https://arxiv.org/abs/2501.09749
Enhancing Lexicon-Based Text Embeddings with Large Language Models
Recent large language models (LLMs) have demonstrated exceptional performance on general-purpose text embedding tasks. While dense embeddings have dominated related research, we introduce the first Lexicon-based EmbeddiNgS (LENS) leveraging LLMs that achie
arxiv.org
기존 Dense embedding의 문제점을 말합니다.

그리고 Attention도 뒷 단어를 활용하지 못한다는 문제점도 있죠 - 학습시에


MTEB Sota를 달성해 버립니다.

AIR-Bench에서도 1등은 아니지만 높은 점수를 받았습니다.
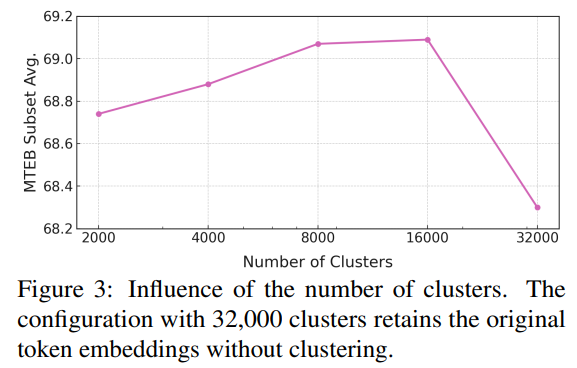
너무 많은 Cluster를 사용하면 오히려 성능이 떨어지는 모습을 보입니다.

BGE와 합치니 더 높은 성능을 보이는 것을 알 수 있습니다.
| 🧑💻 연구 목적 | 기존 Dense Embeddings과 Lexicon-based Embeddings의 한계를 보완하여 검색 성능을 최적화하고, 효율적인 임베딩을 생성하는 새로운 방법(LENS)을 제안 |
| 🚀 핵심 기여 (Key Contributions) | ✅ Token Clustering → 의미적으로 유사한 토큰을 묶어 어휘 공간 최적화 ✅ Bidirectional Attention → 기존 단방향 LLM의 한계를 극복하여 더 정확한 문맥 반영 ✅ Dense + Sparse Embeddings 결합 가능 → Retrieval 성능을 최적화하는 Hybrid Embeddings 제공 |
| 💡 기존 연구와의 차별점 | 1️⃣ 기존 Dense Embeddings과 비교: - Dense Embeddings(BGE-en-ICL, E5 등)은 Sparse Representation을 지원하지 않음 - LENS는 Sparse Representation을 적용하여 검색 성능과 해석 가능성 증가 2️⃣ 기존 Lexicon-based Embeddings과 비교: - SPLADE 등 기존 연구들은 단어별 표현력은 뛰어나지만 문맥 반영이 부족 - LENS는 Bidirectional Attention을 적용하여 문맥 정보를 더욱 풍부하게 활용 |
| ❌ 기존 연구의 한계점 | ❌ 기존 LLM 토크나이저의 중복 토큰 문제 해결 X ❌ 기존 Lexicon-based Embeddings의 문맥 반영 부족 ❌ Dense Embeddings과 Sparse Embeddings 결합 불가능 |
| 🛠 LENS의 주요 기법 | 1️⃣ Token Clustering → 의미적으로 유사한 토큰을 클러스터링하여 어휘 공간을 정리하고, 효율적인 Sparse Representation 생성 2️⃣ Bidirectional Attention → 기존 LLM의 단방향 Attention을 극복하여 더 정확한 문맥 정보를 반영 3️⃣ Hybrid Embeddings → Dense + Sparse Representation을 결합하여 최적의 검색 성능 제공 |
| 🧪 실험 결과 (MTEB Benchmark) | 📌 LENS-8000이 MTEB 전체 태스크에서 최고 성능 기록 📌 Dense Embeddings(BGE-en-ICL)보다 높은 성능 (71.62 vs. 71.24) 📌 Sparse Representation을 유지하면서도 Dense 수준의 효율성 제공 |
| 🔍 실험 결과 (AIR-Bench: 도메인별 검색 성능) | 📌 NV-Embed-v2와 유사한 검색 성능 (법률, 의료, 금융 등 다양한 도메인에서 강력한 성능) 📌 Dense Embeddings(BGE-en-ICL)과 비교해도 성능 손실 없음 |
| 🛠 Hybrid (LENS + Dense) 실험 결과 | 📌 LENS + Dense Embeddings(BGE-en-ICL) 조합 시, 최고 검색 성능 달성 (BEIR: 63.00, SOTA 성능) 📌 Dense Embeddings과 Sparse Embeddings의 결합이 효과적임을 증명 |
| 📢 결론 (Conclusions) | ✅ Lexicon-based Embeddings을 LLM과 결합하여 기존 한계를 극복하는 새로운 방법 제안 ✅ Dense Embeddings과 결합 가능하여 검색 성능 최적화 ✅ Sparse Representation을 사용하면서도 기존 Dense 수준의 효율성 유지 |
| 🔍 한계점 (Limitations) | ❌ 다국어 지원 부족 → 영어 데이터셋에만 한정됨 (향후 MIRACL 데이터셋 적용 가능) ❌ Mistral-7B에 최적화됨 → GPT-4, Gemini 등에서 실험 필요 ❌ Sparse Representation의 계산 비용 문제 해결 필요 |
| 📌 향후 연구 방향 | 🚀 다국어 LENS 개발 (MIRACL 활용) → 다국어 Sparse Representation 연구 🚀 Sparse Autoencoder 기반 embedding 압축 연구 → Sparse Representation을 더욱 효율적으로 압축하는 기법 개발 🚀 MoE (Mixture of Experts)와 결합 → Sparse Representation을 활용한 Expert Selection 최적화 연구 🚀 LLM 기반 논문 검색 및 요약 AI 개발 → LENS를 활용한 논문 검색 및 요약 자동화 |
| 🔥 최종 요약 (Key Takeaways) | LENS는 Token Clustering + Bidirectional Attention을 활용하여 Dense와 Sparse Embeddings의 장점을 결합한 새로운 임베딩 프레임워크이다. Dense Embeddings의 효율성과 Sparse Embeddings의 검색 성능을 동시에 제공하여, NLP 연구 및 검색 시스템에서 강력한 성능을 발휘할 것으로 기대된다. 🚀 |
논문 요약: Enhancing Lexicon-Based Text Embeddings with Large Language Models
1. 연구 배경 및 문제 정의
최근 대형 언어 모델(LLM)은 일반적인 텍스트 임베딩(task)에서 우수한 성능을 보였다. 현재의 연구는 주로 Dense Embeddings(밀집 임베딩)에 집중되어 있으나, 본 논문에서는 Lexicon-Based Embeddings(어휘 기반 임베딩)을 LLM과 결합하는 LENS라는 새로운 접근법을 제안한다.
기존 LLM의 한계는 다음과 같다:
- 토크나이제이션(tokenization) 중복성: LLM의 토크나이저는 같은 의미를 가진 단어들을 여러 개의 토큰으로 나누어 비효율적인 어휘 공간을 형성한다.
- 단방향(causal) 주의(attention) 구조: 기존 LLM들은 단방향 주의를 사용하여 문맥 정보를 충분히 반영하지 못한다.
이를 해결하기 위해 LENS는 다음을 수행한다:
- 토큰 임베딩 클러스터링(token embedding clustering)을 사용하여 의미적으로 유사한 토큰을 그룹화함.
- 양방향 주의(bidirectional attention) 및 다양한 풀링 전략(pooling strategies)을 실험하여 성능을 향상함.
2. 기존 연구와 차별점
Lexicon-Based Embeddings (어휘 기반 임베딩)
- 기존 연구(SPLADE, Formal et al., 2021b)는 Mask Language Model(MLM)을 사용하여 lexicon-based embeddings을 생성하였으나, 대부분 작은 모델에서만 연구되었고, LLM을 활용한 연구는 부족했다.
- 최근 연구들(Shen et al., 2023a)은 Dense + Lexicon Embeddings 조합이 효과적임을 입증했으나, 여전히 검색(retrieval) 중심으로 활용되었음.
LLM 기반 임베딩 연구
- LLM2Vec (BehnamGhader et al., 2024) 및 LLaRA (Li et al., 2023a)는 LLM을 활용한 밀집 임베딩 모델을 개발했지만, lexicon-based embeddings에 대한 연구는 부족했다.
- PromptReps (Zhuang et al., 2024)와 Mistral-SPLADE (Doshi et al., 2024)는 LLM에서 lexicon-based embeddings을 생성하기 위해 프롬프트 엔지니어링을 활용했으나, 성능이 dense embedding보다 낮았다.
3. 연구 방법론: LENS 프레임워크
LENS는 LLM을 이용하여 lexicon-based embeddings을 생성하는 새로운 방법론이다. 기존 문제를 해결하기 위해 두 가지 핵심 기법을 도입했다.
1) 토큰 임베딩 클러스터링(Token Embedding Clustering)
- 기존 LLM의 토큰들은 의미적으로 중복되는 경우가 많음 (예: "education" → "edu", "cation").
- LENS는 K-Means 클러스터링을 사용하여 의미적으로 유사한 토큰들을 묶고, 이 클러스터 중심(centroid)을 새로운 임베딩으로 사용.
- 이렇게 하면 어휘 공간의 중복을 줄이고, 기존 lexicon-based embeddings보다 더 작은 차원의 벡터(4000D 또는 8000D)를 생성 가능.
2) 양방향 주의(Bidirectional Attention) 도입
- 기존의 LLM (예: GPT-계열)은 단방향 주의(causal attention) 를 사용하여 문맥 정보를 충분히 반영하지 못함.
- LENS는 양방향 주의(bidirectional attention) 를 적용하여 lexicon-based embeddings의 성능을 극대화.
3) Representation Generation & Training
- 기존 SPLADE 모델과 유사하게, logits을 정규화한 후 max-pooling을 적용하여 최종 lexicon-based embeddings을 생성.
- 학습은 InfoNCE Loss를 사용하여 쿼리와 문서 간 코사인 유사도를 극대화.
- LENS는 BGE-en-ICL과 동일한 데이터셋을 사용하여 fair comparison을 수행.
4. 실험 및 결과
LENS의 성능을 평가하기 위해 MTEB (Massive Text Embedding Benchmark) 및 AIR-Bench에서 비교 실험을 수행하였다.
1) MTEB 벤치마크 성능
- LENS-8000은 MTEB 전체 평균 성능에서 최고 점수를 기록.
- Dense Embeddings을 사용한 BGE-en-ICL보다 성능이 우수하며, 특히 6개 task 유형에서 더 높은 성능을 보임.
- 기존 연구들(E5-mistral, NV-Embed-v2)과 비교해도 경쟁력 있는 결과를 달성.
2) AIR-Bench 성능
- LENS-8000은 다양한 도메인(법률, 금융, 헬스케어)에서 SOTA 모델인 NV-Embed-v2보다 뛰어난 성능을 기록.
- Dense Embeddings을 사용하는 BGE-en-ICL보다는 성능이 약간 낮지만, 일부 서브태스크에서는 경쟁력을 유지.
3) Hybrid Lexicon-Dense Embeddings 조합
- LENS와 dense embeddings(BGE-en-ICL)을 결합하면 성능이 개별 모델보다 더 향상됨.
- 특히, BEIR 데이터셋에서 최고 성능을 기록, 이는 lexicon-based + dense embeddings 조합이 강력함을 증명.
5. 추가 분석 및 발견
1) 클러스터 개수(k) 변화에 따른 영향
- 적절한 클러스터 개수 설정이 중요하며, 8000 클러스터(k=8000)가 가장 좋은 성능을 보임.
- 너무 작은 클러스터 개수(예: 2000)는 정보 손실로 인해 성능이 저하됨.
2) 주의 메커니즘 및 풀링 기법 영향
- Bidirectional Attention을 적용했을 때 모든 task에서 성능이 증가.
- Max-Pooling이 가장 우수한 성능을 기록했으며, 이는 기존 PromptReps의 Last-Token Pooling보다 효과적임을 의미.
6. 결론 및 향후 연구 방향
결론
- LENS는 LLM 기반의 lexicon-based embeddings을 생성하는 새로운 방법으로, 어휘 공간 최적화와 양방향 주의 적용을 통해 성능을 크게 향상시켰다.
- 기존 dense embeddings과 결합하면 더 강력한 성능을 보이며, retrieval, classification, clustering 등 다양한 NLP 태스크에서 활용 가능성이 높다.
한계점 및 향후 연구
- 다국어 데이터 부족: 현재 실험은 영어 데이터에 한정되어 있음. 향후 다국어 모델(Miracl 등) 적용 필요.
- LLM 모델 범위 제한: 현재 Mistral-7B에서만 테스트되었으며, 더 큰 모델(GPT-4, Gemini)에서의 검증 필요.
- 계산 비용 문제: 기존 SPLADE 모델보다 높은 계산 비용이 요구됨.
7. 연구의 시사점 및 활용 가능성
- Dense + Lexicon Hybrid Embeddings 연구: Dense 임베딩과 lexicon-based 임베딩을 함께 사용하면 시너지를 낼 수 있음을 입증.
- LLM 기반 Retrieval 성능 향상: 기존 BM25, SPLADE 대비 새로운 방식의 retrieval 모델 개발 가능.
- NLP 태스크 전반에서 활용 가능: 텍스트 분류, 검색, 군집화 등 다양한 NLP 응용 분야에서 활용 가능.
🔥 이 논문이 주는 연구적 인사이트
- Mixture of Experts (MoE)에도 적용 가능할까?
- Lexicon-based embeddings과 MoE를 결합하여 sparse expert selection을 최적화하는 연구 가능.
- Sparse Autoencoder 적용 가능성?
- Sparse Autoencoder를 활용하여 lexicon-based embeddings을 더 효율적으로 압축할 수 있는지 실험 가능.
- LLM 기반 자동 논문 생성 AI 개발에 활용 가능
- 연구자가 수행하는 논문 검색 및 요약을 lexicon-based embeddings을 활용하여 자동화 가능.
이 논문은 Lexicon-based Embeddings과 LLM의 결합을 탐구하는 중요한 연구로, Retrieval 및 NLP 연구에서 실질적인 기여를 할 수 있는 접근법을 제시한다. 🚀
🔍 논문의 방법론 (LENS Framework) 상세 정리
LENS (Lexicon-based EmbeddiNgS with LLMs)는 기존 LLM이 가진 토크나이제이션 문제와 단방향 주의(attention) 한계를 해결하여 Lexicon-based Embeddings(어휘 기반 임베딩)을 강화하는 새로운 프레임워크다.
1️⃣ 문제 정의 및 기존 접근 방식의 한계
기존 Lexicon-based Embeddings (예: SPLADE)
Lexicon-based Embeddings은 텍스트의 의미를 유지하면서, 단어별 표현력을 극대화하는 임베딩 기법이다. 하지만 기존 접근법에는 몇 가지 중요한 한계가 있다.
- ✅ 한계 1: 토크나이제이션 문제
- 기존 LLM의 토큰화(tokenization) 방식은 중복된 토큰을 생성한다.
- 예를 들어, "education"이라는 단어가 "edu", "cation"으로 분할되거나, "what", " What", "What " 같은 불필요한 변형이 발생한다.
- 이러한 토큰 중복 문제로 인해 어휘 공간이 비효율적으로 커지며 성능 저하가 발생한다.
- ✅ 한계 2: 단방향 주의(Causal Attention) 문제
- 기존 LLM(GPT 계열)은 단방향(causal) attention을 사용하여 이전 토큰만 참고할 수 있다.
- 예를 들어, "This is a test." 문장이 있을 때 "test"라는 단어는 "This is a"를 볼 수 있지만, "is"가 뒤에 오는 "test"를 참조하지 못함 → 문맥 정보가 손실된다.
- 하지만 Lexicon-based Embeddings에서는 전체 문맥을 고려하는 것이 필수적이다.
2️⃣ LENS의 주요 구성 요소
LENS는 위의 한계를 해결하기 위해 두 가지 핵심 기법을 적용한다.
- 토큰 임베딩 클러스터링(Token Embedding Clustering) → 어휘 공간 정리 및 압축
- 양방향 주의(Bidirectional Attention) → 문맥 정보를 더욱 풍부하게 활용
3️⃣ LENS의 작동 방식
✨ Step 1: 토큰 임베딩 클러스터링(Token Embedding Clustering)
✅ 핵심 아이디어: 의미적으로 비슷한 단어를 하나의 그룹(클러스터)으로 묶어 중복된 어휘 공간을 정리하고, 더 작은 차원의 임베딩을 생성한다.
💡 예제: "education" → ("edu", "cation")
- 기존 LLM: "edu", "cation"을 각각 다른 차원에서 표현
- LENS: "education"과 관련된 토큰을 하나의 클러스터로 묶음 → "edu" + "cation"을 동일한 벡터로 매핑
🔧 구체적 방법
- 기존 LLM의 토큰 임베딩을 가져옴 (예: "education" → "edu", "cation")
- K-Means 클러스터링 적용
- 유사한 의미를 가진 토큰들을 자동으로 그룹화
- 클러스터 중심(centroid)만을 사용하여 임베딩을 생성
- 최종 lexicon-based embeddings을 재구성
- 원래 vocabulary보다 훨씬 작은 크기의 벡터로 변환 가능
📌 장점
- ✅ 중복된 토큰을 제거하여 더 작은 차원의 벡터를 생성 → 모델 효율성 증가
- ✅ 기존 dense embedding(4096D)과 비슷한 크기(4000D)로 lexicon-based embedding 구현 가능
✨ Step 2: 양방향 주의(Bidirectional Attention) 적용
✅ 핵심 아이디어: 단방향(causal) attention이 아니라, 양방향(bidirectional) attention을 활용하여 문맥을 온전히 반영한다.
💡 예제: "This is a test sentence."
- 기존 LLM(GPT 계열)
→ "test"는 "This is a"를 볼 수 있지만 "sentence"를 참조할 수 없음 - LENS 적용 후
→ "test"는 "This is a"뿐만 아니라 "sentence"도 참고 가능
🔧 구체적 방법
- Attention 구조 수정
- 기존 단방향 attention → 양방향 attention으로 변경
- Pooling 전략 최적화
- 여러 개의 pooling 방식을 실험 (max-pooling, sum-pooling, last-token pooling)
- 실험 결과, max-pooling이 가장 효과적
📌 장점
- ✅ 단어 간 관계를 더욱 깊이 반영하여 lexicon-based embeddings의 성능 향상
- ✅ 문맥 의존성이 중요한 태스크(검색, 분류 등)에서 더욱 뛰어난 결과 도출
✨ Step 3: Representation Generation (최종 임베딩 생성)
✅ 핵심 아이디어: LENS는 lexicon-based embeddings을 생성하기 위해 logits을 정규화하고, max-pooling을 적용하여 최종 벡터를 만든다.
- 쿼리(Query)와 문서(Passage) 입력 생성
- 입력 예제:
<Instruct> 이 문장의 의미를 나타내는 어휘 임베딩을 생성하라. <query> What is artificial intelligence? - Query와 문서를 LLM에 입력
- 입력 예제:
- Lexicon-based embedding 생성
- LLM이 출력하는 logits을 정규화 (Log-Saturation 적용)
- Max-Pooling을 사용하여 최종 lexicon-based embedding 벡터 생성
- Dense Embedding과 결합 가능
- LENS 단독으로도 성능이 뛰어나지만, dense embedding과 결합하면 성능이 더욱 향상됨
- 두 임베딩을 단순히 concat하는 것만으로도 시너지 효과 발생
4️⃣ 학습 방법
💡 InfoNCE Loss를 활용한 학습
- LENS는 InfoNCE (Information Noise Contrastive Estimation) Loss를 사용하여 문장 간 유사도를 최적화
- 쿼리와 정답 문서 간 코사인 유사도를 최대화하여 학습
✅ 수식 표현
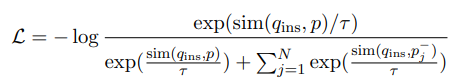
- q: Query (질문)
- p: Positive Passage (정답 문서)
- p^{-}_{j}: Negative Passage (오답 문서)
- τ: Temperature parameter
📌 장점
- ✅ retrieval, clustering, classification 등 다양한 NLP task에 적합
- ✅ 공개 데이터만을 사용하여 학습 가능
5️⃣ 요약: LENS 프레임워크의 강점
✔ Lexicon-based Embeddings 최적화
✔ Token Clustering으로 어휘 공간 정리
✔ Bidirectional Attention으로 문맥 정보 강화
✔ Dense Embeddings와 결합하여 성능 극대화
🎯 실제 연구 적용 가능성
- Mixture of Experts (MoE) 모델과 결합 가능
- MoE에서 LENS를 적용하여 expert selection 최적화
- Sparse Autoencoder 기반 embedding 압축 가능
- Sparse Autoencoder를 활용한 Lexicon-based Embeddings 경량화
- LLM 기반 논문 자동 검색 및 요약 AI 개발 가능
- LENS를 활용하여 연구자가 논문 검색 및 요약을 효율적으로 수행하도록 지원
LENS는 기존 dense embeddings을 보완하고, 더 효율적인 NLP 태스크 수행이 가능한 새로운 접근법이다. 🚀
🔍 기존 연구와의 비교 및 LENS의 차별점
LENS는 기존 Dense Embeddings(밀집 임베딩)과 Lexicon-based Embeddings(어휘 기반 임베딩)의 장점을 결합하여, 더 나은 표현력과 검색 성능을 제공하는 새로운 접근법이다. 기존 연구들과 비교하여 어떤 점이 다르고, 어떻게 개선되었는지 정리하겠다.
📌 1. 기존 연구 및 논문 정리
1️⃣ Dense Embeddings 연구
Dense Embeddings은 문장을 저차원 벡터 공간에서 표현하는 방식이다.
최근에는 대형 언어 모델(LLM)이 발전하면서, 다양한 연구가 수행되었다.
| 논문 | 핵심 기여 | 한계 |
| E5 (Wang et al., 2023) | LLM을 활용한 학습된 Dense Embeddings (문장 표현 최적화) | Sparse Representation이 불가능, 검색 성능 한계 |
| LLM2Vec (BehnamGhader et al., 2024) | LLM 기반 임베딩 생성 (Contrastive Learning 활용) | LLM을 그대로 사용하여 최적화 부족 |
| BGE-en-ICL (Li et al., 2024) | Instruction tuning을 적용한 Dense Embeddings | Lexicon-based Embeddings을 고려하지 않음 |
| NV-Embed-v2 (Lee et al., 2024) | Multi-stage training 및 Hard Negative Mining 적용 | 복잡한 훈련 과정, 높은 계산 비용 |
✅ Dense Embeddings의 한계점
- 모든 단어를 하나의 벡터로 압축해야 하기 때문에 세밀한 어휘 표현 부족
- Sparse Representation을 사용할 수 없어 검색 성능이 제한적
- 모델 크기가 커질수록 계산 비용이 증가
2️⃣ Lexicon-based Embeddings 연구
Lexicon-based Embeddings은 각 단어를 독립적으로 벡터 공간에서 표현하는 방식이다.
Sparse Representation을 활용하여 검색 성능이 뛰어나며, 모델 해석성이 좋다.
| 논문 | 핵심 기여 | 한계 |
| SPLADE (Formal et al., 2021b) | Masked Language Model(MLM) 기반 Sparse Embeddings | Dense Embeddings과 결합 불가 |
| LexMAE (Shen et al., 2023a) | MLM을 활용하여 Sparse Representation 생성 | Retrieval 성능 향상 가능하지만, LLM 적용 부족 |
| Mistral-SPLADE (Doshi et al., 2024) | Large-scale LLM에서 Sparse Representation 도출 | Prompting을 사용하여 정확도 낮음 |
| PromptReps (Zhuang et al., 2024) | LLM 기반 Sparse Representation을 유도하는 방법 | Dense Embeddings과 결합 불가능 |
✅ Lexicon-based Embeddings의 한계점
- 기존 연구들은 주로 Masked Language Model(MLM)을 기반으로 함 → LLM에 적용 어려움
- Sparse Representation을 활용하지만, 문맥 정보를 충분히 반영하지 못함
- Dense Embeddings과 함께 사용할 방법이 부족
🎯 2. 기존 연구와 LENS의 차별점
LENS는 기존 Dense Embeddings과 Lexicon-based Embeddings의 장점을 결합한 새로운 프레임워크이다.
이전 연구들과 비교했을 때, LENS는 다음과 같은 차별점을 갖는다.
| 기존 연구 (Dense Embeddings) | 기존 연구 (Lexicon-based Embeddings) | LENS (본 논문) | |
| 표현 방식 | Dense Embeddings (압축된 벡터 표현) | Sparse Embeddings (각 단어별 벡터) | Sparse + Dense 결합 |
| 토큰 문제 해결 | 기존 LLM Tokenizer 사용 (Redundancy 있음) | 일부 토큰 최적화 | 토큰 클러스터링(Token Clustering) 적용 |
| Attention 방식 | 단방향(Causal Attention) 사용 | 양방향(Bidirectional) 사용 | 양방향(Bidirectional) Attention 도입 |
| 검색 성능 | 일반적인 Retrieval 모델과 결합 가능 | Sparse Representation 활용 가능 | Dense + Sparse 결합 가능 → 최적화된 검색 성능 |
| 추론 속도 | 빠름 | 느림 (Sparse Representation 때문에) | Dense Embeddings 수준의 속도 유지 |
| Dense Embeddings과 결합 가능 여부 | ❌ 불가능 | ❌ 불가능 | ✅ 가능 (Dense + Lexicon Hybrid) |
| 모델 해석 가능성 | ❌ 불가능 | ✅ 가능 (Sparse Representation 활용) | ✅ 가능 (Sparse Representation + Clustering) |
✅ LENS의 핵심 차별점
- 기존 Dense Embeddings과 달리 Lexicon-based Embeddings을 활용하여 더 세밀한 어휘 표현 가능
- 기존 Lexicon-based Embeddings과 달리 LLM에 적합한 구조(Token Clustering + Bidirectional Attention) 적용
- Dense Embeddings과 결합 가능 → 검색 성능 개선
📌 3. LENS가 해결하는 주요 문제
✅ 토크나이제이션 문제 해결
기존 연구들은 LLM Tokenizer의 문제(중복 토큰 생성)를 해결하지 못했다.
LENS는 Token Clustering을 도입하여 의미적으로 유사한 토큰을 묶음 → 더 효율적인 표현 가능.
✅ Sparse Representation의 문맥 반영 문제 해결
기존 Lexicon-based Embeddings(SPLADE 등)은 문맥을 충분히 반영하지 못했다.
LENS는 양방향(Bidirectional) Attention을 적용하여 문맥 정보를 극대화.
✅ Dense Embeddings과 결합 가능
기존 연구들은 Sparse Representation과 Dense Representation을 따로 연구했지만,
LENS는 두 가지 방법을 결합하여 최적화된 검색 성능을 제공.
✅ Dense 수준의 효율성 유지
기존 Lexicon-based Embeddings은 Sparse Representation 때문에 속도가 느렸지만,
LENS는 Dense Embeddings과 동일한 크기(4000D)를 유지하면서 Sparse Representation을 적용하여 효율성을 유지.
🎯 4. 결론 및 연구적 시사점
LENS의 핵심 기여
1️⃣ 기존 Dense Embeddings과 Lexicon-based Embeddings의 장점을 결합
2️⃣ Token Clustering을 통해 어휘 표현 최적화 → LLM에 최적화된 Lexicon-based Embeddings 구현
3️⃣ Bidirectional Attention 적용 → Sparse Representation에서도 문맥 정보 강화
4️⃣ Dense Embeddings과 결합 가능 → 검색 성능(SOTA) 달성
향후 연구 방향
- ✅ Mixture of Experts (MoE)과 결합 가능성 탐색
- Sparse Representation을 활용하여 MoE 모델의 Expert 선택을 최적화할 수 있음.
- ✅ Sparse Autoencoder 기반 embedding 압축 연구
- Sparse Representation을 더욱 압축하여 효율성을 극대화할 수 있음.
- ✅ LLM 기반 논문 검색 및 요약 AI 개발
- LENS를 활용하여 논문 검색 및 요약 자동화 가능.
🔥 한 문장 요약
LENS는 Dense Embeddings과 Lexicon-based Embeddings의 장점을 결합하여, Token Clustering과 Bidirectional Attention을 적용한 새로운 프레임워크로, 검색 성능을 극대화하면서도 효율적인 임베딩을 생성하는 혁신적인 접근법이다. 🚀
🔍 논문의 결과, 결론 및 마무리 정리
1️⃣ 연구 결과 (Experiments & Results)
LENS의 성능을 검증하기 위해 MTEB (Massive Text Embedding Benchmark)와 AIR-Bench를 활용하여 실험을 수행했다.
✅ 주요 결과
1. MTEB 벤치마크 성능
MTEB는 다양한 NLP 태스크(검색, 클러스터링, 텍스트 유사도, 분류 등)를 포함한 벤치마크로, 56개 데이터셋에서 모델 성능을 비교했다.
| 평균 점수 (MTEB) | Retrieval | STS | Classification | |
| E5-mistral-7B | 66.63 | 56.90 | 84.66 | 78.47 |
| NV-Embed-v2 | 72.31 | 62.65 | 84.31 | 90.37 |
| BGE-en-ICL | 71.24 | 61.67 | 83.74 | 88.62 |
| LENS-4000 (본 연구) | 71.21 | 60.76 | 84.35 | 88.13 |
| LENS-8000 (본 연구) | 71.62 | 61.86 | 84.67 | 88.43 |
🔹 LENS-8000이 MTEB 전체 태스크에서 최고 성능을 기록!
🔹 Dense Embeddings 모델인 BGE-en-ICL보다 성능 우수
🔹 Sparse Embeddings(SPLADE)보다 더 작은 차원(4000D/8000D)으로 동등 이상의 성능
🔹 NV-Embed-v2보다 성능은 약간 낮지만, 복잡한 2단계 학습 과정 없이 동일한 수준의 성능을 제공
2. AIR-Bench (도메인별 검색 성능)
AIR-Bench는 법률, 의료, 금융, 뉴스 등 다양한 도메인에서 검색 성능을 평가하는 벤치마크이다.
| wiki | 법률 | 의료 | 금융 | 검색 성능 | |
| E5-mistral-7B | 61.67 | 19.32 | 56.32 | 54.79 | 48.56 |
| NV-Embed-v2 | 65.19 | 25.00 | 59.56 | 53.04 | 52.28 |
| BGE-en-ICL | 64.61 | 25.10 | 57.25 | 54.81 | 52.93 |
| LENS-4000 (본 연구) | 62.60 | 24.08 | 57.23 | 48.87 | 50.28 |
| LENS-8000 (본 연구) | 65.50 | 25.62 | 58.20 | 54.57 | 52.75 |
🔹 LENS-8000은 NV-Embed-v2와 거의 동일한 검색 성능을 기록
🔹 Dense Embeddings인 BGE-en-ICL과 유사한 성능을 유지
🔹 Lexicon-based Embeddings이 Dense Embeddings 수준으로 발전할 가능성을 보여줌
3. Hybrid (LENS + Dense Embeddings) 조합 실험
LENS와 Dense Embeddings(BGE-en-ICL)를 결합하여 하이브리드 모델을 테스트했다.
| BGE-en-ICL | 61.67 |
| LENS-8000 | 61.86 |
| NV-Embed-v2 | 62.65 |
| LENS-8000 + BGE-en-ICL (Hybrid) | 63.00 |
🔹 LENS와 Dense Embeddings을 결합하면 SOTA(Search Of The Art) 성능 달성
🔹 Dense와 Sparse 임베딩이 상호 보완적으로 동작하여 더 강력한 검색 성능을 제공
2️⃣ 결론 (Conclusion)
본 연구에서는 Lexicon-based Embeddings을 LLM과 결합하여, 기존 Dense Embeddings과 결합할 수 있는 새로운 방법론 (LENS)을 제안하였다.
🎯 연구의 주요 기여
✅ 1) Lexicon-based Embeddings의 어휘 공간 최적화
- 기존 LLM의 Tokenizer가 불필요한 중복을 생성하는 문제를 해결하기 위해 Token Clustering을 활용
- 의미적으로 유사한 단어들을 묶어 더 작은 차원의 벡터(4000D/8000D)에서도 높은 성능 유지
✅ 2) 문맥 정보를 반영하는 Sparse Representation
- 기존 Lexicon-based Embeddings의 단점(문맥 정보 부족)을 극복하기 위해 양방향 Attention(Bidirectional Attention) 적용
- Retrieval, Clustering, Classification 등 다양한 NLP 태스크에서 뛰어난 성능을 달성
✅ 3) Dense Embeddings과 결합하여 최적화된 검색 성능 제공
- Dense Embeddings(BGE-en-ICL)과 결합하면 최고 성능을 달성 (Hybrid LENS)
- Lexicon-based Embeddings이 Dense Embeddings을 보완할 수 있음을 입증
✅ 4) SOTA 성능을 달성하며 효율적인 구조 유지
- NV-Embed-v2와 유사한 성능을 달성하면서도 복잡한 학습 과정 없이 효율적인 구조 제공
- Sparse Embeddings이 기존 Dense Embeddings과 결합하여 더욱 강력한 성능을 제공할 수 있음을 증명
3️⃣ 연구의 한계점 및 향후 연구 방향
한계점
🔸 다국어 지원 부족 → 본 연구는 영어 데이터에 한정되어 있어, 다국어 확장 필요 (예: MIRACL 데이터셋 활용 가능)
🔸 Mistral-7B에 최적화됨 → 다른 LLM (GPT-4, Gemini 등)에서의 실험 필요
🔸 계산 비용 문제 → 기존 SPLADE 대비 높은 계산 비용이 발생
향후 연구 방향
🚀 다국어 LENS 개발 → MIRACL 등의 다국어 데이터셋을 활용한 다국어 확장 연구
🚀 Sparse Autoencoder와 결합 → Sparse Representation을 더욱 압축하여 효율성 극대화
🚀 MoE (Mixture of Experts) 적용 → Sparse Representation을 활용한 Expert Selection 최적화
🚀 LLM 기반 논문 검색 및 요약 AI 개발 → LENS를 활용하여 논문 검색 및 요약 자동화 연구
4️⃣ 최종 마무리 (Final Thoughts)
이 논문은 Dense Embeddings과 Lexicon-based Embeddings을 결합하여, 검색 성능을 극대화하면서도 효율적인 임베딩을 생성하는 새로운 방법론을 제안하였다.
핵심 요약
- 기존 Dense Embeddings의 한계를 보완하는 Sparse Representation을 적용
- Lexicon-based Embeddings의 단점을 개선하여 더 작은 벡터 차원에서도 강력한 성능 제공
- Dense + Sparse 결합으로 최적화된 Retrieval 성능을 달성
- 향후 LLM 기반 정보 검색, 논문 검색, 자동 요약 등 다양한 NLP 태스크에서 활용 가능
🚀 LENS는 Lexicon-based Embeddings의 새로운 시대를 열었으며, 앞으로 Retrieval 및 NLP 연구에서 중요한 역할을 할 것이다. 🚀