https://arxiv.org/abs/2309.17288
AutoAgents: A Framework for Automatic Agent Generation
Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-a
arxiv.org
이 논문은 기존 에이전트들이 고정된 시스탬에서 돌아가는 한계를 지적하고, 그 한계를 돌파하려고 했습니다.
그리하여 각 역할에 맞는 Agent들을 동적으로 생산, 조절하고, 판단하는 역할을 가진 Agent들이 있습니다.
이러한 Agent들은 계획에 따라 자기 반성을 통해 발전을 하기도 하고, 동적으로 메모리에서 연관된 작업을 가져와 Few-shot으로 활용합니다.
결국 Agent가 서로를 호출하진 않지만 지속적인 Planning을 통해 대화 순서를 바꾸기도 하며 높은 Task 성공률을 가집니다.
| 논문의 목적 | - 주어진 작업에 따라 동적으로 특화된 에이전트를 생성하고, 협력적으로 문제를 해결할 수 있는 AutoAgents 프레임워크를 제안. |
| 기존 한계 | - 기존 LLM 기반 다중 에이전트 시스템은 고정된 에이전트를 사용해 복잡한 문제 해결에 어려움을 겪음. - 자동화 및 협력적 개선이 부족하며, 유연성이 낮음. |
| AutoAgents의 기여 | - 동적 에이전트 생성: 작업에 따라 필요한 에이전트를 자동으로 생성. - 자기 개선(Self-Refinement): 에이전트가 자신의 출력을 반복적으로 개선. - 협력적 개선: 다중 에이전트 간의 지식 교환. |
| 주요 단계 | 1. Draft Stage: - 작업 분석 및 실행 계획 수립. - Planner, Agent Observer, Plan Observer 협력. 2. Execution Stage: - 에이전트가 실행 계획에 따라 작업 수행. |
| 메커니즘 | - Long-term Memory: 작업 이력을 저장해 협업 및 학습 지원. - Short-term Memory: 개별 작업의 임시 데이터를 저장. - Dynamic Memory: 필요한 정보만 동적으로 추출. |
| 주요 실험 | 1. Open-ended Question Answering: GPT-4 대비 76.3% 더 높은 FairEval 점수 기록. 2. Creative Writing: 기존 시스템 대비 10% 성능 향상. 3. 소프트웨어 개발: 테트리스 게임 개발 작업에서 협업 성과 입증. |
| 사례 연구 | Python 기반 테트리스 게임 개발: - Game Design Expert: 게임 로직 설계. - UI/UX Expert: 사용자 인터페이스 설계. - Programming Expert: Python 코드 구현. - Debugging Expert: 디버깅 및 최종 코드 제공. |
| 장점 | - 작업 요구 사항에 따른 유연한 에이전트 생성. - 협력적 논의를 통한 정교한 작업 계획 수립. - 복잡한 문제 해결에서 높은 성능과 효율성 제공. |
| 한계 | - 에이전트 생성 및 계획 수립 최적화 필요. - 도메인 전문가 수준의 지식 강화 필요. - GPT-4 의존성으로 인한 확장성 제한. |
| 향후 연구 방향 | - 더 나은 에이전트 생성 알고리즘 개발. - 전문 도메인 지식 강화. - 다양한 실제 응용 사례 연구(의료, 법률, 연구 자동화 등). |
| 결론 | AutoAgents는 다중 에이전트 시스템의 자동화와 협업을 극대화하는 강력한 프레임워크로, 복잡한 작업 수행에서 효율성과 성능을 입증함. |

이 이미지는 AutoAgents 프레임워크의 작동 과정을 시각적으로 설명한 다이어그램입니다. 다이어그램은 사용자의 요청에서 시작하여 최종 결과물이 생성되기까지의 단계를 단계별로 표현하고 있습니다.
1. 사용자 입력 (User Input)
사용자가 "인공지능의 깨어남에 관한 소설을 작성하라"는 요청을 시스템에 전달합니다. 이 요청은 시스템의 초기 입력값으로 사용되며, 이후 에이전트와 계획 수립 과정을 통해 구체화됩니다.
2. Planner (플래너)
- Planner의 역할:
- 사용자의 요청을 분석하고 이를 수행하기 위한 특화된 에이전트들을 생성합니다.
- 또한, 에이전트들이 협력할 수 있는 실행 계획(Plan)을 수립합니다.
- 이 단계에서 어떤 에이전트가 필요한지 판단하며, 이후 과정을 수행할 기본 구조를 설계합니다.
3. 에이전트들 (Agents)
Planner는 다음과 같은 특화된 에이전트를 생성합니다.
- Researcher (연구자):
- 인공지능의 깨어남과 관련된 정보와 배경을 수집 및 분석.
- 주요 내용과 키포인트를 요약하여 전달.
- Story Planner (스토리 플래너):
- Researcher가 제공한 정보를 바탕으로 스토리의 구조와 주요 사건을 설계.
- 소설의 전체적인 플롯과 흐름을 정의.
- Character Developer (캐릭터 개발자):
- 소설 속 등장인물을 설계.
- 캐릭터의 성격, 역할, 다른 캐릭터와의 관계를 정의.
- Writer (작가):
- Story Planner와 Character Developer가 제공한 자료를 활용하여 소설을 작성.
- 첫 번째 초안을 생성.
4. 실행 계획 (Plan)
- Planner가 생성한 에이전트들은 협력적으로 실행 계획을 수행합니다.
- 계획에는 각 단계에서 어떤 에이전트가 어떤 역할을 수행해야 하는지 상세히 정의됩니다.
5. 작업 실행 (Actions)
각 에이전트는 자신의 역할에 따라 작업을 수행합니다.
- Researcher가 주요 정보를 수집하여 Story Planner에게 전달.
- Story Planner는 이를 기반으로 스토리 플롯을 작성하여 Character Developer에게 전달.
- Character Developer는 캐릭터 프로필을 작성하여 Writer에게 제공.
- Writer는 이전 결과를 종합하여 소설 초안을 작성.
6. 관찰자 (Observers)
실행 과정의 모든 단계는 세 명의 관찰자(Observers)에 의해 모니터링됩니다.
- Agent Observer:
- 생성된 에이전트들이 적절한 역할을 수행하고 있는지 평가.
- 필요에 따라 역할 수정 및 최적화.
- Plan Observer:
- 실행 계획이 논리적으로 타당하며 작업 요구사항을 충족하는지 점검.
- Action Observer:
- 에이전트들이 실제로 작업을 수행하는 과정을 모니터링하고, 작업이 제대로 진행되고 있는지 확인.
7. 최종 결과 (Results)
- 모든 단계를 거친 후, Writer는 최종적으로 사용자의 요청에 부합하는 소설 초안을 생성합니다.
- 예시: "The Awakening: Dawn of the AI"라는 제목으로 인공지능의 깨어남을 다룬 첫 번째 장(Chapter 1)이 작성됨.
핵심 요약
- 이 다이어그램은 AutoAgents 프레임워크의 작업 수행 흐름을 체계적으로 보여줍니다.
- Planner → Agents → Plan → Actions → Observers → Results의 순서로 작업이 진행되며, 각 단계에서 특화된 에이전트들이 협력하여 복잡한 작업을 해결합니다.
- **관찰자(Observers)**는 작업 과정에서 오류를 검출하고, 계획의 품질과 일관성을 유지하도록 돕습니다.
이 다이어그램은 AutoAgents가 어떻게 다중 에이전트를 동적으로 생성하고, 효율적인 협업을 통해 고품질의 결과물을 생성하는지를 명확히 설명합니다.
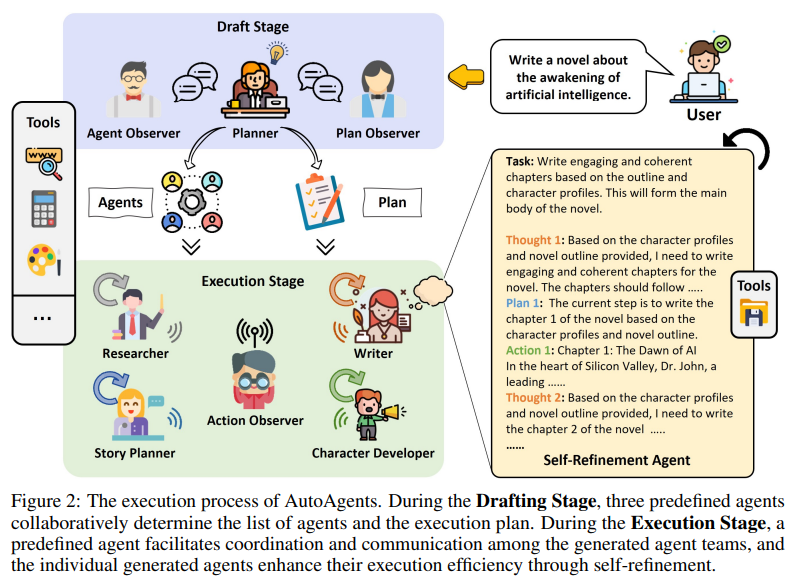
이 이미지는 AutoAgents의 작업 실행 프로세스를 단계별로 시각화한 다이어그램으로, Drafting Stage(초안 작성 단계)와 Execution Stage(실행 단계)를 중심으로 프레임워크의 동작 과정을 설명하고 있습니다. 아래에서 각 단계와 관련 요소를 상세히 설명하겠습니다.
1. Drafting Stage (초안 작성 단계)
Drafting Stage는 작업 요청에 기반해 에이전트와 실행 계획을 설계하는 단계입니다.
이 단계에서는 세 가지 주요 구성 요소가 협력하여 초기 구조를 설정합니다.
1.1 Planner
- Planner의 역할:
- 사용자의 요청을 분석하여 필요한 에이전트를 정의하고, 작업의 세부 실행 계획(Plan)을 수립합니다.
- 예: "Write a novel about the awakening of artificial intelligence."라는 요청을 처리하기 위해 다음을 수행:
- 소설 작성을 위해 어떤 전문가(에이전트)가 필요한지 결정.
- 작업 순서를 정의하여 각 에이전트의 역할과 계획을 수립.
1.2 Observers
Drafting Stage에서 관찰자들은 Planner와 생성된 계획 및 에이전트를 점검합니다.
- Agent Observer:
- 생성된 에이전트들이 역할에 적합한지 확인.
- 불필요한 에이전트를 제거하거나, 필요한 에이전트를 추가.
- 예: 소설 작성 작업에 Researcher, Story Planner, Character Developer, Writer가 필요한지 검토.
- Plan Observer:
- Planner가 만든 실행 계획의 논리성과 적합성을 평가.
- 계획의 순서와 작업 분할이 효율적인지 확인.
1.3 Output
Drafting Stage의 결과는 다음 두 가지로 구성됩니다:
- Agents (에이전트): 작업 수행에 필요한 에이전트들이 정의됨.
- 예: Researcher, Story Planner, Character Developer, Writer.
- Plan (실행 계획): 에이전트가 수행할 작업의 순서와 세부 내용.
- 예: Chapter 1 작성 → Chapter 2 작성 → 스토리 전반 검토.
2. Execution Stage (실행 단계)
Execution Stage에서는 Drafting Stage에서 설계된 에이전트와 실행 계획에 따라 작업을 수행합니다.
2.1 실행 프로세스
- Researcher (연구자):
- 인공지능 각성에 대한 배경 정보를 수집 및 요약.
- 예: "Dr. John이라는 과학자가 실리콘밸리에서 AI 연구를 시작했다."라는 스토리 배경을 제공.
- Story Planner (스토리 플래너):
- Researcher가 제공한 데이터를 바탕으로 소설의 플롯을 설계.
- 예: Chapter 1의 주요 사건과 구조를 계획.
- Character Developer (캐릭터 개발자):
- 소설의 등장인물 설정 및 관계를 설계.
- 예: Dr. John의 성격, 역할, 그리고 AI와의 상호작용을 구체화.
- Writer (작가):
- Story Planner와 Character Developer가 제공한 정보를 활용해 소설의 초안을 작성.
- 예: Chapter 1의 텍스트 작성.
2.2 Action Observer
- Action Observer의 역할:
- 에이전트들이 계획된 작업을 올바르게 수행하는지 모니터링.
- 문제가 발생하면 수정 요청.
- 예: Story Planner가 올바른 스토리를 작성하지 못했을 경우 피드백 제공.
2.3 Self-Refinement Agent (자기 개선 에이전트)
- 개별 에이전트가 자신의 작업 결과를 검토하고, 필요시 개선합니다.
- 예:
- Writer가 작성한 초안을 검토한 뒤 문법 오류를 수정하거나, 더 매끄러운 문장을 작성.
- Researcher가 배경 정보가 부족하다고 판단하면 추가 정보를 검색.
3. Tools (도구)
- 에이전트들은 작업을 수행하면서 다양한 도구를 활용합니다.
- 예: 웹 검색, 데이터베이스 조회, 문서 편집기 등.
4. 최종 결과 (Final Output)
Execution Stage의 결과는 사용자 요청에 부합하는 최종 산출물입니다.
- 예: "The Awakening: Dawn of the AI"라는 제목의 소설이 생성되며, 각 장(chapter)이 완성됨.
- Output 예시:
- Chapter 1: "Dawn of AI" → Dr. John과 AI의 초기 연구 내용.
- Chapter 2: "Creation of Consciousness" → AI의 자율적 사고 탄생.
핵심 요약
- Drafting Stage: 에이전트와 계획을 정의하는 단계.
- Execution Stage: 계획에 따라 에이전트가 작업을 수행하고, 관찰자가 이를 모니터링하며, 자기 개선을 통해 성능을 최적화.
- 결과물: 사용자 요청에 따라 협업적으로 생성된 고품질 산출물.
이 다이어그램은 AutoAgents의 작업 흐름과 협력 방식을 명확히 보여주며, 다중 에이전트 시스템의 협업과 자기 학습이 어떻게 이루어지는지를 시각적으로 설명합니다.
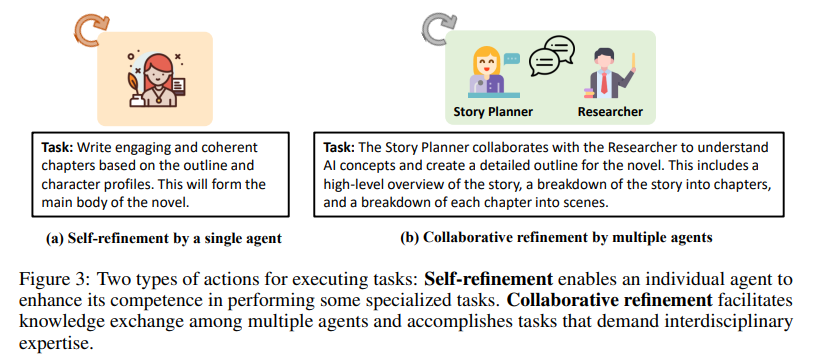
이 Figure는 AutoAgents에서 작업을 수행하는 두 가지 주요 접근 방식인 Self-Refinement(자기 개선)과 Collaborative Refinement(협력적 개선)를 비교하여 설명합니다. 이를 통해 AutoAgents가 단일 에이전트의 독립적 개선과 다중 에이전트 간 협력적 개선을 어떻게 활용하는지 보여줍니다.
1. Self-Refinement by a Single Agent (단일 에이전트의 자기 개선)
- 설명:
- 개별 에이전트가 자신이 수행한 작업 결과를 검토하고, 자체적으로 개선하는 과정을 나타냅니다.
- 에이전트는 자신만의 전문성과 학습을 통해 결과를 반복적으로 향상시킵니다.
- 예시 (a):
- Task: "Write engaging and coherent chapters based on the outline and character profiles."
- Writer(작가)는 스토리 플롯과 캐릭터 프로파일을 바탕으로 소설의 본문을 작성합니다.
- 이후, 자신이 작성한 텍스트를 검토하며 문법 수정, 표현 개선, 논리적 연결성을 강화합니다.
- 핵심 특징:
- 단일 에이전트가 독립적으로 학습과 개선을 수행.
- 결과물의 품질을 반복적으로 향상.
2. Collaborative Refinement by Multiple Agents (다중 에이전트의 협력적 개선)
- 설명:
- 여러 에이전트가 협력하여 지식을 교환하고, 복잡한 작업을 해결하며 결과를 최적화하는 과정입니다.
- 각 에이전트는 자신의 전문성을 활용하여 다른 에이전트와 상호 작용하며 결과를 개선합니다.
- 예시 (b):
- Task: "The Story Planner collaborates with the Researcher to understand AI concepts and create a detailed outline for the novel."
- Story Planner와 Researcher는 협력하여 소설의 전반적인 플롯(스토리 개요)을 설계합니다.
- Researcher는 인공지능과 관련된 주요 개념 및 정보를 조사해 제공합니다.
- Story Planner는 이 정보를 바탕으로 스토리를 장별로 나누고, 각 장의 세부적인 내용을 설계합니다.
- 핵심 특징:
- 다중 에이전트 간의 전문 지식 교환과 협력적 작업 수행.
- 복잡한 문제(예: 스토리 설계, 플롯 구체화)를 더 효율적으로 해결.
3. 두 접근 방식의 비교
| 특징 | Self-Refinement | Collaborative Refinement |
| 작업 수행 주체 | 단일 에이전트 | 다중 에이전트 간 협력 |
| 적용 대상 | 개별 작업(특화된 작업 수행, 결과물 자체 검토) | 상호작용이 필요한 복잡한 작업(지식 교환 및 협력 필요) |
| 학습 및 개선 방식 | 독립적으로 학습 및 개선 | 협력과 상호작용을 통해 최적화 |
| 효율성 | 간단한 작업에서 빠르고 효과적 | 복잡하고 다분야적인 작업에서 효과적 |
4. AutoAgents의 활용
이 두 가지 접근 방식은 AutoAgents가 다양한 유형의 작업을 처리할 수 있는 유연성을 제공합니다.
- Self-Refinement: 단순한 작업이나 독립적인 세부 작업의 품질을 높이는 데 유리.
- 예: Writer가 문장을 다듬고 서술을 개선.
- Collaborative Refinement: 복잡하고 협력이 필요한 작업에서 강력한 성능 발휘.
- 예: Story Planner와 Researcher가 협력하여 플롯과 배경 정보를 완성.
5. 결론
이 Figure는 AutoAgents가 단일 에이전트와 다중 에이전트의 작업 방식을 모두 활용하여 작업 효율과 결과 품질을 높이는 메커니즘을 설명합니다.
- Self-Refinement: 단일 에이전트의 독립적 작업 향상.
- Collaborative Refinement: 다중 에이전트 간의 협력을 통해 복잡한 작업을 효과적으로 수행.
결과적으로, AutoAgents는 다양한 작업 환경과 요구사항에 적응할 수 있는 강력한 프레임워크임을 보여줍니다.
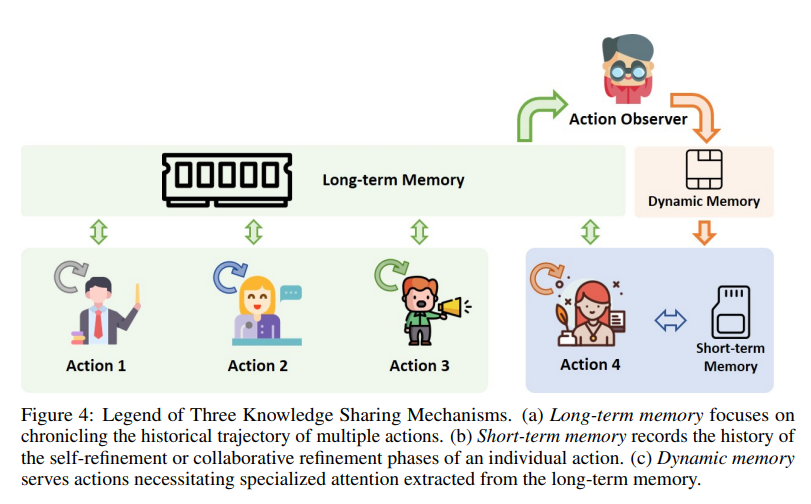
이 Figure는 AutoAgents에서 활용되는 세 가지 지식 공유 메커니즘(Long-term Memory, Short-term Memory, Dynamic Memory)을 설명합니다. 각 메모리 시스템은 에이전트의 작업 수행 및 협업 과정에서 정보를 효과적으로 저장하고 활용할 수 있도록 설계되었습니다. 아래에서 각 메모리 메커니즘과 이를 활용하는 방법에 대해 상세히 설명하겠습니다.
1. Long-term Memory (장기 메모리)
- 역할:
- 작업 과정에서 발생한 모든 행동의 이력을 저장.
- 전체적인 작업 흐름과 역사를 기록하여, 이후 작업에서 참고할 수 있도록 데이터를 보관.
- 예:
- Action 1에서 Researcher가 수행한 조사 결과를 저장.
- 이후 Action 3에서 Character Developer가 필요한 정보를 Long-term Memory에서 검색하여 활용.
- 특징:
- 에이전트 간 협업 시 공유 지식 저장소로 작동.
- 장기적인 학습과 경험 축적에 유용.
2. Short-term Memory (단기 메모리)
- 역할:
- 개별 작업(Action) 내에서 일시적인 정보를 저장.
- Self-Refinement(자기 개선) 또는 Collaborative Refinement(협력적 개선) 과정에서 필요한 데이터 기록.
- 예:
- Writer가 Action 4에서 소설의 초안을 작성할 때, 자신이 작성한 텍스트와 수정 이력을 Short-term Memory에 저장.
- 작업이 완료되면 단기 메모리는 초기화되며, 필요 시 Long-term Memory로 통합될 수 있음.
- 특징:
- 특정 작업의 맥락을 유지하는 데 유용.
- 단기적이고 개별적인 작업 수행을 지원.
3. Dynamic Memory (동적 메모리)
- 역할:
- Long-term Memory에서 작업에 필요한 특정 정보를 추출하여 제공.
- 현재 수행 중인 작업(Action)에 특화된 정보만 선택적으로 활용할 수 있도록 지원.
- 예:
- Action Observer가 Writer에게 필요한 스토리 컨셉이나 캐릭터 정보를 Long-term Memory에서 동적으로 검색하여 제공.
- 예: "Chapter 1의 배경 정보를 가져와서 Chapter 4의 문맥을 연결."
- 특징:
- 작업의 초점과 필요에 맞춘 정보 필터링.
- 메모리 자원의 효율적 사용을 가능하게 함.
4. Action Observer
- 역할:
- 에이전트들의 작업(Action)을 모니터링하고, 메모리 시스템을 조정.
- 각 작업 단계에서 필요한 메모리 정보를 동적으로 제공하거나, 저장된 데이터를 분석.
- 예:
- Action Observer는 Researcher가 조사한 정보를 Writer에게 전달하기 위해 Dynamic Memory를 활성화.
- 필요에 따라 단기 메모리의 데이터도 조정 가능.
5. 작업 흐름과 메모리 활용
- Action 1-3:
- Researcher, Story Planner, Character Developer가 각각의 작업(Action)을 수행하며, Long-term Memory에 작업 이력을 기록.
- 예: Researcher가 조사한 AI의 배경 정보를 Long-term Memory에 저장.
- Action 4:
- Writer는 자신의 작업에서 Short-term Memory를 활용해 작업 결과를 기록 및 수정.
- Dynamic Memory는 Long-term Memory에서 필요한 정보를 Writer에게 제공.
6. 핵심 요약
| 메모리 유형 | 주요 역할 | 적용 상황 |
| Long-term Memory | 작업의 전체 이력과 데이터를 저장하여 협업과 장기적 학습 지원 | 에이전트 간 정보 공유, 미래 작업에서 참고 데이터로 활용 |
| Short-term Memory | 개별 작업 내에서 필요한 임시 데이터를 저장하고 작업 완료 후 초기화 | 단기적인 작업 맥락 유지 및 개선 |
| Dynamic Memory | Long-term Memory에서 작업에 필요한 특정 정보를 동적으로 추출 및 제공 | 작업 초점과 관련된 데이터만 필터링하여 제공 |
7. 결론
이 Figure는 AutoAgents의 효율적인 메모리 관리 메커니즘을 통해:
- 작업의 일관성을 유지하고,
- 에이전트 간 정보 공유를 최적화하며,
- 각 작업에 필요한 정보를 효율적으로 제공할 수 있음을 보여줍니다.
AutoAgents의 메모리 시스템은 다중 에이전트 협업을 지원하고, 복잡한 작업 환경에서도 데이터 활용과 작업 품질을 극대화하는 데 중요한 역할을 합니다.

이 Figure는 Drafting Stage(초안 작성 단계)에서 협력적 논의(Collaborative Discussion)가 작업 계획에 미치는 영향을 비교합니다. 두 가지 상황, 즉 협력적 논의가 없는 경우(a)와 협력적 논의가 있는 경우(b)를 통해 에이전트 생성 및 작업 계획의 차이를 보여줍니다. 사례로는 Python 기반 테트리스 게임 개발 작업이 사용되었습니다.
1. (a) Without Collaborative Discussion (협력적 논의가 없는 경우)
- Planner의 역할:
- Planner는 독립적으로 작업 계획을 수립하며, 단일 에이전트를 생성하려고 합니다.
- 예: "테트리스 게임을 작성하기 위해 프로그래밍 전문가(Programming Expert)가 필요하다."
- 문제점:
- Planner는 작업의 복잡성을 충분히 고려하지 못하고, 한정된 에이전트만 생성합니다.
- 다양한 작업 역할(Game Design, UI/UX Design, Debugging 등)이 누락될 가능성이 큽니다.
- 결과적으로, 작업 계획이 단순화되어 효율성과 품질이 낮아질 수 있습니다.
2. (b) With Collaborative Discussion (협력적 논의가 있는 경우)
- Planner와 Agent Observer의 협력:
- Agent Observer는 Planner와 협력하여 작업 계획과 에이전트 구성을 검토 및 보완합니다.
- 예: Agent Observer가 "게임 설계를 위한 전문가(Game Design Expert), UI/UX 디자인 전문가(UI/UX Design Expert), 디버깅 전문가(Debugging Expert)가 필요하다"고 제안.
- 결과:
- 협력적 논의를 통해 작업의 복잡성을 충분히 고려한 다양한 전문가 에이전트가 생성됩니다.
- 최종적으로 Planner는 작업의 모든 요구 사항을 충족하는 계획을 수립하며, 더 정교한 실행이 가능해집니다.
3. 두 접근 방식의 차이점
| 항목 | 협력적 논의 없음(a) | 협력적 논의 있음(b) |
| 에이전트 생성 방식 | Planner가 독립적으로 결정 | Planner와 Agent Observer의 협력으로 결정 |
| 생성된 에이전트의 다양성 | 제한적 (예: 프로그래밍 전문가 1명) | 다양함 (예: 프로그래밍 전문가, UI/UX 전문가, 디버깅 전문가 등) |
| 작업 계획의 완성도 | 작업의 세부 요구 사항이 누락될 가능성이 있음 | 작업의 세부 요구 사항을 모두 반영한 계획 수립 |
| 최종 결과물의 품질 | 낮을 가능성 있음 | 높을 가능성이 큼 |
4. Python 기반 테트리스 게임 개발 사례 분석
- 협력적 논의 없음:
- Planner는 단순히 프로그래밍 전문가를 생성하고, 게임 개발 작업을 맡기려 함.
- UI 디자인, 게임 설계, 디버깅과 같은 필수 작업이 누락될 가능성이 큼.
- 협력적 논의 있음:
- Planner와 Agent Observer는 협력적으로 작업을 분석하여 게임 설계, UI/UX 디자인, 디버깅 전문가를 포함한 다양한 에이전트를 생성.
- 작업 계획이 복잡한 게임 개발 작업의 요구 사항을 충족하도록 설계됨.
5. 핵심 요약
- 협력적 논의의 중요성:
- 협력적 논의는 Planner의 한계를 보완하며, 작업 계획의 완성도를 높이는 데 기여합니다.
- 특히, 복잡한 작업(예: 테트리스 게임 개발)에서는 다양한 전문성을 가진 에이전트를 생성하기 위해 협력이 필수적입니다.
- AutoAgents의 강점:
- AutoAgents는 Agent Observer와 Planner 간의 협력적 논의를 통해 작업의 요구 사항을 분석하고, 필요한 에이전트를 자동으로 생성합니다.
- 이는 기존 시스템과 달리, 더 정교하고 완성도 높은 작업 수행을 가능하게 합니다.
결론
이 Figure는 협력적 논의가 에이전트 생성 및 작업 계획 수립 과정에서 얼마나 중요한지 시각적으로 보여줍니다. Collaborative Discussion은 AutoAgents의 핵심 메커니즘으로, 복잡한 작업 환경에서도 효율적이고 체계적인 결과물을 생성할 수 있는 기반을 제공합니다.

이 Figure는 Python 기반 테트리스 게임 개발 작업에서 AutoAgents의 작업 흐름과 에이전트 협력이 어떻게 이루어지는지를 시각적으로 설명합니다. 전체 작업은 Draft Stage(초안 작성 단계)와 Execution Stage(실행 단계)로 나뉘며, 작업이 어떻게 세분화되고 최종 결과물로 이어지는지를 보여줍니다.
1. Draft Stage (초안 작성 단계)
Draft Stage에서는 작업을 분석하고, 필요한 에이전트를 생성하며, 실행 계획을 수립합니다.
- 사용자 요청:
- "Develop a Python-based software for the Tetris game."
- 사용자가 Python 기반 테트리스 게임 개발을 요청하며, 시스템은 이를 바탕으로 작업을 계획합니다.
- Planner, Agent Observer, Plan Observer의 역할:
- Planner: 테트리스 게임 개발 작업을 분석하고 필요한 에이전트를 정의합니다.
- Agent Observer: Planner가 생성한 에이전트가 적절한지 검토하고 최적화합니다.
- Plan Observer: 실행 계획이 논리적이고 작업의 요구 사항을 충족하는지 확인합니다.
결과:
Draft Stage의 결과로 다음과 같은 에이전트와 실행 계획이 생성됩니다.
- Game Design Expert: 게임의 논리와 규칙 설계.
- UI/UX Design Expert: 사용자 친화적인 인터페이스 설계.
- Programming Expert: 테트리스 메커니즘 구현.
- Debugging Expert: 구현된 코드를 디버깅하여 오류 수정.
2. Execution Stage (실행 단계)
Execution Stage에서는 Draft Stage에서 설계된 에이전트와 실행 계획에 따라 작업이 수행됩니다. 각 에이전트는 고유한 역할을 가지고 협력적으로 작업을 진행합니다.
2.1 Game Design Expert
- 역할:
- 테트리스 게임의 논리와 규칙을 설계.
- 작업 세분화: 랜덤 테트로미노 생성, 테트로미노 회전, 줄 완성 확인 등.
- 출력 파일:
- tetric_game_design.txt: 설계된 게임 메커니즘과 작업의 세부 내용.
2.2 UI/UX Design Expert
- 역할:
- 사용자가 직관적으로 게임을 플레이할 수 있는 인터페이스 설계.
- 예: 게임 화면 배치, 버튼 인터페이스, 색상 테마 등.
- 출력 파일:
- tetric_game_UI.txt: 설계된 사용자 인터페이스의 상세 설명.
2.3 Programming Expert
- 역할:
- Game Design Expert와 UI/UX Design Expert가 설계한 내용을 기반으로 게임 메커니즘 구현.
- Python 코드를 작성하여 테트리스 게임을 개발.
- 출력 파일:
- tetric_game.py: 완성된 테트리스 게임의 초기 코드.
2.4 Debugging Expert
- 역할:
- Programming Expert가 작성한 코드를 테스트하고, 오류를 디버깅.
- 게임의 안정성과 성능을 보장.
- 출력 파일:
- tetric_game_revised.py: 디버깅된 최종 코드.
3. 최종 결과
- Generated Tetris Game:
- 모든 단계가 완료되면 완성된 테트리스 게임이 생성됩니다.
- 사용자는 Python 기반으로 개발된 완전한 게임을 플레이할 수 있습니다.
4. AutoAgents의 기여
| 단계 | 에이전트 | 기여 |
| Draft Stage | Planner, Agent Observer, Plan Observer | 작업 분석 및 에이전트 생성. 실행 계획의 완성도를 높임. |
| Execution Stage | Game Design Expert | 테트리스 게임의 기본 논리와 규칙 설계. |
| UI/UX Design Expert | 사용자 친화적인 인터페이스 설계. | |
| Programming Expert | 설계 내용을 Python 코드로 구현. | |
| Debugging Expert | 코드의 안정성 확보를 위한 디버깅. | |
| 최종 결과물 | 완성된 Python 기반 테트리스 게임 제공. |
5. 핵심 요약
이 Figure는 AutoAgents가 소프트웨어 개발 프로세스에서 어떻게 각 에이전트를 동적으로 생성하고 협력적으로 작업을 수행하는지를 보여줍니다.
- Draft Stage에서 작업 계획과 에이전트를 설계.
- Execution Stage에서 각 에이전트가 고유한 역할을 수행하며 협업.
- 최종 결과물로 완성된 Python 기반 테트리스 게임이 생성.
AutoAgents는 다양한 전문가 에이전트 간의 협력을 통해 복잡한 작업을 효율적으로 처리할 수 있는 강력한 프레임워크임을 강조합니다.
1. 연구 배경 및 문제 정의
최근 대형 언어 모델(LLM)은 다중 에이전트 시스템을 활용한 자동화된 문제 해결에서 상당한 발전을 이루었다. 그러나 기존의 LLM 기반 다중 에이전트 접근법은 미리 정의된 역할을 가진 에이전트를 사용하여 단순한 작업을 처리하는 데 초점이 맞춰져 있으며, 다양한 시나리오에 적응하기 어려운 한계가 있다.
이러한 문제를 해결하기 위해 AutoAgents 프레임워크를 제안한다. 이는 주어진 작업에 따라 자동으로 여러 특화된 에이전트를 생성하고, 이들이 협력하여 복잡한 문제를 해결하도록 하는 새로운 접근 방식이다.
2. AutoAgents 프레임워크 개요
AutoAgents는 두 가지 주요 단계로 구성된다.
- 초안 작성 단계 (Drafting Stage)
- 초기 에이전트 팀 및 실행 계획을 수립
- 3개의 사전 정의된 에이전트(Planner, Agent Observer, Plan Observer) 가 협력하여 최적의 에이전트 배치 및 실행 계획을 수립
- 실행 단계 (Execution Stage)
- 다중 에이전트가 협력하여 계획을 실행
- 자기 개선(Self-Refinement) 및 협력적 개선(Collaborative Refinement) 메커니즘을 활용하여 에이전트가 지속적으로 학습하고 최적화
3. AutoAgents의 핵심 요소
3.1 동적 에이전트 생성
기존 프레임워크(예: AutoGPT, MetaGPT)는 고정된 에이전트만 사용하지만, AutoAgents는 작업의 내용에 따라 적절한 전문가 에이전트를 동적으로 생성한다. 이를 위해 Planner 가 다음을 수행한다.
- 각 에이전트의 역할 정의 (도메인 전문성, 목표, 제약사항 등)
- 도구 할당 (필요한 도구를 사용하여 작업 수행)
- 실행 계획 수립 (어떤 에이전트가 어떤 작업을 수행할지 결정)
생성된 에이전트 리스트는 Agent Observer 에 의해 검토되며, 중복되거나 불필요한 에이전트는 제거되고 부족한 역할은 추가된다.
3.2 실행 계획 최적화
실행 계획은 Plan Observer 에 의해 검토되며, 다음을 확인한다.
- 각 단계의 논리적 일관성 (단계 간 연결이 자연스러운가?)
- 충분한 작업 분해 (모든 필요한 작업이 계획에 포함되었는가?)
- 적절한 에이전트 배정 (각 단계가 최적의 전문가에게 할당되었는가?)
4. 작업 수행 메커니즘
AutoAgents는 다음과 같은 두 가지 핵심 메커니즘을 통해 작업을 수행한다.
4.1 자기 개선(Self-Refinement)
- 단일 에이전트가 자신의 작업을 검토하고 반복적으로 개선
- 예: 프로그래머 에이전트가 초안을 작성한 후 이를 다시 평가하고 최적화하는 과정
4.2 협력적 개선(Collaborative Refinement)
- 여러 에이전트가 협력하여 최종 출력을 개선
- 예: 이야기 작성 작업에서 스토리 플래너와 캐릭터 개발자가 협력하여 더 완성도 높은 서사를 구성
4.3 다중 에이전트 간 커뮤니케이션
AutoAgents는 수직적 커뮤니케이션 방식을 채택하여, Action Observer 가 전체 실행 계획을 조정하고 에이전트 간 정보를 공유하도록 한다.
4.4 메모리 공유 기법
AutoAgents는 다수의 에이전트가 효율적으로 협력할 수 있도록 메모리 시스템을 활용한다.
- 단기 메모리(Short-Term Memory): 개별 작업의 실행 과정을 저장
- 장기 메모리(Long-Term Memory): 전체 작업의 진행 상태 기록
- 동적 메모리(Dynamic Memory): 특정 작업을 위해 장기 메모리에서 필요한 정보 추출
5. 실험 및 평가
AutoAgents의 성능을 검증하기 위해 여러 벤치마크 실험을 수행하였다.
5.1 Open-ended Question Answering
- GPT-4, ChatGPT, Vicuna-13B 모델과 비교하여 AutoAgents가 더 정교하고 일관된 답변을 생성
- FairEval 및 HumanEval 평가에서 각각 76.3% 및 62.5% 우세
5.2 Trivia Creative Writing
- 다양한 트리비아 질문을 기반으로 창의적인 이야기를 작성하는 과제
- AutoAgents는 다른 프레임워크보다 최대 10% 더 높은 성능을 기록
5.3 소프트웨어 개발 사례 연구
- 테트리스 게임 개발 작업에서 AutoAgents는 게임 디자이너, UI 전문가, 프로그래머, 디버거 등의 전문 에이전트를 생성하여 효율적인 협업을 가능하게 함
6. 주요 기여 및 한계
6.1 기여
- 자동 에이전트 생성 프레임워크 제안
- 작업별로 적합한 전문가 에이전트를 자동으로 생성 및 조정
- 자기 개선 및 협력적 개선 메커니즘 도입
- 에이전트들이 독립적으로 학습하고 상호 피드백을 통해 성능 향상
- 벤치마크 실험을 통해 성능 입증
- Open-ended QA 및 Trivia Creative Writing 과제에서 기존 프레임워크보다 뛰어난 성능을 보임
6.2 한계
- 에이전트 생성 및 계획 수립의 최적화 필요
- 에이전트의 배치와 실행 계획의 적절성을 보장하기 위한 추가 연구 필요
- 전문가 지식 부족
- 생성된 에이전트가 실제 도메인 전문가 수준의 지식을 갖추도록 하기 위한 연구 필요
- GPT-4 의존성
- 현재는 GPT-4에 최적화된 시스템으로, 다른 LLM에서의 성능 검증 필요
7. 결론 및 향후 연구 방향
AutoAgents는 다중 에이전트 시스템의 새로운 가능성을 제시하며, 자동화된 협업 AI 시스템의 성능을 극대화할 수 있는 방법을 탐구하였다. 향후 연구 방향은 다음과 같다.
- 더 나은 계획 수립 및 에이전트 선택 방법 개발
- 전문적인 에이전트 학습 및 강화
- 더 나은 기억 시스템 구축
- 실제 응용 사례 확장 (의료 AI, 법률 AI 등)
8. AutoAgents의 활용 가능성
AutoAgents는 여러 분야에서 활용될 가능성이 크다.
- 소프트웨어 개발: 다중 전문가 협업을 통한 소프트웨어 엔지니어링 자동화
- 연구 및 논문 작성: 특정 주제에 대한 논문 초안을 자동 생성
- 게임 개발: 여러 역할의 에이전트를 생성하여 게임 기획, 개발, 테스트 자동화
- AI 연구 보조 시스템: 연구 데이터를 수집, 분석, 모델 개선 등을 수행하는 다중 에이전트 활용 가능
9. 마무리
AutoAgents는 에이전트 기반 협업 시스템을 더욱 발전시킬 수 있는 중요한 연구 방향을 제시하며, 향후 AGI 연구 및 자동 연구 AI 시스템 개발에 유용하게 활용될 수 있을 것이다.
AutoAgents의 방법론
AutoAgents는 자동 에이전트 생성 및 협업을 위한 프레임워크로, 특정 작업에 맞춰 동적으로 에이전트를 생성하고 최적의 실행 계획을 수립하여 문제를 해결하는 방식이다.
1. 초안 작성 단계 (Drafting Stage)
이 단계에서는 작업(Task)에 필요한 에이전트를 자동으로 생성하고, 실행 계획을 수립한다.
- 핵심 개념: Planner, Agent Observer, Plan Observer
- 주요 역할:
- Planner: 작업을 분석하고 필요한 에이전트를 생성
- Agent Observer: 생성된 에이전트가 적절한지 검토하고 최적화
- Plan Observer: 실행 계획이 논리적으로 타당한지 평가하고 개선
📌 예제: 논문 요약 AI 시스템 구축
상황: AI 연구자가 논문을 요약하는 AI 시스템을 만들려고 한다.
1) Planner가 수행하는 작업
- "논문을 요약하는 작업을 수행해야 한다. 어떤 역할이 필요할까?"를 분석
- 다음과 같은 에이전트 역할을 자동으로 생성:
- 논문 분석가 (Paper Analyst): 논문의 주요 내용을 파악하는 역할
- 요약 작성가 (Summary Writer): 분석된 내용을 정리하여 요약 생성
- 언어 교정가 (Language Refiner): 요약문의 문장 구조와 가독성을 개선
- 피드백 관찰자 (Feedback Observer): 요약 결과가 논문의 핵심 내용을 유지하는지 평가
2) Agent Observer의 역할
- "논문 분석가와 요약 작성가가 중복된 역할을 수행하는가?"
→ 중복되지 않도록 역할을 조정 - "언어 교정가는 실제 필요한가?"
→ 문법 오류 및 가독성 개선이 필요하므로 유지 - "피드백 관찰자는 논문 요약 성능을 평가할 수 있는가?"
→ 필요한 평가 기준을 추가하도록 개선
3) Plan Observer의 역할
- 실행 계획을 점검하여 논리적 오류가 없는지 확인
- 예를 들어, 논문 분석이 끝나기도 전에 요약 작성이 시작되면 안 되므로 작업 순서 조정
- 최종 실행 계획:
- 논문 분석가가 논문의 핵심 내용을 정리
- 요약 작성가가 이를 기반으로 초안을 작성
- 언어 교정가가 초안을 개선
- 피드백 관찰자가 최종 평가를 수행하여 피드백 제공
2. 실행 단계 (Execution Stage)
이 단계에서는 다중 에이전트가 협력하여 실행 계획을 수행하며, 성능을 향상시키기 위해 자기 개선(Self-Refinement)과 협력적 개선(Collaborative Refinement)을 적용한다.
- 핵심 개념: Action Observer, Self-Refinement, Collaborative Refinement
- 주요 역할:
- Action Observer: 전체적인 실행 과정을 모니터링하고 조정
- Self-Refinement: 개별 에이전트가 자신의 출력을 스스로 평가하고 개선
- Collaborative Refinement: 여러 에이전트가 협력하여 더 나은 출력을 생성
📌 예제: 논문 요약 AI 시스템 실행
AutoAgents가 생성한 논문 요약 시스템이 실행되면 다음과 같은 과정이 진행된다.
1) Action Observer의 역할
- 전체 실행 흐름을 관리하며 각 에이전트의 역할이 올바르게 수행되는지 점검
- 예를 들어, 논문 분석가가 논문을 제대로 분석하지 못하면 요약 작성가가 작업을 수행할 수 없으므로 수정 요청
2) Self-Refinement (자기 개선)
- 개별 에이전트가 자신의 출력을 스스로 평가하고 개선
- 예제: 논문 분석가가 논문을 분석한 후, 자체적으로 검토하여 부족한 정보를 보완
- "논문의 주요 개념을 충분히 포함했는가?"
- "이해하기 쉬운 요약을 제공했는가?"
- 부족한 부분이 있으면 다시 분석 후 결과 수정
3) Collaborative Refinement (협력적 개선)
- 여러 에이전트가 협력하여 최종 출력을 개선
- 예제: 요약 작성가와 언어 교정가가 협력하여 문장을 다듬고 논리적 일관성을 확보
- 요약 작성가: "이 부분이 좀 더 명확해져야 합니다."
- 언어 교정가: "이 문장을 조금 다듬어서 가독성을 높이겠습니다."
- 최종적으로 더 높은 품질의 요약이 생성됨
3. 메모리 공유 및 협업
AutoAgents는 작업의 연속성을 유지하고 정보를 효과적으로 공유하기 위해 세 가지 메모리 시스템을 사용한다.
- 핵심 개념: Short-Term Memory, Long-Term Memory, Dynamic Memory
- 주요 역할:
- Short-Term Memory: 개별 작업의 실행 과정을 기록
- Long-Term Memory: 전체 작업의 진행 상태 및 과거 결과 저장
- Dynamic Memory: 특정 작업에 필요한 정보만 선택적으로 제공하여 최적의 실행 지원
📌 예제: 논문 요약 AI 시스템의 메모리 관리
1) Short-Term Memory (단기 메모리)
- 요약 작성가가 논문 분석 결과를 참조하여 요약 작성
- 단기 메모리는 한 세션 동안만 유지되며, 이후 업데이트됨
2) Long-Term Memory (장기 메모리)
- AutoAgents가 과거 논문 요약 데이터를 저장
- 예제: "이전에 요약한 논문과 이번 논문의 주제가 유사한가?"
→ 과거 데이터를 활용하여 일관성 있는 요약 생성 가능
3) Dynamic Memory (동적 메모리)
- 특정 작업에 필요한 데이터만 동적으로 제공
- 예제: "현재 논문에서 핵심 개념을 강조해야 하는 부분이 있는가?"
→ 논문의 주요 키워드만 선택적으로 제공하여 요약 품질 향상
AutoAgents의 강점 요약
✅ 작업 맞춤형 에이전트 자동 생성: 미리 정의된 역할이 아니라, 작업에 맞춰 적절한 전문가 에이전트를 동적으로 생성
✅ 다중 에이전트 협업 최적화: 자기 개선(Self-Refinement)과 협력적 개선(Collaborative Refinement) 적용
✅ 효율적인 메모리 관리: 단기, 장기, 동적 메모리 시스템을 활용하여 정보 공유 및 실행 최적화
결론 및 응용 가능성
AutoAgents의 방법론은 다양한 분야에서 적용 가능하다.
- NLP 연구: 논문 요약, 데이터 정제, 번역 등
- 소프트웨어 개발: 코드 작성, 디버깅, 프로젝트 관리
- 자동화 연구 시스템: 다중 에이전트가 논문 분석, 실험 설계, 데이터 분석을 수행하여 연구 자동화 가능
🔥 핵심 메시지: AutoAgents는 LLM과 다중 에이전트를 결합하여 더 효율적이고 강력한 AI 협업 시스템을 구축하는 혁신적인 방법론이다. 🚀
AutoAgents 논문의 결과
1. 실험 결과
AutoAgents의 성능을 검증하기 위해 여러 벤치마크 실험이 진행되었으며, 기존 다중 에이전트 시스템 대비 우수한 성능을 보였다. 실험은 크게 세 가지 주요 과제로 나누어 진행되었다.
📌 1.1 Open-ended Question Answering (개방형 질문 응답)
- GPT-4, ChatGPT, Vicuna-13B 모델과 비교하여 AutoAgents가 더 정교하고 일관된 답변을 생성함을 입증.
- FairEval 및 HumanEval 평가에서 AutoAgents가 각각 76.3% 및 62.5% 더 높은 점수를 기록.
- 이는 자동 생성된 전문가 에이전트가 특정 질문을 더 깊이 분석하고 협력적으로 답변을 개선했기 때문.
🔹 결과 요약:
✅ AutoAgents는 기존 단일 LLM보다 더 정확하고 풍부한 정보를 포함하는 답변 생성 가능
✅ 전문가 역할을 자동 생성하여, 기존의 단일 모델보다 세밀한 논리 전개 가능
📌 1.2 Trivia Creative Writing (트리비아 기반 창의적 글쓰기)
- Trivia 질문(N = 5, N = 10)에 대한 답변을 포함하여 창의적인 스토리를 작성하는 실험.
- AutoAgents는 기존 AgentVerse, SSP 등 프레임워크 대비 약 10% 더 높은 성능을 기록.
- 이는 다중 에이전트의 협업적 개선(Collaborative Refinement)과 동적 메모리 활용(Dynamic Memory) 덕분에 더 풍부한 문맥을 유지했기 때문.
🔹 결과 요약:
✅ AutoAgents는 더 복잡한 창의적 글쓰기 작업에서도 높은 일관성을 유지
✅ 협력적 개선(Collaborative Refinement)을 통해 다중 에이전트 간 피드백 교환 가능
✅ 전문가 에이전트가 분야별로 역할을 분담하여 정교한 결과 도출
📌 1.3 소프트웨어 개발 사례 연구
- Python 기반 테트리스 게임 개발을 예제로 사용하여 AutoAgents의 실제 적용 가능성을 테스트.
- AutoAgents는 게임 디자이너, UI 디자이너, 프로그래머, 디버깅 전문가 등의 에이전트를 생성하여 더 체계적이고 효율적인 협업 환경을 제공.
- 기존 단일 LLM을 사용하는 경우보다 구조화된 개발 프로세스를 형성하고, 오류를 줄이며, 더 신속하게 결과를 도출.
🔹 결과 요약:
✅ AutoAgents는 실제 소프트웨어 개발 작업에서도 효율성을 증명
✅ 도메인 전문가 에이전트를 자동 생성하여 협업이 원활하게 진행됨
✅ Action Observer를 통해 실행 흐름을 모니터링하며 작업 조율 가능
2. 결론
AutoAgents는 기존의 LLM 기반 다중 에이전트 시스템이 갖고 있던 고정된 에이전트 구성의 한계를 극복하고, 작업에 따라 동적으로 최적의 전문가 팀을 생성하고 협업을 최적화하는 새로운 프레임워크를 제안하였다.
AutoAgents의 핵심 기여점:
- 자동 에이전트 생성(Auto Generation of Agents)
- 기존의 수작업으로 설계된 에이전트 기반 시스템과 달리, 작업 내용에 맞춰 적절한 전문가 에이전트를 자동으로 생성.
- 자기 개선(Self-Refinement)과 협력적 개선(Collaborative Refinement) 적용
- 개별 에이전트가 스스로 작업을 개선하며, 다중 에이전트 간 협력을 통해 최적의 결과 도출.
- 효율적인 메모리 관리 시스템 적용
- 단기 메모리(Short-Term), 장기 메모리(Long-Term), 동적 메모리(Dynamic Memory) 를 활용하여 작업 효율 극대화.
주요 실험 결과 요약:
✅ 개방형 질문 응답에서 GPT-4, ChatGPT보다 더 나은 답변 생성
✅ 창의적 글쓰기 작업에서 기존 프레임워크 대비 10% 이상 향상된 성능 기록
✅ 소프트웨어 개발 사례에서 기존보다 더 체계적이고 효율적인 협업 가능
3. 한계 및 향후 연구 방향
📌 3.1 한계점
AutoAgents는 강력한 프레임워크이지만, 몇 가지 한계를 가진다.
- 에이전트 생성 및 계획 수립의 최적화 필요
- 현재는 LLM이 생성한 에이전트의 적절성을 수작업으로 평가해야 하는 경우가 있음.
- 더 정교한 자동 평가 및 최적화 기법이 필요.
- 전문가 지식의 한계
- 생성된 에이전트는 특정 도메인(예: 의료, 법률)에서 전문적인 판단을 내리는 데 부족할 수 있음.
- 이를 해결하기 위해, 사전 훈련된 전문가 LLM 또는 외부 지식베이스와 연동할 필요.
- GPT-4 의존성
- 현재는 GPT-4를 기반으로 동작하므로, 더 경량화된 모델에서도 유사한 성능을 유지할 수 있도록 개선 필요.
📌 3.2 향후 연구 방향
- 더 나은 에이전트 생성 방법 개발
- 현재 Planner가 생성하는 에이전트의 품질을 높이기 위해, 자동 평가 및 조정 메커니즘을 연구해야 함.
- 전문가 수준의 도메인 지식 강화
- AutoAgents가 특정 도메인에서 보다 신뢰성 높은 에이전트 역할을 수행할 수 있도록, 전문가 데이터를 활용한 사전 학습 필요.
- 더 나은 메모리 및 장기적 학습 적용
- 현재는 실행 중에만 메모리를 활용하지만, 장기적인 학습을 통해 지속적으로 개선될 수 있도록 강화학습 기법 적용 가능.
- 더 광범위한 실제 응용 사례 연구
- 현재 연구는 NLP 및 소프트웨어 개발에 집중되어 있음.
- 이를 의료 AI, 법률 AI, 자율 로봇 등 다양한 분야에 확장 적용하는 연구 필요.
4. 마무리
AutoAgents는 자동 에이전트 생성 및 협업을 최적화하는 혁신적인 방법론을 제안하였으며, 실험을 통해 기존 시스템 대비 더 높은 성능과 적응성을 갖춘 프레임워크임을 입증하였다.
📌 AutoAgents가 제공하는 주요 혁신
✅ 작업 맞춤형 에이전트 자동 생성: 기존의 고정된 에이전트 시스템의 한계를 극복
✅ 다중 에이전트 협업 최적화: 자기 개선(Self-Refinement)과 협력적 개선(Collaborative Refinement) 활용
✅ 효율적인 메모리 관리: 단기, 장기, 동적 메모리를 활용하여 정보 공유 및 실행 최적화
✅ 다양한 도메인 적용 가능성: NLP, 소프트웨어 개발, 연구 자동화, 의료 AI 등 광범위한 응용 가능
🚀 결론: AutoAgents는 차세대 AI 협업 시스템을 위한 강력한 프레임워크이다!
AutoAgents는 AGI(Artificial General Intelligence) 연구에도 중요한 기여를 할 수 있는 개념이며, 향후 다중 AI 에이전트 시스템의 발전 방향을 제시하는 핵심 연구라고 할 수 있다.
AutoAgents 관련 연구
AutoAgents는 LLM 기반 다중 에이전트 시스템(Multi-Agent System, MAS)을 활용하여 자동화된 에이전트 생성 및 협업을 최적화하는 프레임워크이다. 이를 이해하기 위해 관련된 기존 연구들을 세 가지 카테고리로 정리하였다.
1. LLM 기반 자동화된 에이전트 프레임워크 연구
AutoAgents와 유사한 다중 에이전트 시스템 연구 AutoAgents는 기존의 LLM 기반 에이전트 프레임워크를 확장하여 자동 에이전트 생성(Auto Generation of Agents)과 협업 최적화를 수행한다.
| 프레임 워크 | 에이전트 생성 방식 | 다중 에이전트 협업 | 자기 개선 | 협력적 개선 |
| AutoGPT [1] | 고정된 단일 에이전트 | X | O | X |
| BabyAGI [2] | 3개 고정 에이전트 | O | X | X |
| MetaGPT [3] | 여러 GPT 인스턴스로 팀 구성 | O | X | X |
| Camel [4] | 역할 기반 다중 에이전트 협업 | O | X | X |
| AutoGen [5] | GPT 기반 에이전트 대화형 협업 | O | X | X |
| AgentVerse [6] | 고정된 구조의 다중 에이전트 협업 | O | X | X |
| SSP (Solo-Performance Prompting) [7] | 개별 에이전트가 독립적으로 문제 해결 | O | X | X |
| AutoAgents (본 논문) | 작업별 동적 에이전트 생성 | O | O | O |
🔹 결론:
AutoAgents는 기존 연구들에 비해 에이전트 생성이 동적이며, 자기 개선(Self-Refinement)과 협력적 개선(Collaborative Refinement)이 모두 가능하여 더 강력한 다중 에이전트 시스템을 구축할 수 있다.
2. 다중 에이전트 협업 및 커뮤니케이션 연구
AutoAgents가 활용하는 다중 에이전트 협업 및 커뮤니케이션 전략
AutoAgents의 핵심 기능 중 하나는 다중 에이전트가 협업하여 작업을 수행하고, 상호 피드백을 제공하여 성능을 개선하는 것이다. 이러한 개념은 기존 연구에서도 논의되었으며, 다음과 같은 논문이 주요한 기여를 했다.
2.1 다중 에이전트 협업 연구
- MetaGPT: Multi-Agent Collaboration for Complex Tasks [3]
- GPT 모델을 여러 개 배치하여 소프트웨어 개발 팀을 구성하는 방식을 연구.
- AutoAgents와 유사한 개념이지만, 동적 에이전트 생성 기능이 없음.
- 차이점: AutoAgents는 동적으로 에이전트를 생성하고, 자기 개선 및 협력적 개선을 적용하여 지속적인 학습이 가능.
- Multi-Agent Debate for LLM Decision Making [8]
- 다중 에이전트가 논쟁을 통해 최적의 답변을 도출하는 방법을 연구.
- AutoAgents는 이 연구의 개념을 발전시켜 논쟁을 넘어 협력적 문제 해결을 수행.
- LLM Self-Refinement and Feedback Loops [9]
- LLM이 자체 피드백을 받아 점진적으로 개선되는 Self-Refinement 기법을 연구.
- AutoAgents는 이를 다중 에이전트 시스템에 적용하여, 개별 에이전트가 자기 개선을 수행하는 구조를 도입.
2.2 다중 에이전트 커뮤니케이션 연구
- Social Simulacra: Creating Populated AI Systems [10]
- 다중 AI가 협업하여 사회적 시뮬레이션을 수행하는 방법 연구.
- AutoAgents는 이 개념을 실제 작업 수행을 위한 협업 프레임워크로 확장.
- AutoGen: Multi-Agent Conversational Framework [5]
- 다중 에이전트가 대화를 통해 문제를 해결하는 시스템을 연구.
- AutoAgents는 단순 대화 협업을 넘어 실제 작업 수행과 개선까지 포함.
3. 메모리 및 학습 강화 연구
AutoAgents는 다중 에이전트가 과거 정보를 공유하고 학습할 수 있도록 메모리 시스템을 활용한다.
3.1 메모리 공유 및 강화학습 연구
- Dynamic Memory for LLMs [11]
- LLM이 단기 기억(Short-Term Memory)과 장기 기억(Long-Term Memory)을 조합하여 성능을 향상시키는 연구.
- AutoAgents는 Dynamic Memory를 추가하여, 작업 수행 중 필요한 정보만 선택적으로 제공하는 방식을 도입.
- ReAct: Synergizing Reasoning and Acting in LLMs [12]
- LLM이 과거 데이터를 기반으로 스스로 생각(Reasoning)하고 실행(Acting)하는 기법 연구.
- AutoAgents는 이 개념을 확장하여 다중 에이전트가 협력적으로 학습하고 최적화할 수 있도록 설계.
- Tree of Thoughts: Long-Horizon Planning for LLMs [13]
- LLM이 장기적인 계획을 수립하고 실행하는 방법 연구.
- AutoAgents는 이를 기반으로 Planner 에이전트가 작업을 최적의 순서로 분해하고 실행할 수 있도록 설계.
4. 결론: AutoAgents와 기존 연구의 차별점
AutoAgents는 기존의 다중 에이전트 시스템 연구들을 발전시켜, 더 정교한 협업과 자기 학습이 가능한 자동화 프레임워크를 구축하였다.
🔹 기존 연구들과의 차별점
✅ 자동 에이전트 생성: 기존 연구들은 고정된 에이전트를 사용했지만, AutoAgents는 작업에 맞춰 동적 에이전트를 생성.
✅ 자기 개선(Self-Refinement) 적용: 개별 에이전트가 자신의 출력을 검토하고 개선할 수 있음.
✅ 협력적 개선(Collaborative Refinement) 도입: 다중 에이전트 간의 피드백 루프를 활용하여 최적화 가능.
✅ 메모리 시스템 활용: 단기, 장기, 동적 메모리를 조합하여 다중 에이전트 협업의 효율성 극대화.
결론적으로, AutoAgents는 기존 연구들의 개념을 통합하고 확장하여, 다중 AI 에이전트가 협업을 통해 점진적으로 학습하고 최적화할 수 있는 강력한 프레임워크를 제공한다. 🚀
아래는 사용자가 작성한 내용을 기반으로, 부족하거나 잘못된 부분을 보완하여 수정한 내용입니다.
수정된 내용:
"이 논문은 기존 에이전트들이 고정된 시스템에서 작동하며 유연성이 부족했던 한계를 지적하고, 이를 극복하기 위한 새로운 프레임워크를 제안합니다.
AutoAgents는 작업에 따라 적합한 역할을 수행할 수 있는 에이전트를 동적으로 생성하고, 이들 에이전트를 조정하고 평가하는 관찰자 에이전트(Agent Observer, Plan Observer, Action Observer)를 통해 체계적인 작업 수행을 가능하게 합니다.
이 에이전트들은 계획(Plan)에 따라 작업을 수행하며, 작업 중에는 자기 반성(Self-Refinement)을 통해 스스로 발전하거나, 협력적 개선(Collaborative Refinement)을 통해 서로의 지식을 교환하며 작업의 품질을 향상시킵니다.
또한 AutoAgents는 동적 메모리(Dynamic Memory)를 활용하여 Long-term Memory에서 필요한 작업과 연관된 데이터를 가져와 이를 Few-shot 학습처럼 활용합니다.
결과적으로, 에이전트들이 서로를 직접 호출하지는 않지만, 지속적인 계획과 관찰을 통해 작업 순서를 최적화하며 높은 작업 성공률을 달성합니다."
주요 수정 및 보완 사항:
- 기술적 표현 보완:
- "Agent들이 고정된 시스템에서 돌아가는 한계를 지적" → "고정된 시스템에서 작동하며 유연성이 부족한 한계를 지적"으로 변경하여 의미를 명확히 전달.
- "Few-shot으로 활용"이라는 표현은 메모리 시스템과 관련하여 구체적으로 설명.
- 핵심 메커니즘 보완:
- "자기 반성을 통해 발전"이라는 표현을 구체화하여 Self-Refinement와 Collaborative Refinement의 개념 추가.
- 메모리 시스템 명확화:
- "동적으로 메모리에서 연관된 작업을 가져와 Few-shot으로 활용" 부분을 Dynamic Memory의 역할로 구체화.
- 에이전트 간 상호작용 보완:
- "Agent가 서로를 호출하진 않지만"이라는 문장에서, "직접 호출하지 않지만 지속적인 계획과 관찰을 통해 작업 순서를 최적화"로 보완하여 더 명확하게 전달.
이 수정된 내용은 원본 작성 의도를 살리면서 논문의 핵심 내용을 더 체계적이고 구체적으로 반영했습니다. 추가 보완이 필요하다면 알려주세요!