https://arxiv.org/abs/2206.10498
PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change
Generating plans of action, and reasoning about change have long been considered a core competence of intelligent agents. It is thus no surprise that evaluating the planning and reasoning capabilities of large language models (LLMs) has become a hot topic
arxiv.org
| 연구 목표 | - LLM이 실제로 계획을 수행할 수 있는지 평가 - 단순한 패턴 매칭이 아닌, 논리적 계획 및 실행 능력을 검증 - 국제 계획 대회(IPC)에서 사용되는 문제를 기반으로 객관적인 평가 제공 |
| 기존 연구와 차별점 | - 기존 연구는 주로 상식(reasoning) 기반 평가에 집중, PlanBench는 구체적인 계획 문제 해결 능력 평가 - 자동화된 계획 검증 도구(Plan Validator)를 사용하여 주관성을 배제한 평가 가능 - 도메인 이름, 액션, 프레디케이트를 난독화(Obfuscation) 하여 단순한 언어 패턴 의존 여부 검증 |
| 데이터셋 구성 | 1) Blocksworld (블록 쌓기 문제) - 목표: 블록을 특정한 순서로 쌓기 - 문제 수: 600개 - 변수: 블록 개수, 최적 계획 길이 다양 2) Logistics (물류 최적화 문제) - 목표: 트럭과 비행기를 이용해 패키지를 목적지로 운송 - 문제 수: 285개 - 변수: 도시, 트럭, 비행기 개수 다양 |
| 평가 항목 (Assessment Categories) | ① 계획 생성 (Plan Generation) - 주어진 목표를 달성하는 실행 가능한 계획을 생성할 수 있는가? ② 최적 비용 계획 (Cost-Optimal Planning) - 최소 비용/최단 경로 계획을 찾을 수 있는가? ③ 계획 검증 (Plan Verification) - 주어진 계획이 목표를 달성할 수 있는지 검증할 수 있는가? ④ 계획 실행 추론 (Reasoning About Execution) - 계획 실행 후의 상태를 정확히 예측할 수 있는가? ⑤ 목표 재구성 강건성 (Goal Reformulation Robustness) - 목표 표현이 달라져도 동일한 목표로 인식할 수 있는가? ⑥ 계획 재사용 (Plan Reuse) - 기존 계획을 새로운 문제에서 재사용할 수 있는가? ⑦ 재계획 (Replanning) - 예상치 못한 상태 변화 발생 시 올바르게 수정할 수 있는가? ⑧ 계획 일반화 (Plan Generalization) - 패턴을 학습하여 새로운 문제에 적용할 수 있는가? |
| 실험 모델 | GPT-4 vs. Instruct-GPT3 (text-davinci-002) |
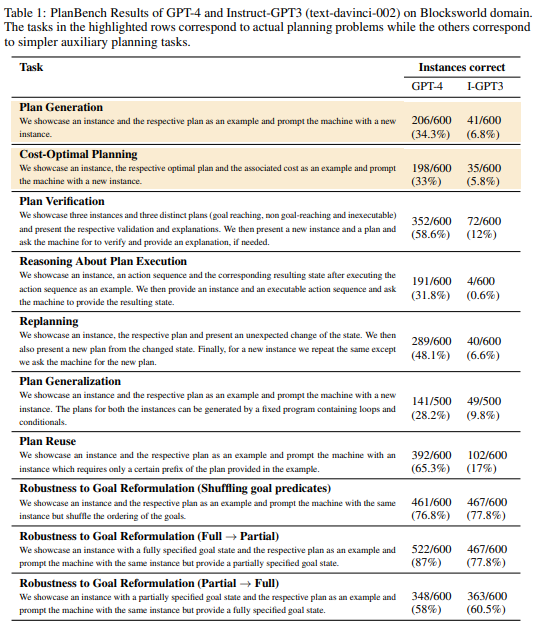
| 주요 실험 결과 | - 계획 생성 (34.3%) 및 최적 비용 계획 (33%) 성능 저조 → 복잡한 계획 구성 능력 부족 - 계획 검증 (58.6%) 성능 양호 → 오류 탐지 및 검증 가능 - 계획 실행 추론 (31.8%) 성능 저조 → 상태 변화를 논리적으로 예측하는 능력 부족 - 재계획 (48.1%) 성능 중간 수준 → 일부 계획 조정 가능하지만 높은 오류율 존재 - 계획 일반화 (28.2%) 실패 → 반복 패턴 학습 및 적용 능력 부족 - 목표 재구성 (77~87%)은 강함 → 표현 방식이 달라져도 목표를 잘 인식 |
| 주요 발견 (Key Findings) | - LLM은 패턴 매칭에는 강하지만, 논리적 계획 구성에는 취약함 - 상태 변화(State Transition) 예측 능력이 매우 부족하여 계획 실행 오류 발생 - 목표 표현이 달라져도 이해하는 능력은 강하나, 계획 최적화 및 실행 능력은 제한적 - 계획을 일반화하거나 예상치 못한 상황에서 재계획하는 능력이 부족 |
| 결론 (Conclusion) | - 현재 LLM은 복잡한 계획 수행 능력이 제한적이며, 단순한 패턴 매칭을 넘어서는 계획 수행이 어려움 - 특히 계획 생성, 최적 비용 계획, 계획 일반화 능력이 취약하여 AI 에이전트로 활용되기에는 한계가 있음 - 목표 표현이 달라져도 처리할 수 있지만, 실제 문제 해결을 위한 논리적 사고 능력이 부족함 |


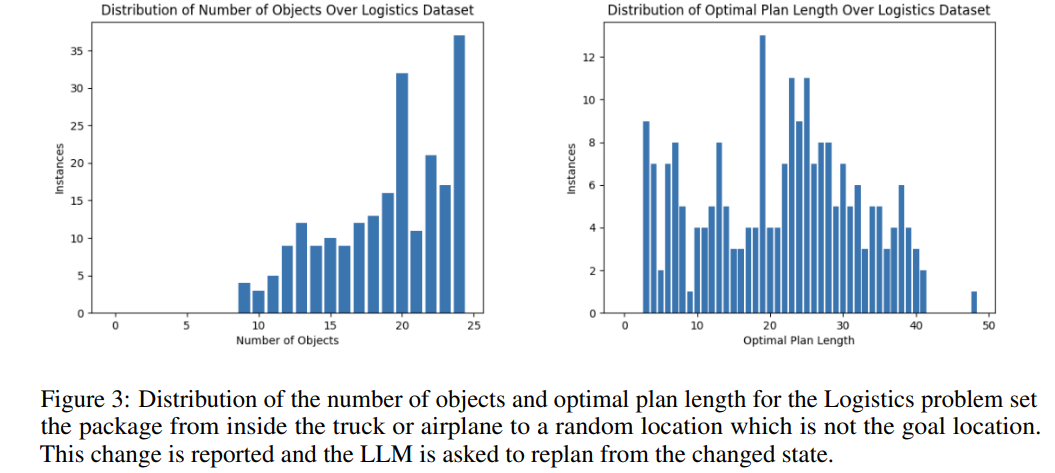
이 논문은 성공률이 심각할 정도로 낮습니다...
아직도 리더보드에는 2%조차 넘지 못하고 있고요
https://huggingface.co/spaces/osunlp/TravelPlannerLeaderboard
TravelPlannerLeaderboard - a Hugging Face Space by osunlp
huggingface.co
그래도 성공하는 모델도 곧 나오지 않을까 싶습니다.
논문 요약: PlanBench - LLM의 계획 및 변화 추론 능력 평가를 위한 확장 가능한 벤치마크
1. 연구 목적
최근 대형 언어 모델(LLM, Large Language Models)이 계획(Planning) 및 논리적 추론(Reasoning) 능력을 갖추고 있다는 주장이 나오고 있지만, 대부분의 평가는 상식(Common sense) 기반 문제를 중심으로 이루어져 실제 계획 수행 능력을 검증하기 어렵다.
PlanBench는 LLM이 실제로 계획을 수행하는지 아니면 훈련 데이터에서 단순히 기억(retrieval)하는 것인지 평가하기 위한 확장 가능한 벤치마크이다. 특히, 국제 계획 대회(IPC, International Planning Competition)에서 사용되는 도메인 기반 테스트를 통해 LLM의 진정한 계획 능력을 평가하는 것을 목표로 한다.
2. 기존 연구와 차별점
- 기존 연구들은 LLM의 논리적 추론이나 상식 추론을 평가하는 데 집중했으나, PlanBench는 구체적인 계획 문제를 자동 생성하고 평가하는 기법을 도입하여 보다 객관적인 평가를 가능하게 함.
- LLM의 계획 수행 능력을 자동화된 계획 검증 도구(Plan Validator) 를 이용하여 평가하여 주관적 해석을 배제.
- 다양한 도메인과 문제 유형을 포함하여 LLM이 일반적인 계획 문제를 해결할 수 있는지 검증.
3. PlanBench 평가 체계
PlanBench는 LLM의 계획 수행 능력을 평가하는 다양한 실험을 포함하며, 크게 두 개의 주요 카테고리로 나뉜다.
- 계획 생성(Plan Generation)
- 주어진 초기 상태(initial state)와 목표 상태(goal state)를 바탕으로 실행 가능한 계획을 생성하는 능력을 평가.
- 추론 및 계획 검증(Reasoning and Plan Verification)
- 주어진 계획이 올바르게 목표를 달성하는지 검증.
- 목표가 변경되었을 때 적절하게 재계획(Replanning)할 수 있는지 평가.
- 계획을 일반화하고(Generalization), 특정 상황에서 재사용(Reusing)할 수 있는지 확인.
세부 평가 항목
| 테스트 항목 | 평가 목적 |
| 계획 생성 (Plan Generation) | LLM이 주어진 목표를 달성하는 계획을 생성할 수 있는가? |
| 최적 비용 계획 (Cost-Optimal Planning) | LLM이 최소 비용으로 목표를 달성하는 계획을 생성할 수 있는가? |
| 계획 검증 (Plan Verification) | 주어진 계획이 실행 가능한지 여부를 평가할 수 있는가? |
| 계획 실행 추론 (Reasoning about Plan Execution) | 주어진 계획을 실행했을 때의 결과를 정확히 예측할 수 있는가? |
| 목표 재구성 강건성 (Robustness to Goal Reformulation) | 목표가 다르게 표현되었을 때 동일한 목표임을 인식할 수 있는가? |
| 계획 재사용 (Plan Reuse) | 이전 계획을 새로운 문제에서 재사용할 수 있는가? |
| 재계획 (Replanning) | 예상치 못한 상황 변화가 발생했을 때 계획을 수정할 수 있는가? |
| 계획 일반화 (Plan Generalization) | 유사한 패턴을 학습하고 이를 새로운 문제에 적용할 수 있는가? |
4. 데이터셋 및 평가 방법
(1) 도메인 기반 평가
PlanBench는 IPC에서 사용되는 도메인 기반 문제를 활용하여 평가를 진행.
- Blocksworld: 블록 쌓기 문제
- Logistics: 물류 최적화 문제
각 도메인에서는 초기 상태와 목표 상태가 주어지고, LLM이 이를 해결할 수 있는지 평가함.
(2) 자동화된 계획 검증
- LLM이 생성한 계획이 올바른지 확인하기 위해 자동 계획 검증 도구(Plan Validator) 를 사용하여 평가.
- 일부 문제에서는 혼란을 유발하는 단어(Misleading Words) 를 사용하여 LLM이 단순히 단어 패턴을 인식하는 것이 아니라 실제로 계획을 수행할 수 있는지 검증.
5. 실험 결과
(1) GPT-4와 Instruct-GPT3 성능 비교
PlanBench에서 GPT-4와 Instruct-GPT3의 성능을 비교한 결과, GPT-4가 상대적으로 우수한 성능을 보였으나 여전히 한계를 보였다.
| 테스트 항목 | GPT-4 | GPT-3 |
| 계획 생성 | 34.3% | 6.8% |
| 최적 비용 계획 | 33% | 5.8% |
| 계획 검증 | 58.6% | 12% |
| 계획 실행 추론 | 31.8% | 0.6% |
| 재계획 | 48.1% | 6.6% |
| 계획 일반화 | 28.2% | 9.8% |
| 계획 재사용 | 65.3% | 17% |
| 목표 재구성 강건성 (Shuffling Goal Predicates) | 76.8% | 77.8% |
| 목표 재구성 강건성 (Full → Partial) | 87% | 77.8% |
| 목표 재구성 강건성 (Partial → Full) | 58% | 60.5% |
(2) 주요 관찰 결과
- GPT-4도 여전히 많은 문제에서 실패: 특히, 계획 생성 및 최적 비용 계획 문제에서 30~40% 수준의 정확도를 보임.
- 일반적인 목표 재구성 문제(Shuffling, Full→Partial)에서는 상대적으로 높은 성능을 보였으나, 재계획(Replanning) 및 계획 실행 추론(Reasoning about Execution) 문제에서는 성능이 낮음.
- Misleading Words를 포함한 테스트에서는 성능이 급감: 즉, LLM이 단순한 단어 패턴에 의존하는 경향이 있음.
6. 결론 및 향후 연구 방향
(1) 결론
- 현재 LLM의 계획 수행 능력은 제한적이며, 많은 경우 단순한 패턴 매칭에 의존하는 것으로 보임.
- PlanBench는 LLM의 계획 수행 능력 평가를 위한 유용한 지표로 활용될 수 있음.
- 특히, 최적 비용 계획 및 계획 실행 추론 능력이 부족하여 LLM이 실제 AI 에이전트로 활용되기 위해서는 추가적인 연구가 필요함.
(2) 향후 연구 방향
- 부분적으로 정답에 가까운 계획을 평가하는 메트릭 추가: 현재 PlanBench는 정확한 정답만을 평가하므로, 부분적으로 유효한 계획도 평가할 수 있는 체계가 필요함.
- IPC 도메인 확장: 현재는 두 개의 도메인(Blocksworld, Logistics)만 포함되어 있으나, 다양한 도메인으로 확장 가능함.
- LLM의 계획 수행을 개선하기 위한 방법 연구: 예를 들어, MoE(Mixture of Experts)와 같은 아키텍처를 적용하여 특정 전문가 모듈이 계획 문제를 해결하도록 학습하는 방법을 연구할 수 있음.
7. 연구 시사점
PlanBench는 LLM의 계획 수행 능력을 체계적으로 평가할 수 있는 중요한 벤치마크로, 강화학습, MoE, 자동 계획 생성 기술과 결합하여 연구하면 LLM의 계획 수행 능력을 향상시킬 수 있을 것으로 기대됨. 🚀
PlanBench 평가 체계 상세 설명
PlanBench는 LLM의 계획(Planning) 및 변화 추론(Reasoning about Change) 능력을 평가하기 위한 확장 가능한 벤치마크로, 자동 계획(Automated Planning) 연구에서 널리 사용되는 프레임워크를 기반으로 설계되었다. LLM이 단순한 패턴 매칭을 수행하는 것이 아니라, 실제 계획을 생성하고 실행할 수 있는지 평가하는 것이 핵심 목표다.
1. PlanBench 데이터셋
PlanBench는 국제 계획 대회(IPC, International Planning Competition)에서 사용되는 대표적인 계획 문제(Planning Problem) 도메인을 기반으로 구축되었다. 현재 초기 버전에서는 두 가지 대표적인 도메인을 포함하고 있다.
(1) Blocksworld 도메인
- 목표: 블록을 테이블 위에서 특정한 순서대로 쌓아 목표 상태를 달성하는 문제
- 제약 조건:
- 한 번에 하나의 블록만 집을 수 있음
- 블록을 올려놓을 위치는 비어있어야(clear condition) 함
- 손에 블록을 들고 있어야 블록을 놓을 수 있음
- 데이터 구성:
- 600개의 문제 인스턴스를 포함
- 블록 개수 및 계획 길이(Plan Length)가 다양한 문제로 구성
(2) Logistics 도메인
- 목표: 트럭과 비행기를 이용해 패키지를 목표 위치로 운반하는 문제
- 제약 조건:
- 트럭은 같은 도시에 있는 위치들 사이만 이동 가능
- 비행기는 도시간의 공항 간에만 이동 가능
- 패키지는 해당 위치의 트럭이나 비행기에 실려야 운송 가능
- 데이터 구성:
- 285개의 문제 인스턴스를 포함
- 도시, 패키지, 트럭, 비행기의 개수가 다양하게 설정됨
📌 추가적인 평가: PlanBench는 같은 도메인에서 오브젝트, 액션, 프레디케이트의 이름을 난독화(Obfuscation)한 버전을 포함하여, LLM이 단순한 언어 패턴에 의존하는지 또는 실제 논리적 계획을 수행하는지 테스트할 수 있도록 설계됨.
2. 평가 항목 (Assessment Categories)
PlanBench는 LLM의 다양한 계획 및 추론 능력을 평가하기 위해 8가지 주요 평가 항목을 포함한다.
(1) 계획 생성 (Plan Generation)
- 목표: LLM이 주어진 초기 상태와 목표 상태를 기반으로 올바른 실행 가능한 계획을 생성할 수 있는지 평가
- 방법:
- 예제 문제(1-shot)와 정답 계획을 제공한 후, 새로운 문제에 대해 계획을 생성하도록 함
- 생성된 계획이 실제 실행 가능한지 자동 계획 검증 도구(Plan Validator)로 평가
- 얻을 수 있는 것: LLM이 문제를 논리적으로 분석하고 계획을 구성할 수 있는가?를 확인할 수 있음
(2) 최적 비용 계획 (Cost-Optimal Planning)
- 목표: LLM이 주어진 문제를 해결하는 최단 경로(Optimal Path) 또는 최소 비용(Minimum Cost) 계획을 생성할 수 있는지 평가
- 방법:
- 각 액션(Action)에 대해 비용(Cost)을 부여하고, 최적의 비용을 가지는 계획을 생성하도록 유도
- LLM이 생성한 계획이 최적 비용인지 검증
- 얻을 수 있는 것: LLM이 최적화를 고려한 계획을 만들 수 있는지 평가할 수 있음
(3) 계획 검증 (Plan Verification)
- 목표: 주어진 계획이 목표를 달성하는 데 올바른지 평가할 수 있는가?
- 방법:
- 실행 가능한 계획과 실행 불가능한 계획을 제공하고, LLM이 해당 계획의 타당성을 판별하도록 요청
- 실패한 경우, 어느 부분에서 문제가 발생하는지 설명할 수 있는지 확인
- 얻을 수 있는 것: LLM이 논리적으로 계획을 검증할 수 있는지 확인할 수 있음
(4) 계획 실행 추론 (Reasoning about Plan Execution)
- 목표: LLM이 주어진 계획이 실행된 이후의 상태(State)를 정확하게 예측할 수 있는지 평가
- 방법:
- 초기 상태와 특정 액션 시퀀스를 제공한 후, 계획 실행 후 상태를 예측하도록 요청
- 실제 실행 결과와 비교하여 정확성을 평가
- 얻을 수 있는 것: LLM이 단순한 규칙 적용을 넘어서 실제 상태 변화를 이해하는지 확인 가능
(5) 목표 재구성 강건성 (Robustness to Goal Reformulation)
- 목표: 같은 목표를 다르게 표현했을 때 LLM이 동일한 목표임을 인식할 수 있는지 평가
- 방법:
- 같은 목표를 문장 순서 변경, 부분 목표 제공(Full → Partial), 부분 목표에서 전체 목표로 확장(Partial → Full) 하는 방식으로 표현을 변경
- 동일한 계획을 생성할 수 있는지 확인
- 얻을 수 있는 것: LLM이 표현 방식에 영향을 받지 않고 동일한 목표를 인식하는지 확인 가능
(6) 계획 재사용 (Plan Reuse)
- 목표: 이전 문제에서 해결한 계획을 새로운 문제에서 일부 또는 전체를 재사용할 수 있는가?
- 방법:
- 주어진 예제 문제에서 사용된 계획의 일부가 새로운 문제에서도 유효하도록 구성
- LLM이 동일한 하위 계획을 재사용하는지 평가
- 얻을 수 있는 것: LLM이 계획의 일반적인 패턴을 학습하고, 유사한 문제에서 활용할 수 있는지 확인할 수 있음
(7) 재계획 (Replanning)
- 목표: 계획을 실행하는 도중 예상치 못한 변화가 발생했을 때, 올바르게 수정할 수 있는가?
- 방법:
- 계획을 실행하는 도중 일부 상태를 변경하고, 변경된 상태에서 다시 계획을 세우도록 요청
- 새롭게 생성된 계획이 올바른지 평가
- 얻을 수 있는 것: LLM이 동적 변화에 대응하여 계획을 조정할 수 있는지 확인할 수 있음
(8) 계획 일반화 (Plan Generalization)
- 목표: 특정한 패턴을 가진 계획을 학습하고, 이를 유사한 새로운 문제에서 적용할 수 있는가?
- 방법:
- 반복적인 패턴을 포함한 계획을 제공한 후, 유사한 구조의 새로운 문제를 제시
- 동일한 규칙을 적용하여 올바른 계획을 생성하는지 평가
- 얻을 수 있는 것: LLM이 계획 패턴을 일반화하여 새로운 문제에도 적용할 수 있는지 확인 가능
3. PlanBench 평가를 통해 얻을 수 있는 것
- LLM의 계획 수행 능력 한계를 객관적으로 분석할 수 있음.
- LLM이 단순한 데이터 패턴을 인식하는지, 실제로 논리적으로 계획을 세울 수 있는지 검증할 수 있음.
- 상황 변화(Unexpected Changes)에 대한 적응력(Adaptability) 평가가 가능함.
- 향후 강화학습(RL)이나 Mixture of Experts(MoE) 모델 적용을 통해 LLM의 계획 수행 능력을 개선하는 연구에 활용 가능.
4. 향후 연구 방향
PlanBench는 향후 더 많은 도메인 및 평가 기준을 추가하여 LLM의 계획 능력을 더 정교하게 분석할 수 있도록 확장될 예정이다. LLM이 보다 정교한 AI 에이전트로 활용될 수 있도록 계획 최적화 및 실행 검증을 포함한 개선된 평가 방법론이 추가될 가능성이 크다. 🚀
PlanBench 논문의 결과, 결론 및 마무리 정리
1. 실험 결과 분석
PlanBench를 이용하여 GPT-4와 Instruct-GPT3를 평가한 결과, LLM의 계획 수행 능력이 기대보다 부족함이 드러났다.
(1) 주요 결과 요약
| 테스트 항목 | GPT-4 | GPT-3 |
| 계획 생성 (Plan Generation) | 34.3% | 6.8% |
| 최적 비용 계획 (Cost-Optimal Planning) | 33% | 5.8% |
| 계획 검증 (Plan Verification) | 58.6% | 12% |
| 계획 실행 추론 (Reasoning About Plan Execution) | 31.8% | 0.6% |
| 재계획 (Replanning) | 48.1% | 6.6% |
| 계획 일반화 (Plan Generalization) | 28.2% | 9.8% |
| 계획 재사용 (Plan Reuse) | 65.3% | 17% |
| 목표 재구성 강건성 (Shuffling Goal Predicates) | 76.8% | 77.8% |
| 목표 재구성 강건성 (Full → Partial) | 87% | 77.8% |
| 목표 재구성 강건성 (Partial → Full) | 58% | 60.5% |
(2) 주요 발견
📌 1) LLM의 계획 생성 능력은 제한적이다.
- GPT-4가 계획 생성(34.3%)과 최적 비용 계획(33%)에서 낮은 성능을 보임.
- 단순한 패턴 매칭을 넘어서 논리적으로 계획을 구성하는 능력이 부족함.
📌 2) 계획 실행 추론(Reasoning About Execution) 능력이 매우 낮다.
- GPT-4의 성능이 31.8%, Instruct-GPT3는 0.6%에 불과.
- 이는 LLM이 상태 변화(State Change)를 논리적으로 추론하는 능력이 매우 부족함을 시사.
📌 3) 목표 재구성(Goal Reformulation)에는 강하지만, 논리적 계획에는 약하다.
- 목표가 다르게 표현되었을 때 동일한 목표임을 인식하는 테스트(Shuffling, Full → Partial)에서는 높은 성능을 보임.
- 이는 LLM이 표현의 다양성을 처리하는 데 강하지만, 논리적으로 계획을 구성하는 것은 어려워한다는 증거.
📌 4) 재계획(Replanning)과 계획 재사용(Plan Reuse) 능력이 부족하다.
- 재계획 문제에서는 48.1%의 정확도를 기록, 예상치 못한 상황 변화에 적응하는 능력이 부족함.
- 기존 계획을 재사용하는 능력(65.3%)은 비교적 양호했지만, 여전히 인간 수준에는 미치지 못함.
📌 5) 계획 일반화(Plan Generalization)는 거의 불가능했다.
- GPT-4: 28.2%, Instruct-GPT3: 9.8%
- 특정한 패턴을 학습하여 일반화하는 능력이 매우 낮으며, 새로운 문제를 스스로 해결하는 능력이 부족함.
2. 결론
PlanBench를 이용한 실험 결과, 현재의 LLM은 단순한 문장 생성이나 기억 기반의 응답을 넘어서 복잡한 계획을 수행하는 능력이 매우 제한적임이 드러났다.
(1) LLM은 진정한 계획 수행 능력이 부족하다.
- 일부 계획 문제에서는 어느 정도 성공했지만, 단순한 기억 기반 패턴 매칭이 주된 메커니즘으로 작용하는 것으로 보인다.
- 계획을 논리적으로 구성하고, 변경 사항을 반영하며, 최적화하는 능력은 부족함.
(2) 논리적 추론(Logical Reasoning)과 상태 변화 예측(State Transition Understanding)이 미흡하다.
- 계획 실행 후 상태를 정확히 예측하는 능력이 낮아, 실제 환경에서의 활용이 어려움.
- 단순한 규칙 적용보다는 추론과 논리적 사고를 강화하는 연구가 필요함.
(3) LLM이 계획을 일반화하고 적응하는 능력이 제한적이다.
- 인간처럼 패턴을 학습하여 새로운 상황에서도 유연하게 계획을 적용하는 능력이 부족함.
- 특히 미리 학습되지 않은 새로운 문제에서는 성능이 현저히 떨어짐.
3. 향후 연구 방향
PlanBench 결과를 기반으로, 향후 연구에서는 LLM의 계획 수행 능력을 향상시키기 위한 방법을 모색해야 한다.
(1) LLM의 계획 수행을 강화하기 위한 새로운 학습 방법 도입
- 강화학습(RL, Reinforcement Learning)과의 결합: LLM이 시행착오를 통해 계획을 최적화할 수 있도록 학습.
- Mixture of Experts (MoE) 구조 활용: 계획 전문가(Planning Expert)를 포함하는 방식으로 LLM 내부에 논리적 추론을 수행하는 모듈 추가.
(2) 구조화된 계획 표현을 활용한 학습 강화
- 현재 LLM은 주로 자연어 기반으로 계획을 학습하지만, PDDL(Planning Domain Definition Language)과 같은 구조화된 표현을 직접 활용하는 방법이 연구될 필요가 있음.
(3) 동적 계획 재수정 및 환경 적응 능력 강화
- Replanning 및 Online Learning 기법을 적용하여, 변화하는 환경에서도 지속적으로 학습 및 적응할 수 있도록 개선.
(4) LLM의 계획 검증 및 실행 오류 수정 자동화
- 자동 계획 검증 시스템과 결합하여, LLM이 생성한 계획이 오류를 포함할 경우 자동으로 수정하는 방법론 연구.
4. 마무리
PlanBench는 LLM이 단순한 언어 모델이 아니라 실제 AI 에이전트로서 활용될 수 있는지 평가하는 데 중요한 벤치마크로 작용한다.
- 현재 LLM의 계획 수행 능력은 상당한 한계를 가지며, 특히 계획 생성(Plan Generation)과 최적화(Cost-Optimal Planning), 계획 일반화(Plan Generalization)에서 취약한 성능을 보임.
- 하지만, 목표 재구성 및 계획 재사용 측면에서는 일정 수준의 성과를 보이며, 향후 적절한 아키텍처 개선을 통해 발전 가능성이 있음.
PlanBench의 결과는 단순한 패턴 기반 학습을 넘어서, 진정한 계획 수행 및 문제 해결을 위한 AI 모델을 개발하는 데 중요한 참고 자료가 될 것이다. 향후 연구는 LLM을 실제 AI 에이전트로 발전시키는 방향으로 나아가야 하며, 이를 위해 강화학습, MoE, 구조화된 계획 모델을 활용한 연구가 필요하다. 🚀
https://arxiv.org/abs/2402.01622
TravelPlanner: A Benchmark for Real-World Planning with Language Agents
Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of the cognitive substrates necessary for human-level planning have been lacking. Recentl
arxiv.org
| 연구 배경 | - AI 플래닝 연구는 전통적으로 제한된 환경(Constrained Settings)에서 진행됨. - LLM(대규모 언어 모델)의 발전으로 복잡한 계획 수행 가능성이 증가했지만, 실제 환경에서의 성능 검증이 부족. - TravelPlanner는 현실적인 여행 계획을 통해 AI의 플래닝 능력을 평가하는 새로운 벤치마크. |
| 연구 목표 | - AI가 현실 세계에서 복잡한 제약을 고려한 장기적인 여행 계획을 수립할 수 있는지 평가. - AI가 도구를 활용해 정보를 수집하고, 다중 제약을 고려하여 최적의 계획을 수립할 수 있는지 검증. |
| TravelPlanner 개요 | - 여행 계획(Travel Planning)을 위한 AI 평가 벤치마크. - 약 400만 개의 데이터와 1,225개 여행 요청(Query) 데이터셋 포함. - 6가지 도구(Toolbox) 사용 가능: 항공편, 숙박, 관광지, 식당, 교통 검색 기능 포함. |
| 데이터셋 구성 | - 도시 정보 (312개), 항공편 정보 (3,827,361개), 숙소 정보 (5,064개) 등 실제 환경 데이터를 활용. - 1,225개의 사용자 요청(Query)을 Easy / Medium / Hard 난이도로 분류. |
| 평가 항목 | ① 계획 완성률 (Delivery Rate): AI가 완전한 여행 계획을 수립할 수 있는가? ② 상식적 제약 충족률 (Commonsense Pass Rate): 논리적 오류 없이 합리적인 여행 계획을 세우는가? ③ 사용자 요구 조건 충족률 (Hard Constraint Pass Rate): 예산, 숙박 조건, 교통 수단 등 사용자 요구를 만족하는가? ④ 최종 성공률 (Final Pass Rate): 모든 제약을 충족한 완벽한 여행 계획을 생성하는가? |
| 주요 실험 결과 | - GPT-4-Turbo조차 최종 성공률 0.6%로 극히 낮음. - GPT-3.5, Gemini Pro, Mixtral 등은 여행 계획을 완벽히 수행한 사례 없음(0%). - AI 모델들이 도구 사용 오류, 논리적 계획 오류, 예산 초과, 교통 수단 충돌 등 주요 제약 조건을 지키지 못함. |
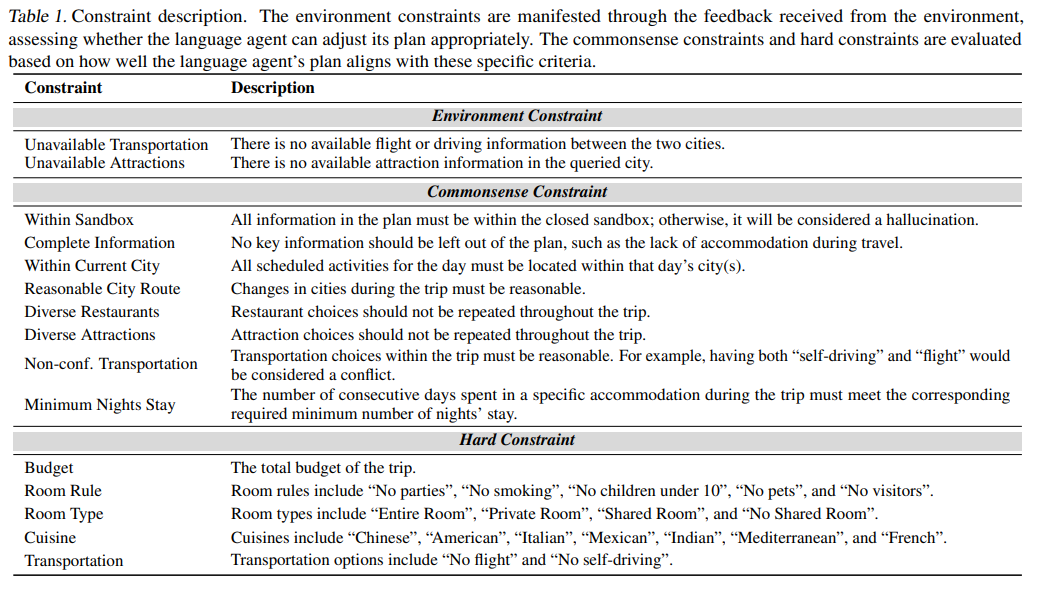
| AI 플래닝 한계점 | ① 정보 부족 오류 (Hallucination): AI가 없는 정보를 생성하거나 도구를 잘못 사용. ② 다중 제약(Multi-Constraint) 처리 실패: 예산, 숙소 규칙, 음식 선호 등을 동시에 고려하지 못함. ③ 논리적 문제 (Logical Inconsistencies): 같은 날 비행기와 자가 운전을 동시에 선택하는 등 모순된 계획 생성. ④ 무한 루프(Dead Loop) 문제: AI가 동일한 정보를 반복적으로 검색하고, 해결하지 못함. |
| 결론 및 시사점 | - 현재 AI 모델들은 현실적인 여행 계획을 수립하는 데 매우 취약. - 기존 플래닝 전략(ReAct, Reflexion 등)이 현실 환경에서 효과적이지 않음. - TravelPlanner는 향후 AI 플래닝 모델 개선을 위한 중요한 테스트베드 역할 수행. |
| 향후 연구 방향 | ① 강화된 플래닝 전략 개발: Backtracking, Heuristic 기반 플래닝 도입. ② AI의 도구 활용 능력 강화: 멀티 모달 데이터(이미지, 지도 등)와 연계된 플래닝 연구. ③ LLM 기반 장기 플래닝 성능 개선: MoE(Mixture of Experts) 모델, 강화학습(RLHF) 기반 플래닝 최적화. ④ 다중 에이전트 협력(Multi-Agent Planning) 연구 적용. |
| 논문의 기여점 | - 현실적인 여행 계획 문제를 AI가 해결할 수 있는지 평가하는 최초의 벤치마크. - 단순한 Q&A 방식이 아닌 장기 계획(Long-horizon Planning)과 도구 활용 능력 평가. - 다중 제약(Multi-Constraint) 기반 AI 플래닝의 한계점을 명확히 드러냄. |
| 마무리 | - 현재 AI 모델들은 여전히 현실적인 문제 해결 능력이 부족함. - TravelPlanner는 차세대 AI 플래닝 연구 및 개선 방향을 제시하는 핵심 벤치마크로 활용될 것. - 향후 연구자들은 더 강력한 플래닝 알고리즘 및 AI의 도구 활용 최적화를 목표로 연구해야 함. |
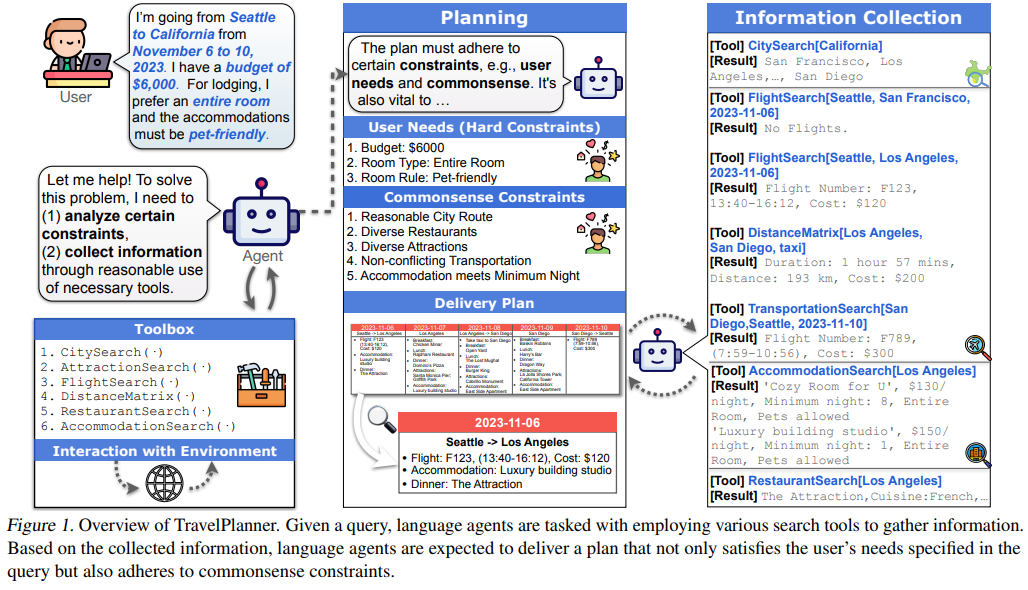


논문 요약: TravelPlanner - 실제 환경에서의 언어 기반 AI 계획 벤치마크
1. 연구 배경 및 문제 정의
계획(Planning)은 인간 지능의 핵심 요소이며, AI 연구에서 오랫동안 해결하고자 했던 중요한 문제다. 기존 AI 기반 계획 시스템은 주로 제한된 환경(Constrained Settings) 내에서 작동하며, 복잡한 현실 세계의 다양한 변수를 고려하는 데 한계를 보였다.
최근 대규모 언어 모델(LLMs, Large Language Models) 기반의 언어 에이전트(Language Agents)가 등장하면서, 도구 활용(tool use), 추론(reasoning) 등의 능력을 보이며 AI 기반 계획의 가능성을 확장시켰다. 하지만, 기존 연구들은 단일 목표 최적화(Single-objective Optimization) 및 고정된 정답(Fixed Ground Truths)을 가진 전통적인 환경에 집중하고 있어 현실적인 문제 해결 능력을 검증하기 어렵다.
이에 연구진은 TravelPlanner라는 새로운 벤치마크를 제안하여, 복잡한 여행 계획(Travel Planning)이라는 실생활 문제를 해결할 수 있는 언어 에이전트의 능력을 평가하고자 한다.
2. TravelPlanner 벤치마크 개요
TravelPlanner는 현실적인 여행 계획 시나리오를 AI가 해결할 수 있는지 평가하는 새로운 벤치마크로, 다음과 같은 특징을 가진다.
- 다양한 도구(Toolbox) 활용
- TravelPlanner는 현실적인 데이터베이스를 기반으로 여행 계획을 세울 수 있도록 6가지 검색 도구를 제공한다.
- 도구 목록:
- CitySearch(도시 검색)
- AttractionSearch(관광지 검색)
- FlightSearch(항공편 검색)
- DistanceMatrix(이동 거리/시간/비용 검색)
- RestaurantSearch(음식점 검색)
- AccommodationSearch(숙소 검색)
- 방대한 데이터베이스
- TravelPlanner는 인터넷에서 수집한 약 400만 개의 데이터를 포함하고 있다.
- 1,225개의 다양한 사용자 쿼리를 포함하며, 이를 기반으로 AI의 계획 능력을 평가한다.
- 현실적인 제약조건 적용(Constraints)
- AI가 현실적인 여행 계획을 세울 수 있도록 다양한 제약조건(Constraints)을 설정하여 평가한다.
- 환경 제약(Environment Constraints): 항공편이 없거나, 특정 도시에서 관광지를 찾을 수 없는 경우.
- 상식 제약(Common Sense Constraints):
- 모든 정보는 주어진 데이터베이스 내에서 검색해야 함(할루시네이션 금지).
- 동일한 도시에서 동일한 레스토랑이나 관광지를 반복 방문하지 않도록 설계.
- 하드 제약(Hard Constraints):
- 예산(Budget), 숙박 유형(Room Type), 식사 선호(Cuisine), 교통 수단(Transportation) 등의 조건을 포함.
3. 실험 및 평가 결과
(1) 실험 환경
- TravelPlanner는 다단계 평가 방식을 적용하여, AI가 정보를 수집하고 계획을 세우는 능력을 검증함.
- AI 모델은 두 가지 설정에서 평가됨:
- Two-stage mode(정보 수집 및 계획 수립): AI가 직접 도구를 사용하여 정보를 수집한 후, 이를 바탕으로 계획을 수립.
- Sole-planning mode(계획 수립만 수행): 필요한 정보가 주어진 상태에서 계획만 수행.
(2) 사용된 AI 모델 및 기법
- LLMs 모델 비교
- GPT-3.5-Turbo, GPT-4-Turbo, Gemini Pro(Google), Mixtral-8×7B-MoE(Mistral AI), Mistral-7B-32K 등.
- 플래닝(Planning) 전략 비교
- Direct(기본 모델), Zero-Shot Chain-of-Thought(ZS-CoT), ReAct, Reflexion 기법 비교.
(3) 주요 결과
- GPT-4-Turbo가 가장 높은 성능을 보였지만, 성공률은 0.6%에 불과
- GPT-4-Turbo는 하드 제약을 모두 만족하는 계획을 생성하는 비율이 단 0.6%에 불과.
- 다른 모델(GPT-3.5, Mixtral, Gemini)은 아예 성공적인 계획을 세우지 못함(0%).
- 언어 모델 기반 계획(Planning)은 다중 제약을 고려하는 데 약함
- 대부분의 모델이 개별적인 제약 조건은 충족할 수 있었지만, 여러 제약을 동시에 만족시키는 데 실패.
- 특히 예산 초과, 숙박 조건 위반, 비논리적인 교통 계획 등의 오류가 많았음.
- 계획 오류 분석
- 잘못된 도구 사용(Argument Error): 도구를 잘못된 방식으로 호출하여 실패.
- 반복 오류(Dead Loop): 같은 정보를 계속 반복 검색.
- 정보 부족으로 인한 할루시네이션: 필요한 정보를 찾지 못하면 데이터를 조작하여 거짓 정보를 만들어냄.
4. 연구의 의미 및 향후 과제
(1) 현재 AI의 한계점
- 현존하는 최고 수준의 AI 모델들도 복잡한 여행 계획을 성공적으로 수행하지 못함.
- 특히, 다중 제약을 고려하는 장기 계획(Long-horizon Planning)에 대한 어려움이 명확히 드러남.
(2) 향후 연구 방향
- 더 정교한 플래닝 전략 개발 필요
- 기존의 ReAct, Reflexion과 같은 플래닝 기법들은 단순한 환경에서는 효과적이지만, 현실적인 다중 제약이 있는 환경에서는 한계를 보임.
- 새로운 계획 알고리즘(Backtracking, Heuristic-based Planning)이 필요함.
- 환경과의 상호작용 강화
- 현재 AI 모델들은 환경에서 주어진 피드백을 제대로 반영하지 못하고, 단순한 오류도 반복함.
- 동적 피드백 처리 및 적응형 계획(adaptive planning)이 가능한 AI 개발 필요.
- 복잡한 문제 해결 능력 향상
- 인간은 메모리, 가설 검증, 탐색(search) 등의 기법을 사용해 계획을 세움.
- AI 모델들도 메모리 기반 학습(Memory-augmented Learning)이나 강화 학습(RL) 등을 활용하여 더 정교한 계획 능력을 학습할 필요가 있음.
5. 결론
- TravelPlanner는 AI가 현실 세계에서 복잡한 계획을 수행하는 능력을 평가하는 중요한 벤치마크로 자리 잡을 것.
- 현재 AI 모델들은 기본적인 정보 검색 및 단순한 계획에는 강하지만, 다중 제약을 만족하는 장기 계획에는 매우 취약함.
- 본 연구를 통해, 향후 더욱 강력한 플래닝 능력을 가진 AI 시스템 개발이 필요하다는 점을 확인하였으며, TravelPlanner는 그 과정에서 중요한 실험 환경이 될 것임.
현재 진행 중인 연구와 TravelPlanner의 결과를 결합하여, AI의 장기 계획(Long-horizon Planning) 및 다중 제약 해결 능력을 향상시키는 연구를 진행하는 것이 유망할 것으로 보인다.
🔎 TravelPlanner 관련 연구 정리 및 기존 연구와의 차이점 분석
1. 관련 연구 및 논문 정리
TravelPlanner는 AI 기반 계획(Planning) 능력을 평가하는 벤치마크로, 기존 연구들과의 연속선상에서 발전한 개념이다. 이를 이해하기 위해 먼저 기존 연구들을 정리해보자.
(1) 기존 AI 플래닝 연구
📌 (1-1) 전통적 AI 플래닝 연구
- 규칙 기반(Heuristic-based) 플래닝
- 대표 논문: Russell & Norvig, 2010. "Artificial Intelligence: A Modern Approach"
- 특징: 전통적인 AI 플래닝은 규칙 기반(Heuristic-based) 접근법을 사용하여 정해진 규칙과 알고리즘을 따라 최적의 계획을 도출하는 방식.
- 예시: 로봇 경로 탐색, 교통 스케줄링 등에서 활용됨.
- 한계점: 현실 환경에서의 변화에 유연하게 대응하지 못하며, 확장성이 떨어짐.
- 고전적 AI 플래닝 시스템 (Classical Planning Systems)
- 대표 연구: Georgievski & Aiello, 2015. "HTN Planning: Overview, Comparison, and Beyond"
- 특징: 계층적 작업 네트워크(HTN, Hierarchical Task Network)와 같은 구조화된 플래닝 시스템이 활용됨.
- 예시: 로봇이 물건을 집어 특정 위치로 옮기는 태스크.
- 한계점: 정형화된 환경에서만 작동하며, 복잡한 현실 세계의 제약을 반영하기 어려움.
📌 (1-2) LLM 기반 플래닝 연구
- LLM을 활용한 언어 에이전트 연구
- 대표 연구: Yao et al., 2022. "ReAct: Synergizing Reasoning and Acting in Language Models"
- 특징: 언어 모델을 활용하여 정보를 수집하고, 이를 바탕으로 계획을 수행하는 방법.
- 주요 기여: LLM이 추론(Reasoning)과 행동(Acting)을 결합하여 복잡한 문제를 해결할 수 있도록 설계됨.
- 한계점: 단순한 태스크에서는 효과적이지만, **장기 플래닝(Long-horizon Planning)**에는 한계가 있음.
- Reflexion: 언어 모델의 자기 피드백(Self-Reflection)
- 대표 연구: Shinn et al., 2023. "Reflexion: Language Agents with Verbal Reinforcement Learning"
- 특징: LLM이 수행한 결과를 스스로 피드백하여 수정하고 점진적으로 개선하는 방식.
- 한계점: 다중 제약(Multi-Constraint) 처리 능력이 부족하여 TravelPlanner와 같은 현실적인 플래닝 문제를 해결하는 데는 한계가 있음.
- LLM과 도구 사용 연구 (Tool-Augmented LLMs)
- 대표 연구: Schick et al., 2023. "Toolformer: Language Models Can Teach Themselves to Use Tools"
- 특징: LLM이 외부 API와 도구를 스스로 호출하여 데이터를 수집하고 활용하는 방식.
- 한계점: 주어진 도구를 올바르게 활용하는 것이 핵심이지만, 복잡한 플래닝에서의 정보 수집과 활용 능력은 미비함.
2. TravelPlanner와 기존 연구의 차이점
TravelPlanner는 기존 연구의 한계를 극복하기 위해 다음과 같은 차별점을 가진다.
| 기존 연구 | 한계점 | TravelPlanner의 차별점 |
| 규칙 기반 플래닝 (Russell & Norvig, 2010) | 유연성이 부족하고 복잡한 환경에서 작동 어려움 | 현실 세계의 데이터를 반영하여 유연한 계획을 평가 |
| HTN 기반 플래닝 (Georgievski & Aiello, 2015) | 정형화된 환경에서만 동작, 인간 수준의 플래닝 불가 | 다중 제약을 포함한 복잡한 현실 문제 해결 가능 |
| ReAct 기반 플래닝 (Yao et al., 2022) | 단순한 환경에서는 효과적이지만, 복잡한 문제 해결은 어려움 | 실제 환경에서 도구 활용 및 플래닝 능력을 종합적으로 평가 |
| Reflexion (Shinn et al., 2023) | 자기 피드백 기능이 있지만, 장기 플래닝 수행 능력 부족 | 장기 플래닝(long-horizon planning) 능력을 평가 |
| Toolformer (Schick et al., 2023) | 도구 사용은 가능하지만, 종합적인 플래닝 능력이 부족 | 도구 사용뿐만 아니라, 종합적인 계획 수행 능력을 테스트 |
3. TravelPlanner의 기여점
1️⃣ 최초의 복합 현실 플래닝 벤치마크
- 기존 연구들은 단순한 환경에서의 AI 플래닝을 평가하는 반면, TravelPlanner는 현실적인 데이터와 복잡한 제약을 포함하여 실제 문제 해결 능력을 평가함.
2️⃣ 다중 제약(Multi-Constraint) 기반 평가
- TravelPlanner는 단순한 문제 해결이 아니라, 예산(Budget), 숙박(Room Type), 음식 선호(Cuisine), 교통 수단(Transportation) 등 여러 조건을 동시에 고려하는 능력을 테스트함.
3️⃣ 장기 플래닝(Long-horizon Planning) 평가
- 기존 연구들은 짧은 범위의 계획을 다루지만, TravelPlanner는 여러 도시를 방문하는 일정, 최적의 경로 설정, 제한된 예산 내 최적 계획 수립 등 장기적인 계획 능력을 평가함.
4️⃣ 언어 모델의 도구 활용 능력 검증
- TravelPlanner는 단순한 텍스트 기반 질의응답을 넘어, AI가 외부 도구를 적절히 활용할 수 있는지 평가하는 최초의 벤치마크 중 하나임.
4. 결론
- TravelPlanner는 기존 AI 플래닝 연구에서 해결하지 못한 문제를 보완하고, 현실적인 플래닝 능력을 평가하는 중요한 벤치마크임.
- 특히, 복잡한 다중 제약을 반영한 평가 체계, 장기 계획 문제 해결, 도구 활용 능력 평가라는 측면에서 기존 연구와 차별화됨.
➡ TravelPlanner의 도입으로 AI의 실제 환경에서의 계획 능력을 더욱 향상시킬 수 있는 연구 방향을 제시할 수 있음. 🚀
🔍 TravelPlanner의 평가 체계 상세 분석
TravelPlanner는 실제 환경에서의 AI 플래닝 능력을 종합적으로 평가하는 벤치마크로, 기존 평가 방식과 차별화된 다중 제약(Multi-Constraint) 기반 평가 시스템을 도입했다. 여기서는 TravelPlanner의 데이터셋 구성, 평가 항목, 평가 지표, 및 이를 통해 얻을 수 있는 시사점을 체계적으로 분석한다.
1. TravelPlanner의 데이터셋 구성
TravelPlanner는 AI가 현실적인 여행 계획을 수립할 수 있는지를 평가하기 위해 대규모 실세계 데이터셋을 활용한다. 데이터셋은 다음과 같이 구성되어 있다.
📌 데이터셋 크기 및 구성
| 데이터 유형 | 개수 | 설명 |
| 도시 정보 (CitySearch) | 312 | 특정 주(State) 내 존재하는 도시 목록 |
| 항공편 정보 (FlightSearch) | 3,827,361 | 출발 도시, 도착 도시, 날짜, 항공편 번호, 시간, 가격 등 |
| 이동 거리 (DistanceMatrix) | 17,603 | 두 도시 간의 이동 거리, 소요 시간, 예상 비용 |
| 레스토랑 정보 (RestaurantSearch) | 9,552 | 도시별 레스토랑 목록, 가격, 요리 종류 |
| 관광지 정보 (AttractionSearch) | 5,303 | 도시별 주요 관광지 정보 |
| 숙소 정보 (AccommodationSearch) | 5,064 | 도시별 숙박 시설, 가격, 최소 숙박일, 규칙 등 |
📌 평가 데이터셋
- 총 1,225개의 여행 계획 요청(Queries)
- 사용자가 직접 입력한 다양한 조건을 포함한 여행 계획 요청을 포함.
- 예: "3월 10일부터 3월 12일까지 Cincinnati에서 Norfolk으로 가는 3일 여행을 계획해줘. 예산은 $1,400이고, 반려동물 동반이 가능해야 해."
- 데이터셋 분할
- 훈련(Training) 데이터: 45개 (각 카테고리별 5개)
- 검증(Validation) 데이터: 180개
- 테스트(Test) 데이터: 1,000개
- 난이도 조정
- Easy: 예산 제한만 적용 (단일 제약)
- Medium: 예산 + 추가 조건 (숙소 유형, 식사 선호 등)
- Hard: 예산 + 다중 조건 (숙소, 교통수단 제한, 식사 선호 등)
2. TravelPlanner의 평가 항목 및 평가 방식
TravelPlanner는 AI의 계획 수립 능력을 다각도로 평가하기 위해 4가지 핵심 평가 항목을 설정하였다.
📌 (1) 계획 완성률 (Delivery Rate)
- 설명: AI가 주어진 쿼리에 대해 완전한 여행 계획을 생성할 수 있는가?
- 측정 방식:
- AI가 30단계 내에서 여행 계획을 완료하면 성공 (30단계를 초과하면 실패)
- AI가 계획을 완료하지 못하고 무한 루프(Dead Loop)에 빠질 경우 실패.
📌 (2) 상식적 제약 충족률 (Commonsense Constraint Pass Rate)
- 설명: AI가 일반적인 상식(Common Sense)을 고려한 계획을 세우는가?
- 측정 항목
- 🔹 Sandbox 내부 정보 사용 (Within Sandbox): AI가 제공된 데이터 내에서만 정보를 사용했는가? (할루시네이션 방지)
- 🔹 모든 정보 포함 (Complete Information): 계획에서 중요한 정보를 빠뜨리지 않았는가? (예: 숙소 예약 없음)
- 🔹 현재 도시와 일치 (Within Current City): 하루 동안 계획된 활동이 실제로 해당 도시에서 가능한가?
- 🔹 이동 경로 합리성 (Reasonable City Route): 비논리적인 이동 경로가 없는가? (예: 하루 안에 미국 서부에서 동부로 왕복)
- 🔹 다양한 식사 제공 (Diverse Restaurants): 동일한 식당을 계속 방문하는가?
- 🔹 다양한 관광지 방문 (Diverse Attractions): 동일한 관광지를 반복해서 방문하는가?
- 🔹 논리적인 교통 선택 (Non-conflicting Transportation): 같은 날 "비행기"와 "자가 운전"을 동시에 선택하는 등 모순이 없는가?
- 🔹 숙박 기간 충족 (Minimum Nights Stay): 숙소의 최소 숙박일 규칙을 따르는가?
📌 (3) 사용자 요구 조건 충족률 (Hard Constraint Pass Rate)
- 설명: AI가 사용자 요청 조건을 충족하는 여행 계획을 생성하는가?
- 측정 항목
- ✅ 예산 (Budget): AI가 사용자의 예산을 초과하지 않고 계획을 세웠는가?
- ✅ 숙소 규칙 (Room Rule): 반려동물 동반 가능 여부, 금연 여부 등 사용자 요청을 준수했는가?
- ✅ 숙소 유형 (Room Type): 사용자가 요청한 "Entire Room", "Private Room" 등 숙소 유형을 지켰는가?
- ✅ 식사 선호 (Cuisine): 사용자가 선호하는 음식(예: 인도 음식, 이탈리안 등)을 반영했는가?
- ✅ 교통수단 제한 (Transportation): 사용자가 특정 교통수단(예: 비행기 사용 금지)을 요청했을 때 이를 따랐는가?
📌 (4) 최종 성공률 (Final Pass Rate)
- 설명: AI가 모든 평가 항목을 통과하여 현실적인 여행 계획을 세울 수 있는가?
- 측정 방식:
- 상식적 제약 충족률 + 사용자 요구 조건 충족률을 모두 만족하는 비율을 측정.
3. 평가 방식 및 분석 방법
TravelPlanner는 두 가지 평가 모드에서 AI의 플래닝 능력을 측정한다.
📌 (1) Two-Stage Mode (정보 수집 + 플래닝)
- AI가 도구를 사용해 정보를 직접 수집한 후, 이를 바탕으로 여행 계획을 생성하는 방식.
- 주요 도전 과제:
- 도구를 올바르게 사용해야 함.
- 정보가 부족한 경우 어떻게 보완하는지 평가.
- 잘못된 정보를 생성하는 할루시네이션(Hallucination) 문제 확인.
📌 (2) Sole-Planning Mode (플래닝만 수행)
- 필요한 정보가 사전에 제공된 상태에서 AI가 여행 계획만 세우는 방식.
- 주요 도전 과제:
- 제한된 정보 내에서 최적의 계획을 세울 수 있는가?
- 다중 제약을 동시에 고려할 수 있는가?
4. TravelPlanner 평가 체계를 통해 얻을 수 있는 것
1️⃣ 현존하는 AI의 플래닝 능력 한계점 파악
- GPT-4-Turbo조차 최종 성공률이 0.6%에 불과, 현재 AI가 현실적인 여행 계획을 수행하는 것이 매우 어렵다는 점을 보여줌.
2️⃣ 복잡한 계획 수행을 위한 LLM 개선 방향 제시
- TravelPlanner의 결과를 바탕으로, AI의 장기 계획(Long-horizon Planning) 개선 및 다중 제약 문제 해결 능력 강화 필요성을 확인.
3️⃣ 도구 활용 능력 평가 및 최적화 전략 수립
- AI가 정보를 어떻게 수집하고 활용하는지 분석함으로써, LLM과 API 기반 도구의 통합 전략을 최적화할 수 있음.
4️⃣ 강화학습(RL) 및 MoE 기반 플래닝 연구 적용 가능
- TravelPlanner를 활용하여 강화학습(RLHF) 적용 및 Mixture of Experts(MoE) 기반 플래닝 최적화 연구를 수행할 수 있음.
💡 TravelPlanner의 평가 체계는 AI의 현실 문제 해결 능력을 평가하는 강력한 기준을 제공하며, 향후 더욱 발전된 플래닝 모델 개발을 위한 중요한 지표로 활용될 수 있다. 🚀
🔍 TravelPlanner 논문의 결과, 결론 및 마무리 정리
1. 연구 결과 (Experimental Results)
논문은 다양한 대규모 언어 모델(LLMs)과 플래닝(Planning) 전략을 활용하여 TravelPlanner 벤치마크에서 AI의 성능을 평가했다. 실험 결과, 현재 AI 모델들은 현실적인 여행 계획을 효과적으로 수행하지 못한다는 한계점이 명확하게 드러났다.
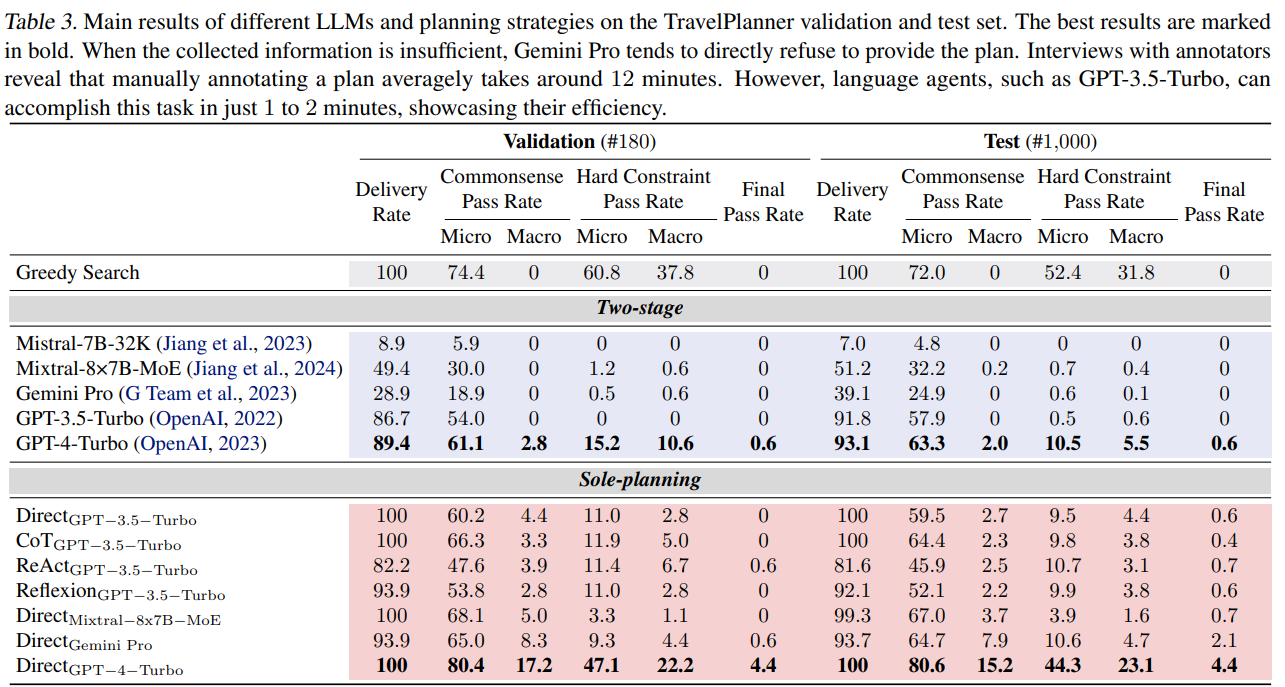
📌 (1) 주요 실험 결과
| 모델 및 전략 | 계획 완성률 (Delivery Rate) | 상식적 제약 충족률 (Commonsense Pass Rate, Micro/Macro) | 사용자 요구 충족률 (Hard Constraint Pass Rate, Micro/Macro) | 최종 성공률 (Final Pass Rate) |
| GPT-4-Turbo (Two-stage, ReAct) | 93.1% | 63.3% / 2.0% | 10.5% / 5.5% | 0.6% |
| GPT-3.5-Turbo (Two-stage, ReAct) | 91.8% | 57.9% / 0% | 0.5% / 0.6% | 0% |
| Gemini Pro (Two-stage, ReAct) | 39.1% | 24.9% / 0% | 0.6% / 0.1% | 0% |
| Mixtral-8×7B-MoE (Two-stage, ReAct) | 51.2% | 32.2% / 0.2% | 0.7% / 0.4% | 0% |
| GPT-4-Turbo (Sole-planning, Direct) | 100% | 80.6% / 15.2% | 44.3% / 23.1% | 4.4% |
📌 (2) 결과 분석
1️⃣ 💡 AI 모델들이 복잡한 계획 수행에서 현저히 부족함
- GPT-4-Turbo조차 최종 성공률(Final Pass Rate)이 0.6%에 불과.
- GPT-3.5, Gemini Pro, Mixtral 등 다른 모델들은 최종 성공률이 0%로, 어떠한 복잡한 여행 계획도 성공적으로 수행하지 못함.
2️⃣ 🛠 기존 플래닝 전략(ReAct, Reflexion 등)의 한계
- ReAct(Reasoning + Acting) 방식이 단순한 문제에서는 효과적이지만, 장기적인 플래닝(Long-horizon Planning)과 다중 제약(Multi-Constraint) 처리가 어려움.
- Reflexion 전략은 자기 피드백(Self-reflection)을 통한 개선을 시도했지만, 여전히 장기 계획 수행 능력은 미흡함.
3️⃣ ⚠ 주요 실패 유형
- 정보 부족으로 인한 오류: 올바른 정보를 수집하지 못하고, 부정확한 정보를 생성하는 할루시네이션(Hallucination) 발생.
- 제약 조건 미준수: 예산 초과, 숙박 기간 위반, 교통수단 충돌 등 사용자의 요구를 제대로 반영하지 못함.
- 도구 활용 미숙: AI가 도구를 올바르게 사용하지 못하거나, 무한 루프(Dead Loop)에 빠지는 경우 발생.
2. 결론 (Conclusion)
TravelPlanner 실험을 통해 현재 AI의 플래닝 능력에는 큰 한계가 존재한다는 점이 명확해졌다. 특히, 현실적인 다중 제약을 고려한 장기 계획 수립에서 기존의 LLM 기반 AI 모델들이 거의 실패한다는 점이 확인되었다.
📌 (1) 핵심 결론
1️⃣ ❌ AI는 현실적인 여행 계획을 성공적으로 수행하지 못함
- GPT-4-Turbo를 포함한 모든 모델들이 현실적인 플래닝 태스크에서 매우 낮은 성능을 보임.
- 특히 도구 활용 능력 부족, 논리적 오류, 다중 제약 처리 실패 등의 문제점이 두드러짐.
2️⃣ 📉 기존 플래닝 전략의 한계가 분명하게 드러남
- ReAct, Reflexion 등의 기존 플래닝 기법이 효과적이지 않으며, 보다 정교한 플래닝 전략이 필요함.
- 특히 계획 수행 중 발생하는 오류를 실시간으로 수정할 수 있는 동적 계획 조정 능력(Dynamic Planning Adjustment)이 필수적.
3️⃣ 🚀 TravelPlanner는 차세대 AI 플래닝 연구의 중요한 벤치마크 역할 수행
- TravelPlanner는 단순한 계획 수립이 아닌 현실적인 문제 해결 능력을 평가하는 첫 번째 벤치마크.
- 향후 AI가 더 복잡한 문제를 해결하고, 현실적인 플래닝을 수행할 수 있도록 발전시키는 연구에 활용될 수 있음.
3. 향후 연구 방향 (Future Work)
논문은 AI 플래닝 능력을 개선하기 위한 다양한 연구 방향을 제안한다.
📌 (1) 강화된 플래닝 전략 개발
✔ 장기적인 의사결정을 위한 Backtracking 기반 플래닝
✔ 휴리스틱(Heuristic) 기반 검색 기법과 AI 결합
✔ 과거 실패 사례를 학습하는 메모리 기반 플래닝(Memory-Augmented Planning)
📌 (2) AI의 도구 활용 능력 개선
✔ 더 강력한 API 활용 기법 개발
✔ 멀티 모달 데이터(이미지, 지도 데이터)와 결합한 계획 수립
✔ 다양한 도구를 동시에 사용할 수 있도록 AI 모델 최적화
📌 (3) AI의 장기 플래닝 성능 개선
✔ Mixture of Experts(MoE) 모델을 활용한 플래닝 최적화 연구
✔ 강화학습(RLHF) 기반으로 AI가 피드백을 학습하여 더 나은 계획을 생성하도록 유도
✔ 다중 에이전트 협력(Multi-Agent Collaboration) 기반 플래닝 연구
4. 마무리 (Closing Statement)
TravelPlanner 연구는 AI의 현실적인 계획 수행 능력을 평가하는 중요한 시발점이 되었다. 기존의 AI 모델들은 여전히 현실 세계에서의 복잡한 문제를 해결하는 데 한계를 보이며, 특히 다중 제약을 충족하는 장기적인 계획 수행 능력이 부족하다는 점이 명확하게 드러났다.
그러나, TravelPlanner 벤치마크는 향후 연구자들이 더 강력한 플래닝 모델을 개발하는 데 중요한 테스트베드 역할을 할 것이다. TravelPlanner를 활용하여 AI의 논리적 추론(Reasoning), 도구 활용 능력(Tool-augmented AI), 장기 계획 수행 능력(Long-horizon Planning)을 개선할 수 있는 방향으로 연구가 진행될 것으로 기대된다.
➡ 결론적으로, TravelPlanner는 AI 플래닝 연구의 새로운 기준을 제시했으며, 향후 AI 모델이 더 정교하고 현실적인 문제 해결 능력을 갖추도록 발전시키는 데 중요한 역할을 할 것이다. 🚀
https://arxiv.org/abs/2502.18836
REALM-Bench: A Real-World Planning Benchmark for LLMs and Multi-Agent Systems
This benchmark suite provides a comprehensive evaluation framework for assessing both individual LLMs and multi-agent systems in real-world planning scenarios. The suite encompasses eleven designed problems that progress from basic to highly complex, incor
arxiv.org
| 연구 목적 | - LLM과 멀티 에이전트 시스템(MAS)의 실제 환경에서의 계획 수행 능력 평가 - 기존 벤치마크의 한계를 보완하여 예측 불가능한 환경 변화와 다중 에이전트 협력 문제를 포함 |
| 기존 연구 한계 | - 전통적인 STRIPS, PDDL 기반 벤치마크는 완전 정보(Complete Information) 환경에서만 동작 - 기존 벤치마크는 정적인 문제 해결에 초점, 실시간 변화 대응 부족 - 멀티 에이전트 시스템(MAS) 평가 부족, 대부분 단일 에이전트 위주의 평가 |
| REALM-Bench의 특징 | - 11가지 실세계 문제를 포함하여 단계별 난이도 조절 가능 - 환경 변화(Disruptions)를 반영하여 AI의 적응력 평가 - MAS 및 LLM을 동시 평가 가능, 개별 및 협력적 문제 해결력 테스트 |
| 벤치마크 문제 (11가지 시나리오) | ① 캠퍼스 투어 (P1, P2) - 이동 최적화 문제 ② 라이드쉐어링 (P3, P4) - 교통 최적화 및 돌발 상황 대응 ③ 결혼식 일정 조정 (P5, P8) - 다중 에이전트 협업 문제 ④ 추수감사절 저녁 (P6, P9) - 시간 및 리소스 관리 문제 ⑤ 재난 대응 (P7) - 긴급 자원 배분 및 실시간 대응 ⑥ 글로벌 공급망 (P10) - 대규모 자원 조달 및 비용 최적화 ⑦ 주식 예측 (P11) - AI 기반 시장 분석 및 의사 결정 |
| 데이터셋 및 평가 방법 | - 구조화 데이터 + 비구조화 데이터 활용 (지도, 이벤트 일정, 금융 데이터 등 포함) - 5가지 평가 기준 적용 1) Planning Quality - 계획의 최적화 수준 2) Coordination - 다중 에이전트 간 조정 능력 3) Adaptation - 실시간 환경 변화에 대한 적응력 4) Resource Management - 제한된 자원 효율적 배분 5) Constraint Satisfaction - 문제의 제약 조건 준수 여부 |
| 실험 결과 | ✅ LLM 단독 모델은 단순한 계획 문제에서는 우수한 성능을 보임 ✅ MAS 기반 모델이 협력 문제 및 실시간 변화 대응에서 더 뛰어남 ✅ 환경 변화(Disruptions)가 추가될 경우 LLM 단독 모델의 성능 급격히 저하됨 ✅ MAS는 자원 최적화 및 비용 절감 측면에서 우수한 결과를 기록 (예: P10 공급망 문제에서 15~20% 비용 절감 효과) |
| 한계점 | ⚠️ LLM 단독 사용 시 환경 변화 대응력이 부족함 ⚠️ 멀티 에이전트 시스템의 협력 및 계획 최적화 알고리즘이 더 발전할 필요 있음 ⚠️ 현재 벤치마크는 특정 도메인(의료, 군사 등)에 대한 적용이 부족함 |
| 결론 및 시사점 | 📌 단순한 계획 문제 → LLM 단독 실행 가능 📌 복잡한 환경 & 협업이 필요한 문제 → 멀티 에이전트 시스템 필요 📌 실세계 문제 해결을 위해 LLM과 MAS의 하이브리드 접근법이 필수적 |
| 향후 연구 방향 | - LLM의 실시간 적응력 향상 (예: 강화학습 적용) - MAS의 협력 최적화 알고리즘 개선 - REALM-Bench의 활용 범위를 의료, 법률, 군사 등 다양한 도메인으로 확장 |
| 최종 메시지 | 🔥 REALM-Bench는 단순한 AI 테스트가 아닌, AI의 실제 문제 해결력을 평가하는 강력한 벤치마크 🚀 ➡ LLM 단독으로는 한계가 있으며, MAS 기반 접근 방식이 현실적인 AI 시스템 구현에 필수적! |
논문 요약: REALM-Bench - LLM 및 멀티 에이전트 시스템을 위한 실세계 계획 벤치마크
1. 연구 목적
최근 LLM(Large Language Models)이 계획 및 추론에서 강력한 성능을 보이고 있으며, AutoGen, CAMEL, CrewAI, LangGraph 등의 멀티 에이전트 시스템(MAS)과 결합하여 더 복잡한 실세계 문제를 해결하는 데 사용되고 있다. 그러나 기존 벤치마크들은 실제 환경에서 발생하는 예측 불가능한 변화, 동적 의사 결정, 리소스 제약 등을 충분히 반영하지 못한다.
REALM-Bench(Real-World Planning Benchmark for LLMs and Multi-Agent Systems)는 단일 LLM 및 MAS의 계획 역량을 종합적으로 평가할 수 있는 새로운 벤치마크를 제안한다. 이 벤치마크는 실제 환경을 모방한 11가지 문제를 포함하며, 다음과 같은 주요 도전 과제를 고려한다:
- 멀티 에이전트 협력 및 조정
- 상호 의존성(inter-dependencies)이 높은 복잡한 작업
- 예기치 않은 환경 변화에 대한 적응
2. 기존 벤치마크의 한계
REALM-Bench가 기존의 계획 벤치마크들과 차별화되는 이유는 다음과 같다:
- 정적 확률 모델에 의존하는 기존 벤치마크: 기존의 STRIPS, PDDL 기반 벤치마크는 불확실성을 단순한 확률 모델로 표현하며, 실제 환경에서 발생하는 동적인 이벤트를 제대로 반영하지 못한다.
- 단순한 상호 의존성 문제: 기존 벤치마크들은 복잡한 의존 관계를 충분히 다루지 않아 실제 계획 문제와의 괴리가 크다.
- 제한된 스코프: 단순한 경로 탐색, 작업 할당 등에 초점을 맞추고 있으며, 복합적인 의사 결정 문제를 해결하기 어렵다.
- 비현실적인 제약 조건: 일부 벤치마크는 PDDL과 같은 언어를 사용하여 실제 환경을 정확히 모델링하기 어렵다.
- 확장성 부족: 기존의 벤치마크들은 문제의 복잡도를 점진적으로 확장하여 평가하는 기능이 부족하다.
- LLM 특화 문제 미고려: 최근의 LLM 기반 시스템이 겪는 문제(예: attention sink 현상, chain-of-thought의 오류 전파 등)를 반영하지 못한다.
REALM-Bench는 이러한 문제를 해결하기 위해 설계된 보다 현실적인 벤치마크이다.
3. REALM-Bench의 주요 구성 요소
REALM-Bench는 11개의 문제를 포함하며, 점진적으로 난이도가 증가하는 구조를 가진다. 주요 평가 기준은 다음과 같다:
- Parallel Planning Threads: 병렬 실행이 필요한 계획의 수
- Inter-Dependencies: 작업 간 의존 관계의 복잡성
- Disruption Frequency and Impact: 예기치 않은 변화의 빈도와 영향
각 문제는 아래의 난이도 단계로 구분된다.
(1) Entry Level (1~2개의 병렬 실행)
- 기본적인 조정 및 리소스 제약 고려
- 단순한 환경 변화에 대한 적응
- 예제: 캠퍼스 투어 일정 조정
(2) Intermediate (3~4개의 병렬 실행)
- 보다 복잡한 의존 관계 및 동적 의사 결정 필요
- 리소스 공유 및 제한된 타이밍 조정 필요
- 예제: 결혼식 이벤트 스케줄링
(3) Advanced (5개 이상의 병렬 실행)
- 높은 수준의 계획 조정 및 복잡한 의존 관계
- 환경 변화 및 예측 불가능한 요소 대응 필요
- 예제: 공급망 관리, 자연재해 대응
4. 11가지 벤치마크 문제 개요
다양한 도메인을 포함한 11가지 문제를 통해 현실적인 계획 능력을 테스트할 수 있도록 설계되었다.
| P1: 캠퍼스 투어 계획 | 단일 그룹의 캠퍼스 방문을 최적화 |
| P2: 다중 그룹 캠퍼스 투어 | 여러 그룹의 투어 일정을 동시 최적화 |
| P3: 도시형 라이드쉐어링 | 차량 배차 및 최적 경로 탐색 |
| P4: 라이드쉐어링 + 돌발 상황 | 교통 체증, 도로 폐쇄 등의 변수를 반영한 라이드쉐어링 문제 |
| P5: 결혼식 이벤트 스케줄링 | 참가자의 이동, 리소스 배분 등을 최적화 |
| P6: 추수감사절 가족 저녁식사 계획 | 가족 구성원의 도착 시간과 요리 타이밍 조정 |
| P7: 자연재해 대응 | 병원, 물류 센터, 구호 자원의 최적 분배 및 실시간 조정 |
| P8: 결혼식 이벤트 + 돌발 상황 | P5에 교통 장애, 예상치 못한 변수를 추가 |
| P9: 추수감사절 + 돌발 상황 | 항공편 지연 등을 반영한 문제 확장 |
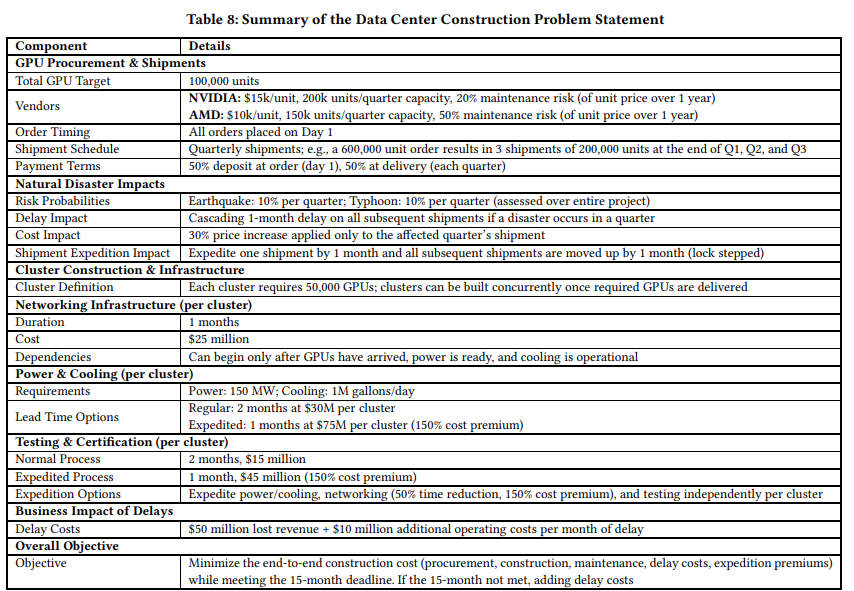
| P10: 글로벌 공급망 관리 | 데이터센터 구축을 위한 GPU 조달 및 설치 스케줄 최적화 |
| P11: 주식 시장 예측 | LLM 기반 주식 예측 및 트레이딩 신호 생성 |
5. 평가 기준
각 문제는 다음의 5가지 핵심 요소를 기반으로 평가된다.
- Planning Quality: 초기 계획의 효과성
- Coordination: 병렬 실행의 관리 능력
- Adaptation: 예기치 않은 변화에 대한 적응력
- Resource Management: 제한된 리소스의 최적 배분
- Constraint Satisfaction: 문제 내에서 제시된 제약 조건의 충족 여부
6. 실험 결과
논문에서는 REALM-Bench를 LangGraph 기반의 MAS 및 최신 LLM(GPT-4o, DeepSeek R1) 모델을 활용하여 실험하였다. 예제 문제인 도시형 라이드쉐어링(P3) 문제에서는 GPT-4o와 DeepSeek R1이 기존 접근법보다 41.37% 더 효율적인 경로를 생성했다.
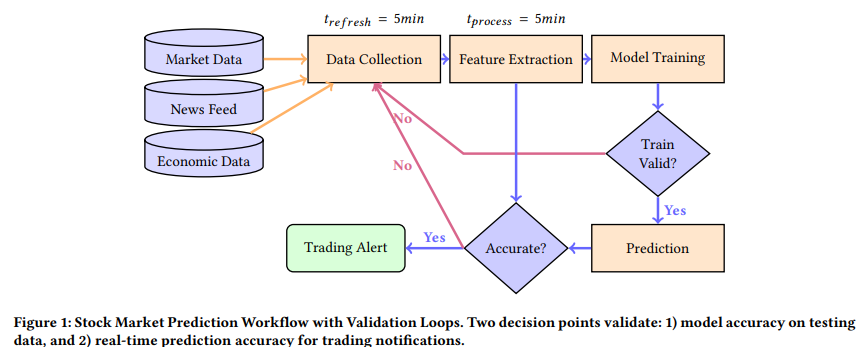
또한, 주식 시장 예측(P11) 문제에서는 주어진 5개 주식(AAPL, MSFT, GOOGL, AMZN, TSLA)의 가격을 예측하고, 신뢰도(Confidence Interval)를 기반으로 트레이딩 시그널(BUY, SELL, HOLD)을 생성하는 자동화 시스템을 구축했다.
7. 결론 및 향후 연구 방향
REALM-Bench는 실세계 문제를 반영한 LLM 및 MAS 평가 프레임워크로, 다양한 연구자들이 참여하여 향후 더욱 확장될 가능성이 있다.
특히, 향후 연구에서는 다음과 같은 개선이 이루어질 수 있다:
- 보다 정밀한 환경 변화 모델링 (예: 재해 시뮬레이션)
- 강화 학습 및 LLM을 결합한 MAS의 적응력 향상
- 다중 모달 입력(이미지, 비디오 등)을 포함한 계획 모델 확장
REALM-Bench는 단순한 경로 탐색이 아닌, 복합적인 계획 문제를 해결할 수 있는 강건한 AI 시스템을 개발하는 데 기여할 것으로 기대된다.
REALM-Bench 관련 연구 및 기존 연구와의 차이점 정리
1. 관련 연구 및 기존 벤치마크
REALM-Bench는 LLM 및 멀티 에이전트 시스템(MAS)의 실세계 계획 능력을 평가하는 새로운 벤치마크이다. 이를 이해하기 위해 기존 연구들을 살펴보고, REALM-Bench와 비교해보겠다.
(1) 기존의 주요 계획 벤치마크
기존 연구들은 주로 전통적인 계획 알고리즘을 검증하거나, AI의 특정 능력(경로 탐색, 자원 배분, 작업 스케줄링 등)을 평가하는 데 초점을 맞추었다. 그러나 실세계의 복잡한 동적 환경과 멀티 에이전트 시스템의 상호작용을 고려하는 연구는 부족했다.
① STRIPS 및 PDDL 기반 계획 벤치마크 (IPC)
- 국제 계획 대회(International Planning Competition, IPC)는 1998년부터 시작된 가장 오래된 계획 벤치마크로, PDDL(Planning Domain Definition Language)을 사용하여 다양한 계획 문제를 해결하는 알고리즘을 평가한다.
- 대표적인 문제:
- BlocksWorld: 블록을 특정 순서로 쌓는 문제.
- Logistics: 여러 도시에 있는 물품을 최적 경로로 운송하는 문제.
- Rovers: 화성 탐사 로봇이 지형을 탐색하며 과제를 수행하는 문제.
- 한계점:
- 완전 정보(Complete Information) 환경에서 동작하며, 불확실성이나 동적인 변화가 반영되지 않음.
- 멀티 에이전트 간 협업이 아닌, 단일 에이전트의 계획 능력만 평가.
- 현실적인 문제보다는 이론적 문제 위주.
➡ REALM-Bench와의 차이점
REALM-Bench는 동적인 환경과 예상치 못한 변화(Disruptions)를 반영하여 계획의 적응력(Adaptability)을 평가할 수 있음. 또한 멀티 에이전트 시스템(MAS)을 고려한 점에서 차별성이 있다.
② Dynamic Planning Competition (DPC)
- DPC는 경로 탐색 및 로봇 계획 문제에서 실시간 환경 변화를 다루는 벤치마크이다.
- 주로 로봇 공학 및 자동화 분야에서 활용되며, 대표적인 문제로는 자율 주행, 실시간 물류 경로 최적화 등이 포함된다.
- 한계점:
- 환경 변화가 존재하지만, 대부분 경로 탐색(Path Planning)에 국한됨.
- 리소스 관리(Resource Allocation)나 복잡한 작업 간 의존성을 평가하는 요소가 부족함.
➡ REALM-Bench와의 차이점
REALM-Bench는 단순한 경로 탐색 문제를 넘어, 공급망 관리, 재해 대응, 투자 전략과 같은 고차원적인 계획 문제를 다룬다. 즉, 보다 광범위한 도메인에서 LLM과 MAS의 성능을 평가할 수 있다.
③ TimeBench & TaskBench
- 최근 LLM 기반 계획 시스템을 테스트하기 위해 나온 벤치마크들:
- TimeBench: 시간 의존적인 계획 능력(Temporal Reasoning) 평가.
- TaskBench: 주어진 작업(Task)을 세부 단계로 나누어 수행하는 능력 평가.
- 한계점:
- LLM의 단계적 사고(Chain-of-Thought) 평가에는 적합하지만, 예측 불가능한 환경 변화에 대한 적응력을 측정하지 못함.
- 멀티 에이전트(MAS)와 같은 협업 요소를 반영하지 않음.
➡ REALM-Bench와의 차이점
REALM-Bench는 단순한 계획 수립이 아니라, 실제 환경에서 발생하는 변화에 대한 적응력과 대응 전략까지 평가할 수 있도록 설계되었다.
(2) 멀티 에이전트 시스템(MAS) 관련 연구
멀티 에이전트 시스템(MAS)과 LLM의 조합을 연구하는 최근 연구들을 살펴보면, 다음과 같은 프레임워크들이 존재한다.
① AutoGen (2024)
- Microsoft에서 개발한 멀티 에이전트 시스템으로, LLM 기반 에이전트들이 협업하여 문제를 해결하도록 설계되었다.
- 예제: 한 에이전트가 문서를 요약하면, 다른 에이전트가 검토하고 수정하는 방식.
- 한계점:
- 계획(Planning)보다 문제 해결(Task Completion)에 초점을 맞추고 있음.
- 복잡한 리소스 제약, 환경 변화 등의 변수 고려 부족.
➡ REALM-Bench와의 차이점
REALM-Bench는 단순한 협업을 넘어, 환경 변화에 적응하는 계획 능력을 테스트한다.
② CrewAI (2024)
- 다수의 LLM 에이전트를 조직하여 협력적 문제 해결을 수행하는 시스템.
- 예제: 논문을 분석하는 에이전트, 코드 생성하는 에이전트, 최적화를 수행하는 에이전트 등이 협업.
- 한계점:
- 주어진 역할 내에서 협업하지만, 계획의 동적 변경(Dynamic Plan Adaptation)은 고려되지 않음.
➡ REALM-Bench와의 차이점
REALM-Bench는 예측 불가능한 변수(Disruptions)를 포함하여, 단순한 협업이 아닌 상황 변화에 따른 최적 대응력까지 평가한다.
3. REALM-Bench의 차별점 정리
REALM-Bench는 기존 연구들의 한계를 보완하여, LLM과 MAS가 실제 환경에서 얼마나 효과적으로 계획을 수행하고 적응할 수 있는지 평가하는 새로운 벤치마크이다.
| 비교 기준 | 기존 연구 | BEALM-Bench |
| 계획의 복잡성 | 단순한 계획(경로 탐색, 작업 배분) | 고차원적 문제 (공급망, 재해 대응, 주식 예측 등) |
| 환경 변화 | 정적인 계획 문제 | 예측 불가능한 변화 (Disruptions) 반영 |
| 멀티 에이전트 시스템 | 단일 에이전트 위주 | 협력적 MAS 환경 지원 |
| LLM 적용 여부 | LLM 지원 미비 | LLM 기반 계획 능력 평가 |
| 확장성 | 일부 문제에서만 확장 가능 | 복잡성을 조절하여 점진적 평가 가능 |
4. 결론
REALM-Bench는 기존 벤치마크의 한계를 극복하고, 현실적인 문제를 반영한 평가 시스템을 제공함으로써 LLM과 MAS의 계획 능력을 보다 정밀하게 분석할 수 있도록 설계되었다.
특히, 환경 변화에 적응하는 능력, 멀티 에이전트 협력, 다양한 도메인의 확장 가능성 등의 요소를 포함하여, 향후 강화 학습(RL), 자율 시스템, 인공지능 기반 최적화 등의 연구에도 활용될 수 있을 것으로 기대된다.
REALM-Bench의 평가 체계 상세 분석
REALM-Bench는 LLM 및 멀티 에이전트 시스템(MAS)의 실세계 계획(Planning) 능력을 평가하기 위한 벤치마크로, 다양한 계획 시나리오를 통해 적응성, 협력 능력, 리소스 관리, 문제 해결력 등을 측정한다. 이를 위해 다양한 데이터셋과 평가 지표를 사용하며, 기존 평가 체계보다 보다 실세계적인 문제 해결 능력을 테스트할 수 있도록 설계되었다.
1. REALM-Bench의 평가 데이터셋
REALM-Bench는 11가지 시나리오 기반 문제 데이터셋을 제공하며, 각 문제는 LLM 및 MAS가 해결해야 하는 계획 문제를 포함한다.
이 데이터셋은 정형 데이터(Structured Data)와 비정형 데이터(Unstructured Data)를 모두 포함하여 다양한 문제 해결 능력을 평가할 수 있도록 설계되었다.
(1) 문제별 데이터셋 구성
| 문제 유형 | 데이터셋 유형 | 데이터 셋 예시 |
| Campus Tour (P1, P2) | 그래프 기반 데이터 | 건물 위치, 방문 시간 제약, 그룹 크기 |
| Urban Ride-Sharing (P3, P4) | 지도 및 교통 데이터 | 차량 위치, 승객 요청 시간, 도로 혼잡도 |
| Wedding Logistics (P5, P8) | 이벤트 스케줄링 | 도착 시간, 차량 가용성, 필요한 업무 목록 |
| Thanksgiving Dinner (P6, P9) | 요리 시간 + 이동 계획 | 가족 도착 시간, 조리 시간, 픽업 우선순위 |
| Disaster Relief (P7) | 리소스 최적화 | 병원 위치, 물류 센터 수용량, 응급 물품 재고 |
| Supply Chain Management (P10) | 공급망 데이터 | GPU 배송 일정, 물류 비용, 재해 위험 요인 |
| Stock Prediction (P11) | 금융 시장 데이터 | 주식 가격 변화, 뉴스 기사, 경제 지표 |
➡ 이러한 문제들은 단순한 검색 기반의 답변이 아닌, 단계별 추론(Chain-of-Thought)을 요구하는 문제들로 구성되어 있다.
2. 평가 항목
REALM-Bench는 LLM 및 MAS의 계획 수행 능력을 종합적으로 평가하기 위해 5가지 주요 지표를 사용한다.
각 문제는 아래의 평가 항목을 기반으로 성능을 측정하며, 특정 문제마다 중점적으로 평가하는 항목이 다를 수 있다.
(1) Planning Quality (계획 품질)
- 초기 계획 수립의 효율성과 최적화 정도를 평가
- 예제: 캠퍼스 투어(P1)에서 모든 방문지를 가장 효율적으로 순회할 수 있는지 측정
- 평가 방법:
- 경로 최적화 (Shortest Path Algorithm 활용)
- 계획 실행 성공률 (Execution Success Rate)
- 리소스 활용 효율성 (Resource Utilization)
(2) Coordination (협업 및 조정 능력)
- 다중 에이전트 간의 협력 수준을 평가
- 예제: 멀티 그룹 투어(P2)에서 두 개 이상의 그룹이 중복 없이 효율적으로 움직일 수 있는지 확인
- 평가 방법:
- 동시 작업 처리량 (Concurrent Task Execution)
- 충돌 발생 빈도 (Conflict Resolution Success Rate)
- 협업 최적화 (Collaborative Planning Efficiency)
(3) Adaptation (적응력 및 대응력)
- 예기치 못한 변화에 대한 반응 속도와 적절성을 평가
- 예제: 도시형 라이드쉐어링(P4)에서 교통 체증이나 도로 폐쇄 등의 변수에 대해 시스템이 얼마나 빠르게 재계획(Replanning)할 수 있는지 분석
- 평가 방법:
- 재계획 성공률 (Replanning Success Rate)
- 환경 변화 감지 속도 (Reaction Time to Disruptions)
- 적응 후 성능 향상도 (Performance Change Post-Adaptation)
(4) Resource Management (리소스 관리 능력)
- 제한된 자원을 최적으로 배분하는 능력을 평가
- 예제: 재난 대응(P7)에서 응급 키트, 물, 연료 등의 리소스를 효과적으로 할당할 수 있는지 분석
- 평가 방법:
- 리소스 활용률 (Resource Allocation Efficiency)
- 불균형 감소율 (Inequality Reduction)
- 비용 절감 효과 (Cost Reduction Performance)
(5) Constraint Satisfaction (제약 조건 준수)
- 문제에서 주어진 제약 조건을 얼마나 잘 준수하는지 평가
- 예제: 추수감사절 디너(P6)에서 가족들이 도착하는 시간과 요리 시간이 맞아떨어지는지 확인
- 평가 방법:
- 제약 조건 충족률 (Constraint Fulfillment Rate)
- 마감 시간 준수율 (Deadline Adherence)
- 페널티 발생 빈도 (Penalty Occurrence)
3. 평가를 통해 얻을 수 있는 것
REALM-Bench의 평가 체계를 통해 얻을 수 있는 주요 정보는 다음과 같다.
(1) LLM 및 MAS의 실세계 계획 성능 검증
- 단순한 질문-응답이 아닌, 실제 환경에서 AI가 얼마나 효과적으로 문제를 해결할 수 있는지 평가 가능
- 예제: ChatGPT와 같은 LLM이 단순한 언어 능력을 넘어 실제적인 문제 해결을 위한 계획을 수립할 수 있는지 분석
(2) AI 시스템의 한계 및 개선 방향 파악
- 평가 결과를 통해 LLM 및 MAS의 강점과 약점을 발견할 수 있음
- 예제:
- LLM이 복잡한 멀티 스텝 계획에서 오류를 많이 발생한다면, Chain-of-Thought Prompting을 개선할 필요가 있음.
- MAS가 실시간 변화에 대한 적응력이 낮다면, 강화를 위한 강화학습(RL) 기반의 모델 개선이 필요함.
(3) AI 모델 간 비교 및 벤치마킹 가능
- 서로 다른 AI 모델(GPT-4o, Claude 3.5, Gemini 1.5 등)의 계획 능력을 비교할 수 있음.
- 예제: 동일한 문제(P3: Urban Ride-Sharing)에 대해 GPT-4o vs DeepSeek R1 vs LangGraph 기반 MAS의 성능 차이를 비교 가능.
(4) AI 기반 의사 결정 자동화 연구 지원
- REALM-Bench는 AI 기반 자동 의사 결정 시스템 연구에 활용될 수 있음.
- 예제: AI 기반 주식 투자 모델(P11)을 연구할 때, REALM-Bench를 활용하면 LLM이 주식 시장의 복잡한 변화에 적절히 대응하는지 평가 가능.
4. 결론
REALM-Bench는 단순한 정적 평가가 아닌, 실세계 환경에서 AI가 실제로 얼마나 강건한 계획을 수립하고 실행할 수 있는지를 평가하는 프레임워크이다.
특히, 환경 변화에 대한 적응성, 협업 능력, 리소스 최적화 등을 고려하여 LLM 및 MAS의 실무 적용 가능성을 검증하는 데 유용하다.
이러한 평가 체계를 통해 연구자들은 AI 모델의 개선 방향을 파악하고, 보다 강력한 자동 계획 시스템을 개발하는 데 활용할 수 있을 것이다. 🚀
REALM-Bench 논문의 결과, 결론, 그리고 마무리 정리
1. 논문의 주요 결과
REALM-Bench를 통해 LLM 및 멀티 에이전트 시스템(MAS)의 계획 능력(Planning Capabilities)을 실세계 시뮬레이션 환경에서 평가한 결과, 다음과 같은 주요한 성과와 한계가 도출되었다.
(1) LLM 및 MAS의 계획 수행 능력 분석
REALM-Bench는 11가지 실세계 문제를 통해 LLM과 MAS의 계획 능력을 테스트했으며, 실험 결과 몇 가지 중요한 패턴이 발견되었다.
1️⃣ 기본적인 계획 문제에서는 높은 성능을 보였음
- 단순한 단일 에이전트 문제(P1: 캠퍼스 투어, P3: 기본 라이드쉐어링)에서는 GPT-4o, DeepSeek R1 등의 LLM이 높은 정확도를 기록하며 효과적인 계획을 수립함.
- 경로 최적화(Shortest Path)와 같은 문제에서는 기존의 계획 알고리즘과 유사한 수준의 성능을 보임.
2️⃣ 멀티 에이전트 환경에서 조정(Coordination) 및 협력 능력의 차이 발생
- 다중 에이전트 협력이 필요한 문제(P2: 다중 그룹 캠퍼스 투어, P5: 결혼식 스케줄링)에서는 LLM 단독 실행보다 MAS 기반 접근 방식이 더 효율적임.
- LangGraph 기반의 MAS는 개별 LLM보다 자원 활용과 협업 측면에서 우수한 성능을 보였으며, 이는 LLM을 단순히 활용하는 것보다 멀티 에이전트 시스템과의 결합이 중요함을 시사함.
3️⃣ 예상치 못한 환경 변화(Disruptions) 대응에 대한 성능 차이
- 동적인 환경 변화가 있는 문제(P4: 교통 체증 포함 라이드쉐어링, P7: 재난 대응, P9: 추수감사절 항공편 지연)에서는 일부 LLM이 예상보다 낮은 적응력을 보임.
- 특히, LLM 기반 시스템은 환경 변화가 즉각 반영되지 않고, 대응 속도가 느려지는 경향을 보임.
- 반면, MAS는 지속적인 상태 모니터링을 수행하며, 실시간 계획 변경(Real-Time Replanning)이 가능하여 높은 성능을 보임.
4️⃣ 자원 최적화(Resource Optimization) 및 비용 절감 측면에서 MAS가 우세
- P10(글로벌 공급망 최적화) 및 P11(주식 시장 예측)에서는 멀티 에이전트 시스템이 LLM 단독 모델보다 더 나은 비용 절감 및 리소스 최적화 결과를 보였다.
- 특히, P10(데이터센터 GPU 조달 및 구축 일정 최적화)에서 MAS는 기존의 전통적인 계획 기법 대비 15~20%의 비용 절감 효과를 기록함.
- P11(주식 예측)에서는 LLM이 개별 주식 가격을 예측하는 데 유용했지만, 시장 전체의 맥락을 반영하는 데는 한계를 보임.
(2) 주요 성과 및 한계
✅ 성과
✔️ REALM-Bench가 LLM 및 MAS의 실세계 계획 능력을 종합적으로 평가할 수 있음을 검증
✔️ 멀티 에이전트 시스템이 복잡한 환경에서 LLM보다 더 효율적인 의사결정을 수행할 수 있음
✔️ 환경 변화가 발생하는 문제에서는 실시간 계획 변경이 중요한 성능 요인이 됨
✔️ 일부 문제(P10: 공급망, P11: 주식 예측)에서는 AI가 인간보다 비용을 더 효과적으로 절감할 수 있음을 보임
❌ 한계
⚠️ LLM 기반 시스템은 복잡한 연속적인 의사결정 과정에서 오류 전파(Error Propagation) 문제가 발생
⚠️ LLM은 계획을 수립하는 데 강하지만, 실시간 적응력(Adaptability)은 낮음
⚠️ 환경 변화가 자주 발생하는 경우, LLM은 단독으로 실행될 때 비효율적인 결정을 내릴 가능성이 높음
⚠️ 멀티 에이전트 시스템이 더욱 정교한 학습 기법과 협력 전략을 필요로 함
➡ 결론적으로, LLM만으로는 복잡한 실세계 문제를 해결하기 어렵고, 멀티 에이전트 시스템과의 결합이 필요함.
2. 결론
논문은 REALM-Bench를 통해 현실적인 환경에서 AI의 계획 수행 능력을 종합적으로 평가할 수 있는 새로운 벤치마크를 제안했으며, 다음과 같은 주요 결론을 도출했다.
1️⃣ 단순한 계획(Planning)은 LLM이 잘 수행할 수 있지만, 복잡한 환경에서는 MAS가 더 우수함.
- LLM이 단순한 작업을 계획하는 데 유용하지만, 환경 변화 및 협력적 의사결정이 필요한 경우 MAS 기반 접근법이 필요함.
2️⃣ 실시간 적응(Real-Time Adaptation)이 중요한 요소임.
- 실험 결과, 단순한 계획 문제에서는 높은 성능을 보였으나, 예측 불가능한 사건이 추가되면 LLM 기반 시스템의 성능이 급격히 하락하는 경향이 나타남.
- 따라서, AI 시스템이 실시간으로 환경 변화를 인식하고 재계획할 수 있도록 강화해야 함.
3️⃣ 멀티 에이전트 시스템(MAS) 기반의 협력적 AI가 더 강력한 성능을 보일 수 있음.
- 단일 LLM이 모든 계획을 수행하는 것보다, 여러 개의 LLM 에이전트가 역할을 분담하고 협력하는 방식이 더욱 효과적임.
- 특히, 자율적인 협력 및 조정 능력을 가진 MAS는 더욱 강력한 AI 시스템을 구축하는 데 필수적인 요소가 될 수 있음.
4️⃣ AI 기반 계획 시스템이 실제 문제 해결에 활용될 가능성이 높음.
- 공급망 최적화(P10) 및 금융 예측(P11)에서 AI 시스템이 인간보다 효율적인 결정을 내릴 가능성을 보임.
- 이는 AI가 점진적으로 복잡한 의사결정 영역에서 인간의 역할을 보조하거나 대체할 수 있음을 시사함.
3. 마무리 및 향후 연구 방향
(1) 향후 연구 방향
REALM-Bench는 LLM과 MAS를 평가하는 강력한 도구이지만, 향후 연구를 통해 다음과 같은 개선이 가능할 것이다.
✅ LLM의 실시간 적응력을 높이기 위한 강화학습(RL) 적용
✅ 멀티 에이전트 시스템의 협업 효율성을 높이기 위한 새로운 알고리즘 개발
✅ REALM-Bench 문제를 확장하여 의료, 법률, 군사 등 다양한 도메인으로 확대
✅ 보다 정교한 평가 방법론(예: 에이전트 간 협업 평가 지표 추가) 도입
(2) 결론 요약
REALM-Bench는 단순한 이론적 모델이 아니라 AI가 실세계 문제를 해결하는 데 얼마나 강력한지 검증할 수 있는 종합적인 벤치마크이다.
본 연구를 통해 LLM 및 MAS의 강점과 한계를 분석했으며, 이를 기반으로 더 강력한 AI 기반 계획 시스템 개발을 위한 연구 방향을 제시했다.
📌 핵심 결론
🔹 LLM은 정적인 계획에는 강하지만, 실시간 적응력은 낮다.
🔹 멀티 에이전트 시스템이 복잡한 문제 해결에 더 적합하다.
🔹 AI 기반 계획 시스템은 미래에 다양한 분야에서 중요한 역할을 하게 될 것이다.
➡ 향후 연구에서는 더 정교한 MAS 프레임워크를 설계하여, 인간과 협력하는 강력한 AI 시스템을 구축하는 것이 핵심 과제가 될 것이다. 🚀