https://www.developer.com/languages/python/extract-text-images-python/
Extracting Text from Images in Python | Developer.com
Learn how to extract text from images and process images using Google’s Tesseract, MAriaDB, and Python, complete with code examples.
www.developer.com
홈페이지입니다!
여기서 기본 코드는 가지고 왔씁니다.

이러한 사진에서 텍스트를 추출해달라고 해서 한번 해봤는데,.....ㅠ
이미지가 너무 지저분해서 잘 안되더라고여
일단 하나하나 차근차근 진행해줬습니다..
이거 설치해줍니다. 그냥 다 okok하면서 지나가버렸씁니다.
https://github.com/UB-Mannheim/tesseract/wiki
Home
Tesseract Open Source OCR Engine (main repository) - UB-Mannheim/tesseract
github.com

중앙의 setup파일을 다운받으면 됩니다.
cmd에서 밑의 코드를 입력해서 설치해줍시다!
pip install pytesseract다 okok 해서 한글 데이터가 없다고 나오면 여기서 설치한 뒤 C:\Program Files\Tesseract-OCR\tessdata경로에 추가해주면 됩니다.
설치할 파일 이름은 kor.traineddata입니다.
https://github.com/tesseract-ocr/tessdata/blob/main/kor.traineddata
tessdata/kor.traineddata at main · tesseract-ocr/tessdata
Trained models with fast variant of the "best" LSTM models + legacy models - tesseract-ocr/tessdata
github.com
이제 실행해보면 됩니다....
from PIL import Image,ImageEnhance, ImageFilter
import os
import pytesseract
import sys
import cv2
# You must specify the full path to the tesseract executable.
# In Linux, you can get this by using the command:
# which tesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def main(directory):
# 디렉토리 내 모든 파일과 하위 디렉토리 검색
for root, dirs, files in os.walk(directory):
for file in files:
if file.lower().endswith((".png", ".jpg", ".jpeg", ".tiff", ".bmp", ".gif")): # 이미지 파일 확장자
image_path = os.path.join(root, file)
try:
print(f"Found filename [{image_path}]")
# 이미지 파일을 사용하여 OCR 수행
ocrText = pytesseract.image_to_string(Image.open(image_path), lang='kor+eng', timeout=5)
print(ocrText)
print("")
except Exception as err:
print(f"Processing of [{image_path}] failed due to error [{err}]")
# 디렉토리는 잘 정해주면 됩니다...
main(r'C:\img')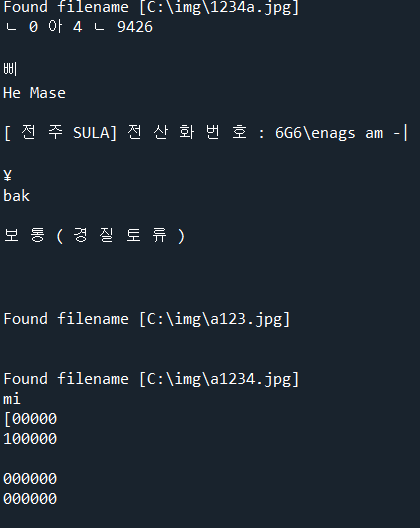
이미지가 너무 지저분해서 그런지 인식을 못하네요....ㅠ.................
'언어 > Python' 카테고리의 다른 글
| 오랜만에 파이썬 복습하기 - List, Tuple, Set, Dictionary, numpy (2) | 2025.04.04 |
|---|---|
| 선형대수 및 프로그래밍 과제 python 2 - gauss-Jordan Elimination 사용하여 해 구하기 , ref (0) | 2024.04.21 |
| 선형대수 및 프로그래밍 과제 python 1 - 행렬 합 구하기 (0) | 2024.04.21 |
| 일반일을 위한 물리 코딩 과제 모음 (1) | 2024.04.14 |
| 일반인을 위한 물리 코딩 - 중간 과제 어린왕자 행성 크기와 중력, 중력 가속도 (26) | 2024.04.14 |