen 값을 이용해 여러개 중 하나만 뽑을 땐 df안에 넣어서 참, 거짓을 활용한다.


이런 형식을 통해 출력이 되는 것이다.
여기선 df 순서가 좀 뒤죽박죽이라 four가 안보인다 ...

Pivot을 통해 dataframe를 변환할 수 있다.
test_pivot = df.pivot(index="year", columns="name", values="points")
print(type(test_pivot))
test_pivot
이제 특정한 열이 고유한지 .unique로 확인가능하다.

rename을 통해 이름 변경도 가능함


여기선 set_index를 통해 index를 year로 변경해주고, setindex에 주입해줬다.

info()를 통해 데이터 정보를 확인 가능

통계 정보도 확인 가능하다.

median을 통해 중앙 값도 확인 가능

sorting도 가능하다.
여기선 index가 알파벳이므로 저렇게 sorting 되는 것을 볼 수 있다.

count를 통해 NaN(Null 값)이 아닌 값들의 수를 센다.

여기선 각 값들이 고유한지 확인 가능!

NaN인 값들을 카운트하도록 변경할 수 있음

이렇게 축을 돌려가면서도 파악 가능함
plot
DataFrame.plot.bar() : 막대 그래프
DataFrame.plot.line() : 선 그래프
DataFrame.plot.scatter(x, y) : 산포도 그래프
DataFrame.plot.box() : Box 그래프
df.plot(kind='scatter', x='year', y='age')
그래프는 이렇게 보여줍니다.
'언어 > Python' 카테고리의 다른 글
| 오랜만에 파이썬 복습하기 - List, Tuple, Set, Dictionary, numpy (2) | 2025.04.04 |
|---|---|
| 이미지에서 텍스트(한글, 영어, 숫자) 인식하기 - Python (2) | 2024.05.07 |
| 선형대수 및 프로그래밍 과제 python 2 - gauss-Jordan Elimination 사용하여 해 구하기 , ref (0) | 2024.04.21 |
| 선형대수 및 프로그래밍 과제 python 1 - 행렬 합 구하기 (0) | 2024.04.21 |
| 일반일을 위한 물리 코딩 과제 모음 (1) | 2024.04.14 |