https://arxiv.org/abs/2405.19333
Multi-Modal Generative Embedding Model
Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To exp
arxiv.org
이 논문은 Multi-Modal이기도 하고, 이미지는 일단 나중에 생각할 거기 때문에 적당히 보고 넘어가겠습니다...
이 논문도 GRIT의 영향을 받아 나온 논문 같습니다.
Real work에 GRIT이 있네요
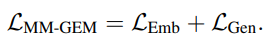
로스도 GRIT와 동일하게 진행됩니다.
이 정도만 보고 나머지는 대충...
| 🔹 연구 배경 | - 기존 멀티모달 모델은 임베딩(Embedding) 모델과 생성(Generative) 모델로 나뉨. - 임베딩 모델(CLIP, OpenCLIP 등)은 이미지와 텍스트를 같은 공간에 맵핑하지만, 생성 능력이 없음. - 생성 모델(Flamingo, FROMAGe 등)은 이미지에서 텍스트를 생성할 수 있지만, 검색 성능이 약함. - 대부분의 연구는 이 두 가지를 분리된 경로(텍스트 인코더와 디코더)로 학습, 하나의 모델에서 동시 수행이 어려움. |
| 🔹 연구 목표 | “임베딩과 생성을 하나의 LLM에서 동시에 수행할 수 있는 모델 개발” ✅ 검색(Embedding)과 생성(Generation) 목표가 충돌 없이 공존할 수 있는지 탐색 ✅ Fine-Grained 정보(객체 수준)를 활용하여 기존 모델보다 더 세밀한 검색 및 캡셔닝 성능 제공 |
| 🔹 주요 기여 (Novelty) | 1. 임베딩과 생성 목표를 통합한 최초의 LLM 기반 멀티모달 모델 - 기존 CLIP, BLIP, CoCa 등의 모델은 텍스트 인코더와 디코더가 분리, 또는 단순 연결 구조. - MM-GEM은 텍스트 임베딩과 생성 목표를 하나의 LLM 경로에서 수행하도록 설계. 2. PoolAggregator를 활용한 Fine-Grained 학습 가능 - 기존 CLIP 기반 모델은 전체 이미지(Global feature)만 활용, 특정 객체에 대한 이해 부족. - MM-GEM은 이미지 특징 맵을 활용하여 세부적인 영역 정보를 학습, 객체 단위 검색 및 캡셔닝 가능. 3. 다단계 학습(Multi-Stage Training) 도입으로 점진적 최적화 - Stage 1: 전역 이미지-텍스트 정렬 학습 (기존 CLIP 방식과 유사). - Stage 2: 객체 중심의 Fine-Grained 학습 추가 (객체 검색, 영역 캡셔닝 등 강화). |
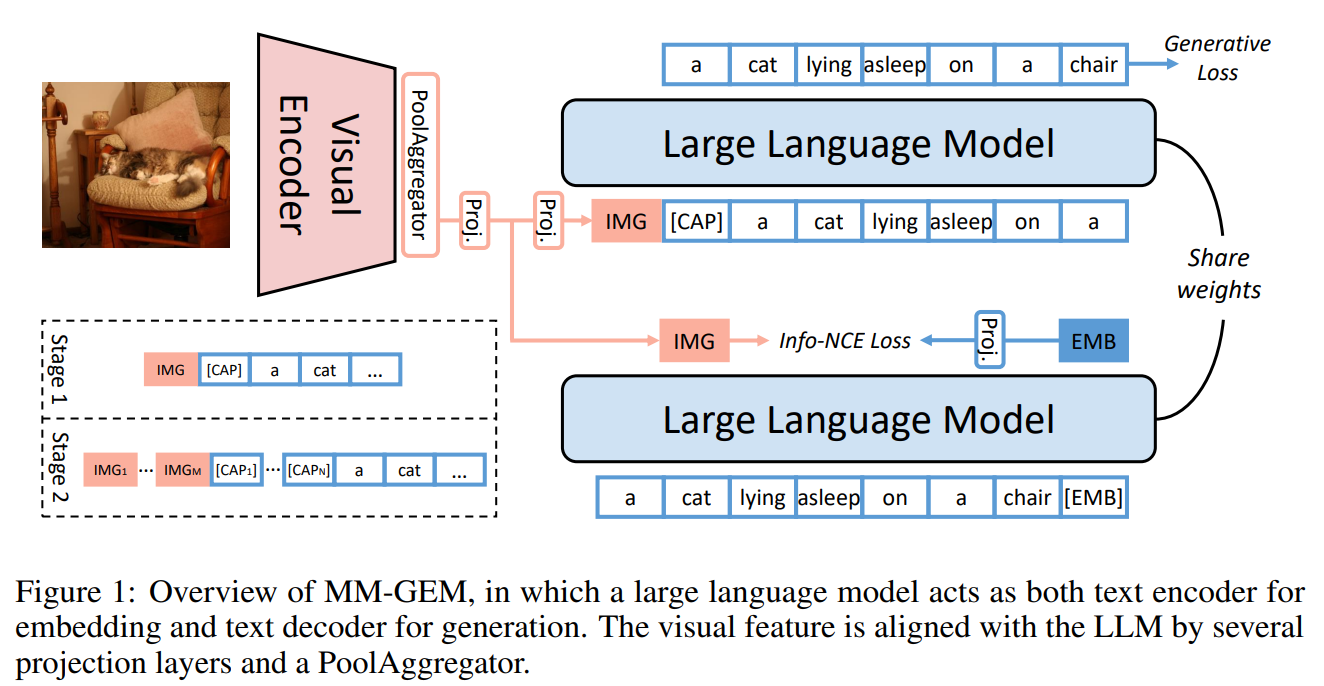
| 🔹 모델 구조 | ✅ 하나의 LLM에서 임베딩(검색)과 생성(캡셔닝) 수행 ✅ PoolAggregator 사용: 이미지의 특정 영역(Region) 정보를 추출하여 활용 가능 ✅ Projection Layer 활용: 이미지 특징을 LLM에 맞게 변환 |
| 🔹 학습 방법 | 1) 임베딩 학습 (Info-NCE Loss) - L_emb = L_v2t + L_t2v (이미지-텍스트 정렬을 위한 contrastive loss 적용) 2) 생성 학습 (Auto-regressive Loss) - `L_gen = - log P(f(x(i)) |
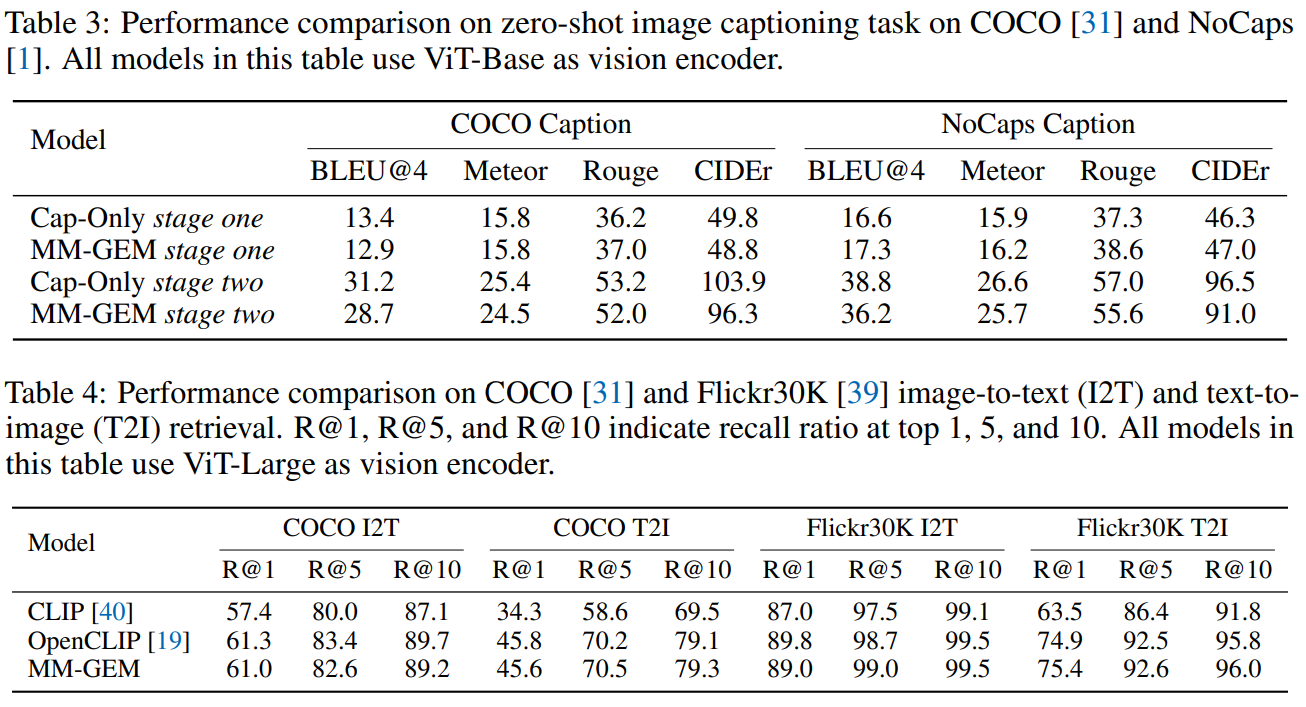
| 🔹 실험 결과 요약 | ✅ 이미지-텍스트 검색 성능 (COCO, Flickr30K 벤치마크) - OpenCLIP과 유사한 성능을 유지하며, 기존 CLIP보다 Recall@1 성능 5% 향상. - 특히 긴 문장(Long-form text)에 대한 검색 성능이 크게 향상됨. ✅ Fine-Grained 검색 및 캡셔닝 가능 (L-DCI 벤치마크) - CLIP은 전역(Global) 정보만 학습, 특정 객체 검색 불가. - MM-GEM은 PoolAggregator를 활용하여 세부 객체 검색 및 캡셔닝 가능. ✅ 이미지 캡셔닝 성능 (COCO, NoCaps 벤치마크) - ClipCap과 유사한 수준의 캡셔닝 성능, Flamingo보다 NoCaps에서 높은 성능 기록. |
| 🔹 기존 연구와의 비교 | 1️⃣ CLIP (2021) vs. MM-GEM - CLIP: 검색 강력하지만 생성 불가능, 전역 이미지 정보만 활용. - MM-GEM: 검색+생성 동시 수행, 세부 객체(Region)까지 활용 가능. 2️⃣ BLIP (2022) vs. MM-GEM - BLIP: 인코더와 디코더가 분리됨. - MM-GEM: 하나의 LLM에서 통합적으로 학습. 3️⃣ Flamingo (2022) vs. MM-GEM - Flamingo: 생성 강력하지만 검색 성능 약함. - MM-GEM: 검색 성능 유지하면서 생성 능력 추가. |
| 🔹 연구의 한계 | ⚠ 1. 학습 데이터 품질 문제 - 웹 크롤링 데이터(LAION-2B, COYO-700M 등) 활용 → 텍스트 품질이 균일하지 않음. - 생성 및 검색 성능을 더욱 향상하려면 더 정제된 데이터 필요. ⚠ 2. Fine-Grained 학습을 초기에 적용하지 않음 - Stage 1에서는 전역(Global) 학습만 수행하고, Stage 2에서 Fine-Grained 학습 진행. - 초기부터 Fine-Grained 학습을 적용하면 성능이 더 향상될 가능성 있음. ⚠ 3. 비디오 및 3D 데이터 적용 부족 - 현재는 이미지-텍스트 모델, 비디오(Video) 및 3D 데이터에 대한 연구 필요. |
| 🔹 향후 연구 방향 | ✅ 1. 더 정교한 데이터 활용 - 고품질 텍스트-이미지 데이터셋을 구축하여 성능 향상 연구 필요. ✅ 2. 멀티모달 LLM 확장 - 비디오(Video) 및 3D 데이터에서도 MM-GEM 접근법 적용 가능성 연구. ✅ 3. 모달리티 확장 (Audio, 3D 등) - 오디오(Audio) 및 3D 데이터를 포함하는 확장된 MM-GEM 모델 개발 가능. |
| 🔹 결론 및 시사점 | - MM-GEM은 임베딩과 생성을 하나의 LLM에서 수행하는 최초의 멀티모달 모델. - CLIP과 동등한 검색 성능을 유지하면서도, Fine-Grained 정보 활용 및 생성 능력 추가. - 멀티모달 AI 연구의 새로운 방향을 제시하며, 향후 비디오, 3D, 오디오 데이터로 확장할 가능성 큼. |


논문 요약: Multi-Modal Generative Embedding Model (MM-GEM)
1. 연구 배경 및 문제 정의
최근 멀티모달 학습(Multi-Modal Learning)에서는 표현 학습의 통합이 주요 트렌드이다. 일반적으로 멀티모달 모델은 두 가지 접근 방식으로 구분된다:
- 임베딩(Embedding) 모델: 각 모달리티(예: 이미지, 텍스트)를 공통된 표현 공간으로 매핑하여 효율적인 검색 및 분류를 수행함.
- 생성(Generative) 모델: 이미지 및 텍스트 간 관계를 학습하여 이미지 캡셔닝(Image Captioning), 지시 따르기(Instruction Following), In-context Learning 등을 수행함.
기존 연구에서는 위 두 접근 방식을 분리된 언어 모델 구조로 처리하는 경우가 많았다. 하지만 이는 모달리티 간 표현 공유의 최적화를 방해하는 요소로 작용한다.
기존 접근 방식의 한계
- 텍스트 모달리티의 분리: 기존의 연구는 보통 생성 모델이 Auto-regressive Text Decoder를 사용하고, 임베딩 모델이 Text Encoder를 사용하는 등 서로 다른 구조를 유지함.
- 멀티모달 모델의 비효율성: 임베딩 모델과 생성 모델을 별개로 학습하면 전이 학습(Transfer Learning)의 이점이 줄어들고, 계산량이 증가함.
- 통합 모델 시도 부족: 일부 연구는 encoder와 decoder의 일부를 공유하는 방식(BLIP, CoCa, FROMAGe 등)으로 해결하려 했지만, 완전한 통합을 이루지는 못함.
2. MM-GEM: 제안된 모델
이 연구에서는 임베딩과 생성 모델을 하나의 모델로 통합한 Multi-Modal Generative Embedding Model (MM-GEM)을 제안함. 주요 특징은 다음과 같다:
1) 텍스트 임베딩과 생성 목표를 하나의 LLM으로 학습
- 임베딩(Embedding): 이미지 특징을 마지막 토큰의 문장 임베딩(sentence embedding) 과 정렬하여 학습.
- 생성(Generation): 이미지 특징을 언어 모델의 단어 임베딩(word embedding)과 결합하여 캡셔닝 수행.
2) PoolAggregator 활용
- 기존의 CLIP과 같은 모델들은 전역 특징(global feature)을 사용하여 정보를 단순화하지만, 이는 세부적인 이미지 정보 학습에 한계가 있음.
- MM-GEM은 PoolAggregator를 도입하여 이미지의 특징 맵(feature map)을 직접 활용하여 세밀한 임베딩 및 생성을 가능하게 함.
3) 다단계 학습(Multi-Stage Training)
- Stage 1: 기본적인 텍스트-이미지 임베딩과 생성 능력을 학습함.
- Stage 2: 더 세밀한 이미지-텍스트 매핑 및 세부적인 이미지 캡셔닝 능력을 개선함.
3. 실험 및 성능 평가
1) 벤치마크 성능 비교
MM-GEM은 다양한 멀티모달 태스크에서 기존 최첨단 모델들과 비교하여 성능을 평가함. 주요 결과는 다음과 같다:
1. 이미지-텍스트 검색(Image-Text Retrieval)
- OpenCLIP과 비슷한 수준의 성능을 보이며, 기존 CLIP보다 Recall@1 성능이 5% 향상됨.
- Flickr30K 및 COCO 데이터셋에서 높은 성능을 기록하며, 특히 긴 문장(long-form text)에 대한 검색 성능이 크게 향상됨.
2. 이미지 캡셔닝(Image Captioning)
- COCO 및 NoCaps 벤치마크에서 ClipCap, Flamingo 모델과 비교하여 높은 성능을 기록.
- Stage 2 학습을 통해 세부적인 영역(region-level) 캡셔닝 성능이 크게 향상됨.
3. 이미지 분류(Image Classification)
- 다양한 벤치마크 데이터셋(ELEVATER)에서 기존 CLIP과 비교하여 세부적인 이미지 분류 성능 향상을 확인함.
2) Fine-Grained 학습 능력 검증
1. Fine-Grained Image Captioning
- 일반적인 이미지 캡셔닝 모델은 이미지 전체를 설명하지만, MM-GEM은 특정 부분을 인식하여 해당 영역(region)만 설명하는 능력을 보유함.
- Visual Genome의 Dense Caption 데이터를 추가 학습하여 세부적인 객체 설명 가능.
2. Fine-Grained Image-Text Retrieval
- 일반적인 CLIP 기반 모델들은 전체 이미지를 기반으로 검색하지만, MM-GEM은 텍스트와 이미지 내 특정 부분의 유사도를 평가하는 기능을 추가함.
- 이를 통해 세부적인 이미지-텍스트 매핑이 가능해짐.
4. 결론 및 한계점
1) 결론
- MM-GEM은 기존의 임베딩 및 생성 모델을 하나로 통합하여 모달리티 간의 표현 공유를 극대화함.
- 기존 CLIP과 유사한 임베딩 성능을 유지하면서도, 이미지 캡셔닝 및 세부적인 텍스트 이해 성능을 향상시킴.
- 특히 PoolAggregator와 다단계 학습 전략을 도입하여 Fine-Grained 태스크에서도 높은 성능을 보임.
2) 한계점 및 향후 연구 방향
- 학습 데이터 품질 문제: Pre-training 데이터가 노이즈가 많고 텍스트 품질이 낮아, 더욱 정교한 데이터 필터링이 필요함.
- Fine-Grained 성능 향상을 위한 추가 데이터 필요: Stage 1에서부터 더 많은 세부적인 이미지-텍스트 매핑 데이터를 학습하면 초기부터 Fine-Grained 성능이 강화될 가능성이 있음.
- LLM 활용 연구: MM-GEM이 LLM을 활용한 모델이므로, 이를 다른 멀티모달 태스크(예: Visual Question Answering, Generative Reasoning)로 확장하는 연구가 필요함.
5. 연구의 시사점
- MM-GEM의 연구는 하나의 모델로 멀티모달 태스크를 해결하는 방향으로 나아가는 중요한 흐름을 반영함.
- Vision-Language 모델을 연구하는 데 있어 임베딩과 생성 태스크를 동시에 고려한 최적화 전략이 필요함.
- 향후, 더 강력한 언어 모델과 결합하거나, 3D 비전 및 비디오 데이터로 확장하면 더욱 강력한 멀티모달 시스템이 가능할 것으로 보임.
이 논문은 NLP & Vision 통합 연구를 진행하는 데 있어 중요한 통찰을 제공하며, 향후 MM-GEM을 기반으로 한 고성능 멀티모달 AI 연구가 활발히 이루어질 것으로 기대됨.
관련 연구 및 MM-GEM의 기여점 분석
1. 관련 연구 정리
(1) 멀티모달 학습 및 비전-언어 모델
① 임베딩(Embedding) 기반 모델
- CLIP (Radford et al., 2021)
- OpenAI에서 제안한 모델로, 이미지-텍스트 쌍을 대규모로 학습하여 강력한 Zero-shot 학습 능력을 보유.
- 이중 인코더 구조(Dual-Encoder)를 사용하여 이미지와 텍스트를 각각 인코딩 후 동일한 표현 공간에 매핑.
- 하지만 생성 능력이 없으며, 세부적인 영역 단위 표현이 불가능.
- OpenCLIP (Ilharco et al., 2021)
- CLIP의 오픈소스 버전으로, 더 다양한 데이터셋과 학습 설정을 지원.
- 성능 향상을 위해 다양한 백본(ResNet, ViT 등)과 최적화 기법을 적용.
- BLIP (Li et al., 2022)
- CLIP과 유사한 멀티모달 학습을 수행하지만, 텍스트 인코더와 디코더를 함께 활용하여 생성 및 임베딩을 동시에 가능하게 함.
- 그러나 텍스트 인코더와 디코더의 경로가 다르므로, 완전한 통합이 이루어지지는 않음.
② 생성(Generative) 기반 모델
- Flamingo (Alayrac et al., 2022)
- CLIP과 같은 contrastive learning 기반의 이미지 표현 학습을 사용하지만, LLM과 연결하여 이미지-텍스트 생성 능력 강화.
- 그러나 이미지와 언어 모델을 강하게 결합하지 않아, 완전한 멀티모달 통합이 이루어지지는 않음.
- MiniGPT-4 (Zhu et al., 2023)
- LLM을 활용하여 이미지-텍스트 생성 및 질의응답(Q&A)을 수행하는 모델.
- CLIP의 이미지 표현을 언어 모델의 입력으로 변환하는 Mapping Network를 활용하지만, 여전히 임베딩 및 검색 능력은 부족.
- FROMAGe (Koh et al., 2023)
- CLIP 기반의 이미지 표현을 기존의 LLM에 입력 및 출력으로 연결하는 방식.
- 하지만, 비전과 언어 모달리티가 완전히 통합되지 않아 별도로 학습하지 않으면 성능이 낮음.
③ 임베딩과 생성을 동시에 다룬 연구
- CoCa (Yu et al., 2022)
- 텍스트 디코더를 Uni-modal과 Multi-modal 컴포넌트로 분리하여, 생성과 검색 모두 수행할 수 있도록 설계됨.
- 그러나 이는 디코더 내에서 경로를 다르게 설정하는 방식이므로, 완전한 통합은 아님.
- GRIT (Muennighoff et al., 2024)
- 텍스트만을 사용하는 NLP 모델에서 생성과 임베딩을 동시에 수행하는 모델.
- NLP에서는 적용되었지만, 비전-언어 멀티모달 모델에서는 이러한 접근이 부족.
2. MM-GEM이 발전시킨 내용 및 기존 연구와의 차이점
MM-GEM은 기존 연구들이 가졌던 모달리티 간 분리 문제를 해결하고, 임베딩과 생성 목표를 완전히 통합하는 새로운 접근법을 제시함.
(1) 기존 연구와의 차별점
| 연구 | 방법 | 한계점 | MM-GEM의 발전 |
| CLIP (2021) | 이중 인코더 기반 텍스트-이미지 임베딩 | 생성 불가능, 글로벌 이미지 표현만 사용 | 임베딩과 생성 모두 수행 가능, Fine-Grained 정보까지 활용 |
| BLIP (2022) | 공유된 텍스트 인코더+디코더 | 텍스트 인코더와 디코더 경로 분리 | 하나의 LLM을 활용한 통합 구조로 개선 |
| Flamingo (2022) | CLIP 기반 생성 모델 | 임베딩 성능이 낮음, 세부 정보 부족 | 임베딩과 생성 성능을 동시에 최적화 |
| FROMAGe (2023) | CLIP과 LLM 연결 | 비전-텍스트 공동 학습 부족 | 공동 학습을 통해 성능 향상 |
| CoCa (2022) | Uni-modal과 Multi-modal 분리 | 디코더에서 다른 경로 설정 | 완전히 동일한 경로를 활용하여 생성과 임베딩을 수행 |
| GRIT (2024) | NLP에서 임베딩-생성 통합 | 비전-언어 모델에 적용 부족 | 비전-언어 모델에서도 동일한 접근을 적용 |
(2) MM-GEM의 핵심 기여점
1. 멀티모달 통합: 하나의 모델로 임베딩과 생성 수행
- 기존 연구들은 텍스트 인코더와 디코더를 별도로 유지하거나, CLIP과 LLM을 단순히 연결하는 방식이었음.
- MM-GEM은 LLM을 하나의 통합된 경로에서 임베딩과 생성 모두 수행하도록 학습하여 완전한 멀티모달 통합을 이룸.
2. PoolAggregator를 통한 Fine-Grained 표현 학습
- 기존 CLIP 기반 모델들은 이미지의 전역 특징(global feature)만 활용하여 세부적인 객체 정보를 학습하지 못함.
- MM-GEM은 PoolAggregator를 활용하여 세부적인 이미지 영역 정보까지 학습하여, 더 정밀한 검색 및 캡셔닝 가능.
3. 다단계 학습(Multi-Stage Training)으로 세밀한 캡셔닝 및 검색 성능 향상
- 기존 연구에서는 일반적인 이미지-텍스트 매칭 데이터만을 활용하여, 세부적인 정보 학습이 부족했음.
- MM-GEM은 Stage 1에서 기본적인 학습을 수행한 후, Stage 2에서 Fine-Grained 데이터를 추가 학습하여 세부적인 정보 인식을 가능하게 함.
4. Advanced Text Model을 통한 긴 문장 검색 성능 향상
- 기존 CLIP 계열 모델들은 비교적 짧은 문장과의 매칭이 강했지만, 긴 문장(Long-form text)과의 매칭 성능이 낮음.
- MM-GEM은 LLM을 활용하여 긴 문장을 포함한 복잡한 텍스트 검색 성능을 개선.
3. 결론
MM-GEM은 임베딩과 생성 모델을 통합하여 멀티모달 학습의 효율성을 극대화한 새로운 접근법을 제안함. 기존 연구들과 비교했을 때:
- 임베딩과 생성 능력을 하나의 LLM에서 수행하도록 최적화하여 완전한 통합을 달성함.
- Fine-Grained 학습을 강화하여 세부적인 이미지-텍스트 매핑 성능을 개선.
- 긴 문장과의 검색 성능을 향상시켜 더 복잡한 질의에도 대응 가능.
향후 연구 방향으로는 더 다양한 데이터셋을 활용한 고도화, 3D 비전 및 비디오 데이터 확장, 멀티모달 LLM과의 결합 등이 제시될 수 있음.
MM-GEM 방법론 상세 분석
MM-GEM(Multi-Modal Generative Embedding Model)은 기존의 멀티모달 학습 방식에서 임베딩(Embedding)과 생성(Generation)을 하나의 모델에서 수행할 수 있도록 통합한 접근법이다. 이를 위해 다음과 같은 핵심 방법론을 도입했다.
1. MM-GEM의 핵심 개념: 임베딩과 생성 목표의 통합
기존 멀티모달 모델들은 주로 두 가지 방식으로 구성되었다.
- 임베딩 모델: 이미지와 텍스트를 공통된 표현 공간에 투영하여 검색이나 분류에 사용 (예: CLIP).
- 생성 모델: 이미지에서 텍스트를 생성하거나, 텍스트에서 이미지를 생성하는 방식 (예: Flamingo, BLIP).
이 두 개념을 하나의 LLM에서 통합하는 것이 MM-GEM의 목표이다.
✅ 해결해야 할 주요 문제
- 두 학습 목표의 충돌 가능성
- 생성 모델은 오토회귀(Auto-regressive) 방식으로 다음 단어를 예측하는 방식으로 학습됨.
- 반면, 임베딩 모델은 정보 간의 정렬(Alignment)과 유사도 학습을 수행하는 방식으로 최적화됨.
- 따라서, 하나의 언어 모델에서 이 두 가지 목표를 동시에 달성할 수 있는지 검증이 필요했다.
- 임베딩 모델의 글로벌 표현 한계
- 기존 임베딩 모델(CLIP 등)은 전체 이미지에서 하나의 전역(Global) 특징만 학습하지만, 이는 세부적인 지역 정보를 다루는 데 한계가 있다.
- 예를 들어, “강아지가 있는 이미지”를 검색할 때, 강아지가 사진의 작은 부분만 차지하고 있으면 검색이 어려움.
- 노이즈가 포함된 데이터 문제
- 임베딩 학습에 사용되는 이미지-텍스트 쌍(예: 웹에서 크롤링한 데이터)은 텍스트가 비정형적이거나 품질이 낮을 가능성이 높음.
- 따라서 생성 모델로도 활용할 수 있도록 학습 데이터의 품질을 개선하는 전략이 필요함.
2. MM-GEM의 주요 구성 요소
(1) 텍스트 임베딩과 생성 목표를 하나의 LLM으로 통합
MM-GEM에서는 하나의 LLM을 사용하여 텍스트 임베딩과 생성을 동시에 수행한다. 이를 위해 각 모달리티(이미지, 텍스트)의 특징을 적절하게 변환하는 Projection Layer를 설계했다.
- 이미지에서 텍스트 임베딩을 생성하는 과정
- 이미지 특징을 추출 → VEmb = h1(V)
- LLM에 입력할 수 있도록 변환 → Vin = h3(VEmb)
- 텍스트 임베딩과 정렬(Alignment) 학습
- 여기서 Info-NCE Loss를 활용하여 임베딩 학습을 수행.
- 이미지를 보고 텍스트를 생성하는 과정
- 이미지 특징을 단어 임베딩과 결합 → [Vin, [CAP], x(<i)]
- LLM을 통해 다음 단어를 생성 → P(fθ(x(i)))
- 캡셔닝 Loss를 활용하여 학습 → LGen = - log P(fθ(x(i)))
즉, 하나의 경로로 임베딩과 생성 목표를 동시에 학습하는 것이 핵심이다.
(2) PoolAggregator를 이용한 Fine-Grained 정보 처리
기존 CLIP과 같은 모델들은 이미지 전체에서 하나의 글로벌 표현만 사용하여 학습한다. 하지만 MM-GEM에서는 PoolAggregator를 도입하여 이미지 내 특정 영역 정보를 보다 정밀하게 활용한다.
📌 예제: 기존 CLIP vs MM-GEM
- CLIP:
- “개가 있는 이미지”를 찾을 때, 이미지 전체를 하나의 벡터로 변환하여 비교 → 개가 차지하는 영역이 작으면 찾기 어려움.
- MM-GEM:
- 각 이미지 픽셀에서 특징을 추출하고, 특정 영역(region) 정보를 직접 학습
- 즉, “왼쪽 하단에 강아지가 있는 이미지”를 검색 가능.
이 방식은 세밀한 검색(Fine-grained Retrieval) 및 영역 기반 캡셔닝(Region-based Captioning)에 강력한 효과를 발휘한다.
(3) 다단계 학습(Multi-Stage Training)
임베딩과 생성을 동시에 학습하려면, 학습 단계를 나누어 점진적으로 최적화하는 것이 중요하다.
Stage 1: 전역 이미지-텍스트 정렬 학습
- CLIP과 비슷한 방식으로 이미지-텍스트 쌍을 정렬(Alignment)하는 학습을 진행.
- VEmb = h1(MeanPool(V))을 활용하여 전역 특징을 학습.
Stage 2: Fine-Grained 학습
- 첫 번째 학습 단계에서 학습된 모델을 Region-level 데이터로 추가 학습.
- 특정 영역(region)에 대한 RoIAlign 연산을 수행하여, 특정 객체를 인식하는 능력을 강화.
이 방식 덕분에 CLIP과 같은 성능을 유지하면서도, 생성 모델의 세부적인 표현력을 확보할 수 있다.
3. MM-GEM의 학습 목표 수식

즉, 임베딩과 생성을 동시에 최적화하는 손실 함수 구조를 유지한다.
4. MM-GEM의 실질적 효과
- 기존 모델(CLIP, CoCa 등)과 동일한 임베딩 성능을 유지하면서도, 생성 능력 추가
- Fine-Grained 검색 및 생성이 가능하여, 이미지의 세부 영역까지 활용
- 긴 문장(Long-form text) 검색 성능이 향상됨 (긴 캡션을 활용하는 이미지 검색 성능 증가)
5. 결론
MM-GEM의 방법론은 단순한 모델 제안이 아니라, 임베딩과 생성이 충돌 없이 공존할 수 있는 방법론적 발전을 제시한다.
- LLM을 활용한 임베딩과 생성 목표의 통합
- PoolAggregator를 활용한 Fine-Grained 학습
- 다단계 학습(Multi-Stage Training)으로 점진적 최적화
이 방식은 향후 멀티모달 LLM의 발전 방향에 중요한 시사점을 제공한다.
MM-GEM 논문의 결과 및 결론 정리
1. 실험 결과 분석
MM-GEM은 다양한 멀티모달 태스크에서 기존 최첨단(SOTA) 모델들과 비교하여 성능을 평가했다. 실험 결과는 다음과 같이 요약할 수 있다.
(1) 이미지-텍스트 검색(Image-Text Retrieval)
- 벤치마크: COCO, Flickr30K 데이터셋에서 평가
- 비교 모델: OpenCLIP, CLIP, MM-GEM
- 핵심 결과:
- OpenCLIP과 거의 동등한 성능을 보이며, 기존 CLIP보다 Recall@1 성능이 5% 이상 향상됨.
- 긴 문장(Long-form text)을 포함한 이미지 검색 성능이 크게 향상됨.
🔹 COCO 데이터셋 Recall@1 결과
| 모델 | 이미지→텍스트 검색 | 텍스트→이미지 검색 |
| CLIP | 57.4 | 34.3 |
| OpenCLIP | 61.3 | 45.8 |
| MM-GEM | 61.0 | 45.6 |
🔹 Flickr30K 데이터셋 Recall@1 결과
| 모델 | 이미지→텍스트 검색 | 텍스트→이미지 검색 |
| CLIP | 87.0 | 63.5 |
| OpenCLIP | 89.8 | 74.9 |
| MM-GEM | 89.0 | 75.4 |
📌 결론: MM-GEM은 기존 CLIP 기반 모델과 유사한 검색 성능을 유지하면서도, Fine-Grained 정보 학습을 통해 세부적인 이미지-텍스트 매핑 성능을 향상했다.
(2) 이미지 캡셔닝(Image Captioning)
- 벤치마크: COCO, NoCaps 데이터셋에서 평가
- 비교 모델: Flamingo, ClipCap, MM-GEM
- 핵심 결과:
- COCO 벤치마크에서는 ClipCap과 유사한 수준의 성능을 보임.
- NoCaps 벤치마크에서는 Flamingo보다 높은 성능을 기록.
- Fine-Grained 학습 이후, 세부적인 객체 기반 캡셔닝 능력이 크게 향상됨.
🔹 COCO 데이터셋 BLEU@4 점수
| BLEU@4 | CIDEr | |
| Flamingo | - | 79.4 |
| ClipCap* | 33.5 | 113.1 |
| MM-GEM | 32.8 | 110.9 |
📌 결론: MM-GEM은 일반적인 이미지 캡셔닝에서도 강력한 성능을 보이며, 특히 Fine-Grained 정보를 활용하여 특정 객체를 보다 정확하게 설명할 수 있는 능력을 보유했다.
(3) Fine-Grained 검색 및 캡셔닝
기존 CLIP 계열 모델들이 전역(Global) 정보만 활용하는 반면, MM-GEM은 지역(Region) 기반의 검색 및 캡셔닝이 가능하다.
- Fine-Grained 검색 실험에서는 Stage 2 학습 이후 특정 객체를 정확히 검색할 수 있도록 개선됨.
- L-DCI 데이터셋을 활용한 실험에서 Fine-Grained 검색 성능이 5% 이상 향상됨.
🔹 Fine-Grained 검색 성능 (L-DCI 벤치마크)
| Recall@1 | |
| CLIP | 30.4% |
| OpenCLIP | 43.0% |
| MM-GEM | 49.4% |
| MM-GEM (Stage 2 이후) | 54.1% |
📌 결론: 기존 CLIP 기반 모델들이 특정 객체 검색에 한계가 있었던 반면, MM-GEM은 PoolAggregator와 다단계 학습을 활용하여 특정 객체에 대한 검색 성능을 크게 향상시켰다.
2. 결론 및 연구의 기여
(1) 연구의 핵심 기여
본 연구는 기존의 임베딩(Embedding)과 생성(Generation) 모델을 하나의 LLM 내에서 통합한 새로운 접근법을 제안했다.
- LLM을 활용하여 멀티모달 통합: 기존 모델들이 별도의 인코더/디코더 구조를 유지했던 반면, MM-GEM은 하나의 LLM 내에서 임베딩과 생성을 동시에 수행할 수 있도록 최적화했다.
- Fine-Grained 검색 및 캡셔닝 가능: 기존 모델들은 전역(Global) 표현만 활용했지만, MM-GEM은 특정 객체와 텍스트를 직접 연결할 수 있는 PoolAggregator 기법을 도입하여 이를 개선했다.
- 긴 문장 검색 성능 개선: 기존 CLIP 계열 모델보다 긴 문장(Long-form text)에 대한 검색 성능이 5% 이상 향상됨.
📌 최종 결론:
- MM-GEM은 임베딩과 생성 간의 충돌을 해결하면서도, 두 가지 능력을 동시에 수행할 수 있는 최초의 모델이다.
- 기존 모델들의 한계를 극복하고, Fine-Grained 검색 및 캡셔닝 성능을 크게 향상시켰다.
- 멀티모달 모델 연구에서 향후 LLM 기반 접근법이 중요해질 가능성을 제시했다.
3. 연구의 한계 및 향후 연구 방향
(1) 연구의 한계
- 학습 데이터의 품질 문제
- Pre-training에 사용된 데이터셋(LAION-2B, COYO-700M 등)은 비정형적이고, 텍스트 품질이 일정하지 않음.
- 캡셔닝 및 검색 성능을 더욱 향상시키기 위해 더 정제된 고품질 데이터셋이 필요.
- Fine-Grained 학습을 초기에 적용하지 않음
- Stage 1에서는 전역(Global) 학습이 우선적으로 이루어지며, Fine-Grained 학습은 후반(Stage 2)에 적용됨.
- 하지만, 초기부터 Fine-Grained 학습을 적용하면 더 강력한 지역(region) 기반 표현 학습이 가능할 것.
- 멀티모달 LLM 확장 연구 부족
- 현재 MM-GEM은 이미지-텍스트 데이터에 최적화되어 있으며, 비디오(Video) 및 3D 데이터에는 적용되지 않음.
- 향후 연구에서 비디오 및 3D 환경에서도 동일한 방식으로 멀티모달 학습이 가능한지 탐구할 필요가 있음.
(2) 향후 연구 방향
- 더 정교한 학습 데이터 활용
- MM-GEM의 성능을 높이기 위해 노이즈가 적고, 더 정밀한 이미지-텍스트 데이터셋을 구축하는 연구가 필요함.
- 멀티모달 LLM 확장
- 비디오(Video) 및 3D 데이터에서도 MM-GEM의 접근법이 적용될 수 있는지 실험이 필요함.
- 특히, 멀티모달 LLM 기반의 대규모 생성 및 검색 시스템에 MM-GEM을 적용하는 연구가 기대됨.
- 모달리티 확장 (Audio, 3D 등)
- 현재는 이미지-텍스트 모델이지만, 오디오(Audio) 및 3D 데이터를 포함하는 확장된 모델로 발전할 가능성이 있음.
- 예를 들어, 음성(Voice) 또는 3D 객체를 검색할 수 있는 MM-GEM 모델로 발전 가능.
4. 최종 요약
- MM-GEM은 임베딩과 생성을 하나의 LLM에서 수행할 수 있도록 최적화한 최초의 모델.
- 기존 CLIP과 동등한 검색 성능을 유지하면서도 Fine-Grained 정보 학습 및 캡셔닝 성능 향상.
- 향후 비디오, 3D, 오디오 데이터로 확장할 가능성이 높은 모델.
이 연구는 멀티모달 인공지능(AI)의 새로운 방향을 제시하는 중요한 연구로 평가될 수 있다. 🚀
https://arxiv.org/abs/2403.00801
Self-Retrieval: End-to-End Information Retrieval with One Large Language Model
The rise of large language models (LLMs) has significantly transformed both the construction and application of information retrieval (IR) systems. However, current interactions between IR systems and LLMs remain limited, with LLMs merely serving as part o
arxiv.org