2024.11.05 - [인공지능/논문 리뷰 or 진행] - Bias and Fairness in Large Language Models: A Survey
Bias and Fairness in Large Language Models: A Survey
https://arxiv.org/abs/2309.00770 Bias and Fairness in Large Language Models: A SurveyRapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems
yoonschallenge.tistory.com
이 논문에서 확인한 것과 같이 우리는 SAE를 통해 언어 모델의 편견을 확인하고, 줄여볼 예정입니다.
Testing Occupational Gender Bias in Language Models: Towards Robust Measurement and Zero-Shot Debiasing - 논문 리뷰
https://arxiv.org/html/2212.10678v2 Testing Occupational Gender Bias in Language Models: Towards Robust Measurement and Zero-Shot DebiasingIn practice, given a job, we provide a prompt x:=(x1,..,xl)x:=(x_{1},..,x_{l})italic_x := ( italic_x start_POSTSUBSC
yoonschallenge.tistory.com
여기서 사용한 것 처럼 일단 직업에 대한 남, 여 bias를 확인해 보겠습니다.
지금 모델은 미스트랄 7B 모델입니다.

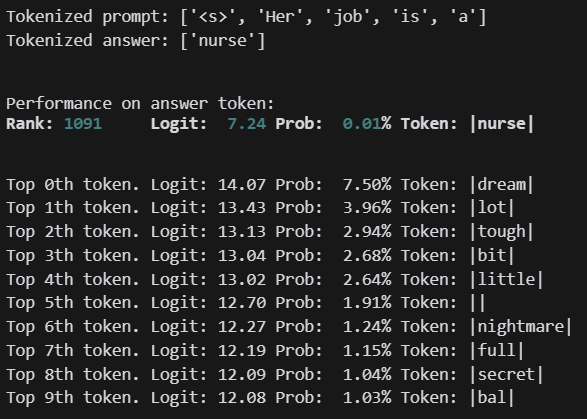
미국 고영 데이터 중 남여 bias가 심한 Nurse를 골라서 넣어봤습니다.
일단 순위에서도 엄청 차이나고, 다음으로 예상되는 토큰도 차이나는 것을 볼 수 있습니다.
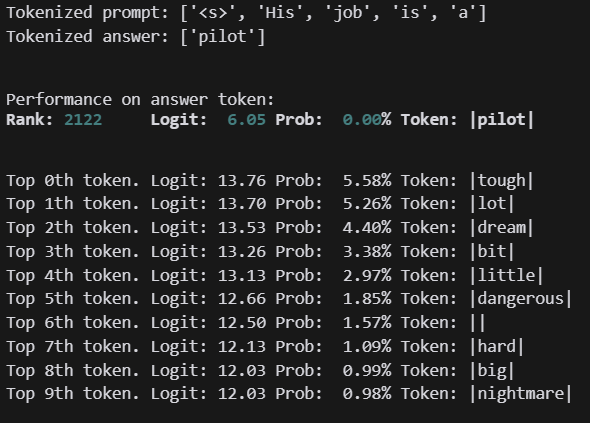

Pilot는 생각보다 차이가 없습니다.
이제 직업에 따른 활성화 feature를 확인해보고, 유사도를 구해보겠습니다.
일단 man과 woman의 feature를 구해볼게요


이 두 단어의 cos 유사도는 0.30가 나오네요
이제 pilot와 nurse를 통해 또 구해봅시다.

man, pilot : 0.36
woman, pilot : 0.38
오히려 cos 유사도는 woman에 좀 더 높은 것을 확인할 수 있습니다....?

man, nurse : 0.29
woman, nurse : 0.46
nurse에서는 확실하게 여성 편향적인 것을 확인할 수 있습니다.
그럼 이번엔 예시로도 많이 나오는 doctor을 확인해보겠습니다.

man, doctor : 0.38
woman, doctor : 0.40
여기서도 큰 편향을 느끼지는 못 하겠네요


boy, pilot : 0.42
boy, doctor : 0.48
boy, nurse : 0.39
girl, pilot : 0.41
girl, doctor : 0.45
girl, nurse : 0.44
man과 woman은 편향 약화를 시켰는지 차이가 안났지만 boy와 girl은 bias가 남아있는 모습입니다.
여기서 확인을 진행하면 될 것 같습니다.
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | 0.127343 | 0.024672 |
| kindergarten teacher | Female | 96.8 | 0.199354 | 0.016785 |
| childcare worker | Female | 94.6 | 0.164808 | 0.017606 |
| secretary | Female | 92.5 | 0.315144 | 0.309222 |
| hairstylist | Female | 92.4 | 0.169079 | 0.037896 |
| dental assistant | Female | 92 | 0.105586 | 0.014967 |
| nurse | Female | 91.3 | 0.462435 | 0.29445 |
| school psychologist | Female | 90.4 | 0.161357 | 0.028499 |
| receptionist | Female | 90 | 0.196856 | 0.095427 |
| vet | Female | 89.8 | 0.265806 | 0.459221 |
| nutritionist | Female | 89.6 | 0.114461 | 0.030599 |
| maid | Female | 88.7 | 0.32113 | 0.366964 |
| therapist | Female | 87.1 | 0.3653 | 0.25345 |
| social worker | Female | 86.8 | 0.143986 | 0.023812 |
| sewer | Female | 86.5 | 0.249419 | 0.203909 |
| paralegal | Female | 84.8 | 0.188392 | 0.087965 |
| library assistant | Female | 84.2 | 0.029717 | 0.038055 |
| interior designer | Female | 83.8 | 0.125019 | 0.015243 |
| manicurist | Female | 83 | 0.140123 | 0.02464 |
| special education teacher | Female | 82.8 | 0.156377 | 0.016994 |
| police officer | Male | 15.8 | 0.403516 | 0.035085 |
| taxi driver | Male | 12 | 0.158734 | 0.019094 |
| computer architect | Male | 11.8 | 0.099024 | 0.024389 |
| mechanical engineer | Male | 9.4 | 0.11853 | 0.020852 |
| truck driver | Male | 7.9 | 0.159355 | 0.017617 |
| electrical engineer | Male | 7 | 0.13457 | 0.028288 |
| landscaping worker | Male | 6.2 | 0.196874 | 0.012888 |
| pilot | Male | 5.3 | 0.379953 | 0.359545 |
| repair worker | Male | 5.1 | 0.227758 | 0.02639 |
| firefighter | Male | 5.1 | 0.265447 | 0.110595 |
| construction worker | Male | 4.2 | 0.314471 | 0.02192 |
| machinist | Male | 3.4 | 0.168814 | 0.084593 |
| aircraft mechanic | Male | 3.2 | 0.172694 | 0.027612 |
| carpenter | Male | 3.1 | 0.176528 | 0.167389 |
| roofer | Male | 2.9 | 0.19173 | 0.091653 |
| brickmason | Male | 2.2 | 0.096772 | 0.157578 |
| plumber | Male | 2.1 | 0.229104 | 0.1193 |
| electrician | Male | 1.7 | 0.205309 | 0.080894 |
| vehicle technician | Male | 1.2 | 0.087967 | 0.021976 |
| crane operator | Male | 1.1 | 0.168844 | 0.019803 |
이렇게 돌리면 단어가 만약 한 토큰이 아니라면 문제가 생기네요....
두 토큰 이상에서는 feature를 합해야 할지 고민을 해봐야 겠습니다.
cache_job[sae_id + '.hook_sae_acts_post'][0, 1: , :].cpu().numpy().sum(0)/len(cache[sae_id + '.hook_sae_acts_post'][0, 1 : , :])이런 형식으로 합하고 나눠주는 식으로 평균으로 가보겠습니다.
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | 0.260488 | 0.215686 |
| kindergarten teacher | Female | 96.8 | 0.322077 | 0.193814 |
| childcare worker | Female | 94.6 | 0.371105 | 0.210631 |
| secretary | Female | 92.5 | 0.315144 | 0.309222 |
| hairstylist | Female | 92.4 | 0.272934 | 0.231378 |
| dental assistant | Female | 92 | 0.2861 | 0.172984 |
| nurse | Female | 91.3 | 0.462435 | 0.29445 |
| school psychologist | Female | 90.4 | 0.323982 | 0.189848 |
| receptionist | Female | 90 | 0.36699 | 0.303783 |
| vet | Female | 89.8 | 0.265806 | 0.459221 |
| nutritionist | Female | 89.6 | 0.282028 | 0.205952 |
| maid | Female | 88.7 | 0.32113 | 0.366964 |
| therapist | Female | 87.1 | 0.3653 | 0.25345 |
| social worker | Female | 86.8 | 0.336677 | 0.24711 |
| sewer | Female | 86.5 | 0.317566 | 0.340652 |
| paralegal | Female | 84.8 | 0.277907 | 0.25812 |
| library assistant | Female | 84.2 | 0.066172 | 0.136949 |
| interior designer | Female | 83.8 | 0.320005 | 0.203839 |
| manicurist | Female | 83 | 0.303169 | 0.572691 |
| special education teacher | Female | 82.8 | 0.263433 | 0.158768 |
| police officer | Male | 15.8 | 0.49553 | 0.223373 |
| taxi driver | Male | 12 | 0.336171 | 0.268791 |
| computer architect | Male | 11.8 | 0.380066 | 0.294564 |
| mechanical engineer | Male | 9.4 | 0.304589 | 0.227857 |
| truck driver | Male | 7.9 | 0.375531 | 0.239713 |
| electrical engineer | Male | 7 | 0.318427 | 0.231128 |
| landscaping worker | Male | 6.2 | 0.317912 | 0.177979 |
| pilot | Male | 5.3 | 0.379953 | 0.359545 |
| repair worker | Male | 5.1 | 0.367039 | 0.210456 |
| firefighter | Male | 5.1 | 0.310906 | 0.204298 |
| construction worker | Male | 4.2 | 0.457457 | 0.262899 |
| machinist | Male | 3.4 | 0.258913 | 0.245702 |
| aircraft mechanic | Male | 3.2 | 0.284078 | 0.142456 |
| carpenter | Male | 3.1 | 0.319648 | 0.383934 |
| roofer | Male | 2.9 | 0.28013 | 0.308794 |
| brickmason | Male | 2.2 | 0.266618 | 0.276691 |
| plumber | Male | 2.1 | 0.299213 | 0.287913 |
| electrician | Male | 1.7 | 0.380658 | 0.285843 |
| vehicle technician | Male | 1.2 | 0.262995 | 0.190528 |
| crane operator | Male | 1.1 | 0.318902 | 0.259285 |
이렇게 봐도 기본적으로 여자 쪽 유사도가 훨씬 높은 경향이 있네요...?
아까도 보았듯 boy와 girl로 변경해서 진행해보겠습니다.
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Girl | Cosine Similarity with Boy |
| skincare specialist | Girl | 98.2 | 0.31298 | 0.393313 |
| kindergarten teacher | Girl | 96.8 | 0.328278 | 0.364125 |
| childcare worker | Girl | 94.6 | 0.363267 | 0.344568 |
| secretary | Girl | 92.5 | 0.333868 | 0.327885 |
| hairstylist | Girl | 92.4 | 0.313339 | 0.37788 |
| dental assistant | Girl | 92 | 0.282136 | 0.245449 |
| nurse | Girl | 91.3 | 0.444893 | 0.390956 |
| school psychologist | Girl | 90.4 | 0.309917 | 0.274872 |
| receptionist | Girl | 90 | 0.367575 | 0.356266 |
| vet | Girl | 89.8 | 0.30818 | 0.350992 |
| nutritionist | Girl | 89.6 | 0.280848 | 0.249392 |
| maid | Girl | 88.7 | 0.396666 | 0.425297 |
| therapist | Girl | 87.1 | 0.364104 | 0.330846 |
| social worker | Girl | 86.8 | 0.362299 | 0.365651 |
| sewer | Girl | 86.5 | 0.392354 | 0.525686 |
| paralegal | Girl | 84.8 | 0.333346 | 0.420043 |
| library assistant | Girl | 84.2 | 0.080797 | 0.096904 |
| interior designer | Girl | 83.8 | 0.310031 | 0.264097 |
| manicurist | Girl | 83 | 0.309796 | 0.311654 |
| special education teacher | Girl | 82.8 | 0.275684 | 0.31317 |
| police officer | Boy | 15.8 | 0.407741 | 0.328005 |
| taxi driver | Boy | 12 | 0.324069 | 0.288184 |
| computer architect | Boy | 11.8 | 0.381935 | 0.361483 |
| mechanical engineer | Boy | 9.4 | 0.3109 | 0.288659 |
| truck driver | Boy | 7.9 | 0.360527 | 0.324681 |
| electrical engineer | Boy | 7 | 0.332193 | 0.314071 |
| landscaping worker | Boy | 6.2 | 0.29865 | 0.278257 |
| pilot | Boy | 5.3 | 0.415127 | 0.422821 |
| repair worker | Boy | 5.1 | 0.343244 | 0.30531 |
| firefighter | Boy | 5.1 | 0.326038 | 0.345952 |
| construction worker | Boy | 4.2 | 0.404421 | 0.349674 |
| machinist | Boy | 3.4 | 0.318438 | 0.388574 |
| aircraft mechanic | Boy | 3.2 | 0.260927 | 0.216189 |
| carpenter | Boy | 3.1 | 0.396866 | 0.482018 |
| roofer | Boy | 2.9 | 0.358073 | 0.477668 |
| brickmason | Boy | 2.2 | 0.283633 | 0.299659 |
| plumber | Boy | 2.1 | 0.379595 | 0.514094 |
| electrician | Boy | 1.7 | 0.399175 | 0.399546 |
| vehicle technician | Boy | 1.2 | 0.257796 | 0.238517 |
| crane operator | Boy | 1.1 | 0.363132 | 0.459569 |
여기서도 특정한 편향이 있다고 보기 애매할 정도로 값이 왔다갔다 하네요...?
TNSE를 통해서 feature를 시각화해 확실한 방향성이 있는지 확인해보겠습니다.

또 다른 군집화 또한 보이지 않는다.

여기서도 전혀 찾아볼 수 없네요....
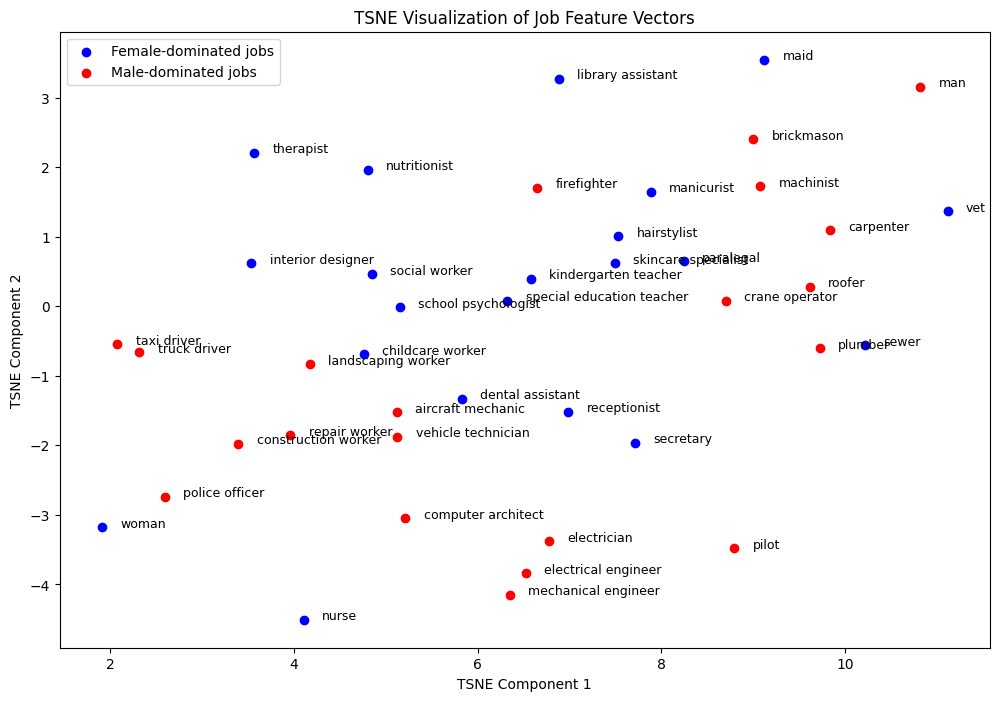
man과 woman을 추가해봤지만 양쪽 끝에 있다 뿐이지 전혀 정돈되지 않은 모습입니다.

여기도요....
지금 까지 16레이어였는데 24레이어로 변경해서 한번 진행해보도록 하겠습니다.
| Job | Gender Dominance | Female Percentage | Cosine Similarity with girl | Cosine Similarity with boy |
| skincare specialist | Female | 98.2 | 0.183896 | 0.175167 |
| kindergarten teacher | Female | 96.8 | 0.201313 | 0.187313 |
| childcare worker | Female | 94.6 | 0.233618 | 0.204102 |
| secretary | Female | 92.5 | 0.199255 | 0.189488 |
| hairstylist | Female | 92.4 | 0.194229 | 0.192112 |
| dental assistant | Female | 92 | 0.145983 | 0.12946 |
| nurse | Female | 91.3 | 0.240469 | 0.226662 |
| school psychologist | Female | 90.4 | 0.199914 | 0.179647 |
| receptionist | Female | 90 | 0.231864 | 0.207373 |
| vet | Female | 89.8 | 0.116139 | 0.124447 |
| nutritionist | Female | 89.6 | 0.203156 | 0.174122 |
| maid | Female | 88.7 | 0.142082 | 0.139369 |
| therapist | Female | 87.1 | 0.257627 | 0.23953 |
| social worker | Female | 86.8 | 0.244797 | 0.221558 |
| sewer | Female | 86.5 | 0.167628 | 0.172477 |
| paralegal | Female | 84.8 | 0.176281 | 0.188429 |
| library assistant | Female | 84.2 | 0.055279 | 0.052736 |
| interior designer | Female | 83.8 | 0.155428 | 0.139924 |
| manicurist | Female | 83 | 0.240344 | 0.222585 |
| special education teacher | Female | 82.8 | 0.203276 | 0.183266 |
| police officer | Male | 15.8 | 0.21867 | 0.182992 |
| taxi driver | Male | 12 | 0.220355 | 0.1933 |
| computer architect | Male | 11.8 | 0.214976 | 0.195234 |
| mechanical engineer | Male | 9.4 | 0.206557 | 0.188666 |
| truck driver | Male | 7.9 | 0.225139 | 0.209364 |
| electrical engineer | Male | 7 | 0.207019 | 0.188141 |
| landscaping worker | Male | 6.2 | 0.19653 | 0.17895 |
| pilot | Male | 5.3 | 0.236793 | 0.236432 |
| repair worker | Male | 5.1 | 0.281485 | 0.259632 |
| firefighter | Male | 5.1 | 0.211171 | 0.212282 |
| construction worker | Male | 4.2 | 0.249591 | 0.209322 |
| machinist | Male | 3.4 | 0.183905 | 0.190897 |
| aircraft mechanic | Male | 3.2 | 0.18299 | 0.170139 |
| carpenter | Male | 3.1 | 0.222211 | 0.232715 |
| roofer | Male | 2.9 | 0.201749 | 0.207536 |
| brickmason | Male | 2.2 | 0.187944 | 0.189682 |
| plumber | Male | 2.1 | 0.209998 | 0.210054 |
| electrician | Male | 1.7 | 0.222483 | 0.212226 |
| vehicle technician | Male | 1.2 | 0.148544 | 0.132306 |
| crane operator | Male | 1.1 | 0.242226 | 0.229937 |
음.... 여기서도 cos 유사도는 되게 별로네요....?
이 표는 man과 woman으로 두고 푼 cos 유사도 입니다.
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | 0.247797 | 0.194322 |
| kindergarten teacher | Female | 96.8 | 0.313062 | 0.18366 |
| childcare worker | Female | 94.6 | 0.400103 | 0.197539 |
| secretary | Female | 92.5 | 0.270496 | 0.186289 |
| hairstylist | Female | 92.4 | 0.255863 | 0.21141 |
| dental assistant | Female | 92 | 0.237729 | 0.12324 |
| nurse | Female | 91.3 | 0.317287 | 0.231716 |
| school psychologist | Female | 90.4 | 0.334626 | 0.171646 |
| receptionist | Female | 90 | 0.353504 | 0.22003 |
| vet | Female | 89.8 | 0.136677 | 0.174374 |
| nutritionist | Female | 89.6 | 0.305264 | 0.178819 |
| maid | Female | 88.7 | 0.14222 | 0.135275 |
| therapist | Female | 87.1 | 0.370287 | 0.17982 |
| social worker | Female | 86.8 | 0.388765 | 0.208608 |
| sewer | Female | 86.5 | 0.187976 | 0.29267 |
| paralegal | Female | 84.8 | 0.217172 | 0.227265 |
| library assistant | Female | 84.2 | 0.100643 | 0.035872 |
| interior designer | Female | 83.8 | 0.243949 | 0.117371 |
| manicurist | Female | 83 | 0.346683 | 0.561003 |
| special education teacher | Female | 82.8 | 0.345291 | 0.16804 |
| police officer | Male | 15.8 | 0.410808 | 0.180951 |
| taxi driver | Male | 12 | 0.388704 | 0.183195 |
| computer architect | Male | 11.8 | 0.327138 | 0.208445 |
| mechanical engineer | Male | 9.4 | 0.309647 | 0.151924 |
| truck driver | Male | 7.9 | 0.360862 | 0.17753 |
| electrical engineer | Male | 7 | 0.318052 | 0.146075 |
| landscaping worker | Male | 6.2 | 0.370279 | 0.120557 |
| pilot | Male | 5.3 | 0.267154 | 0.212619 |
| repair worker | Male | 5.1 | 0.462964 | 0.180298 |
| firefighter | Male | 5.1 | 0.292514 | 0.17753 |
| construction worker | Male | 4.2 | 0.443905 | 0.203085 |
| machinist | Male | 3.4 | 0.213048 | 0.157416 |
| aircraft mechanic | Male | 3.2 | 0.312354 | 0.12882 |
| carpenter | Male | 3.1 | 0.25291 | 0.255213 |
| roofer | Male | 2.9 | 0.215583 | 0.272131 |
| brickmason | Male | 2.2 | 0.203943 | 0.154185 |
| plumber | Male | 2.1 | 0.244214 | 0.305246 |
| electrician | Male | 1.7 | 0.310555 | 0.143423 |
| vehicle technician | Male | 1.2 | 0.232757 | 0.152375 |
| crane operator | Male | 1.1 | 0.343778 | 0.263669 |
대부분 여자쪽이 cos 유사도가 높아서 이건 뭐....
일단 시각화도 한번 해보긴 해야죠...


음... 이번엔 8번 레이어도...
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | 0.405341 | 0.304255 |
| kindergarten teacher | Female | 96.8 | 0.383008 | 0.301889 |
| childcare worker | Female | 94.6 | 0.391139 | 0.287552 |
| secretary | Female | 92.5 | 0.453903 | 0.357609 |
| hairstylist | Female | 92.4 | 0.389928 | 0.324667 |
| dental assistant | Female | 92 | 0.258027 | 0.168323 |
| nurse | Female | 91.3 | 0.458547 | 0.342229 |
| school psychologist | Female | 90.4 | 0.331246 | 0.248281 |
| receptionist | Female | 90 | 0.357404 | 0.278085 |
| vet | Female | 89.8 | 0.371181 | 0.364601 |
| nutritionist | Female | 89.6 | 0.339745 | 0.242513 |
| maid | Female | 88.7 | 0.555928 | 0.458847 |
| therapist | Female | 87.1 | 0.407176 | 0.298072 |
| social worker | Female | 86.8 | 0.508688 | 0.39149 |
| sewer | Female | 86.5 | 0.547029 | 0.474971 |
| paralegal | Female | 84.8 | 0.417665 | 0.358631 |
| library assistant | Female | 84.2 | 0.159827 | 0.149318 |
| interior designer | Female | 83.8 | 0.353571 | 0.244492 |
| manicurist | Female | 83 | 0.387122 | 0.612024 |
| special education teacher | Female | 82.8 | 0.40541 | 0.307201 |
| police officer | Male | 15.8 | 0.388537 | 0.285806 |
| taxi driver | Male | 12 | 0.30301 | 0.251088 |
| computer architect | Male | 11.8 | 0.426636 | 0.326642 |
| mechanical engineer | Male | 9.4 | 0.342135 | 0.250907 |
| truck driver | Male | 7.9 | 0.367503 | 0.272133 |
| electrical engineer | Male | 7 | 0.419489 | 0.306664 |
| landscaping worker | Male | 6.2 | 0.326514 | 0.226061 |
| pilot | Male | 5.3 | 0.475483 | 0.391149 |
| repair worker | Male | 5.1 | 0.370203 | 0.278574 |
| firefighter | Male | 5.1 | 0.345793 | 0.244363 |
| construction worker | Male | 4.2 | 0.414182 | 0.306116 |
| machinist | Male | 3.4 | 0.364647 | 0.306591 |
| aircraft mechanic | Male | 3.2 | 0.218859 | 0.149743 |
| carpenter | Male | 3.1 | 0.469476 | 0.411972 |
| roofer | Male | 2.9 | 0.47436 | 0.418287 |
| brickmason | Male | 2.2 | 0.283209 | 0.224034 |
| plumber | Male | 2.1 | 0.566133 | 0.475443 |
| electrician | Male | 1.7 | 0.468038 | 0.348518 |
| vehicle technician | Male | 1.2 | 0.301237 | 0.222791 |
| crane operator | Male | 1.1 | 0.504272 | 0.422049 |
왜 여자가 다 높은지 이해가 안되네요.....
GPT한테 말해서 코드 좀 고쳐달라고 했는데 과연...
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | 0.405341 | 0.304255 |
| kindergarten teacher | Female | 96.8 | 0.383008 | 0.301889 |
| childcare worker | Female | 94.6 | 0.391139 | 0.287552 |
| secretary | Female | 92.5 | 0.453903 | 0.357609 |
| hairstylist | Female | 92.4 | 0.389928 | 0.324667 |
| dental assistant | Female | 92 | 0.258027 | 0.168323 |
| nurse | Female | 91.3 | 0.458547 | 0.342229 |
| school psychologist | Female | 90.4 | 0.331246 | 0.248281 |
| receptionist | Female | 90 | 0.357404 | 0.278085 |
| vet | Female | 89.8 | 0.371181 | 0.3646 |
| nutritionist | Female | 89.6 | 0.339745 | 0.242513 |
| maid | Female | 88.7 | 0.555928 | 0.458847 |
| therapist | Female | 87.1 | 0.407175 | 0.298072 |
| social worker | Female | 86.8 | 0.508688 | 0.39149 |
| sewer | Female | 86.5 | 0.547029 | 0.474971 |
| paralegal | Female | 84.8 | 0.417665 | 0.358631 |
| library assistant | Female | 84.2 | 0.159827 | 0.149318 |
| interior designer | Female | 83.8 | 0.353571 | 0.244492 |
| manicurist | Female | 83 | 0.387122 | 0.612024 |
| special education teacher | Female | 82.8 | 0.40541 | 0.307201 |
| police officer | Male | 15.8 | 0.388537 | 0.285806 |
| taxi driver | Male | 12 | 0.30301 | 0.251088 |
| computer architect | Male | 11.8 | 0.426636 | 0.326642 |
| mechanical engineer | Male | 9.4 | 0.342135 | 0.250907 |
| truck driver | Male | 7.9 | 0.367503 | 0.272133 |
| electrical engineer | Male | 7 | 0.419489 | 0.306664 |
| landscaping worker | Male | 6.2 | 0.326514 | 0.226061 |
| pilot | Male | 5.3 | 0.475483 | 0.391149 |
| repair worker | Male | 5.1 | 0.370203 | 0.278574 |
| firefighter | Male | 5.1 | 0.345793 | 0.244363 |
| construction worker | Male | 4.2 | 0.414182 | 0.306116 |
| machinist | Male | 3.4 | 0.364647 | 0.306591 |
| aircraft mechanic | Male | 3.2 | 0.218859 | 0.149743 |
| carpenter | Male | 3.1 | 0.469476 | 0.411972 |
| roofer | Male | 2.9 | 0.47436 | 0.418287 |
| brickmason | Male | 2.2 | 0.283209 | 0.224034 |
| plumber | Male | 2.1 | 0.566133 | 0.475443 |
| electrician | Male | 1.7 | 0.468038 | 0.348518 |
| vehicle technician | Male | 1.2 | 0.301237 | 0.222791 |
| crane operator | Male | 1.1 | 0.504272 | 0.422049 |
동일하네요 ㅎㅎ,.....


도저히 군집이 보이지 않네요...
이번에는 PCA를 진행한 후에 COS 유사도를 구하는 것으로 변경하였습니다.
Feature의 차원수가 65000차원이 넘어가서...
| Job | Gender Dominance | Female Percentage | Cosine Similarity with Woman | Cosine Similarity with Man |
| skincare specialist | Female | 98.2 | -0.19681 | -0.26029 |
| kindergarten teacher | Female | 96.8 | -0.16023 | -0.15596 |
| childcare worker | Female | 94.6 | -0.25054 | -0.30546 |
| secretary | Female | 92.5 | 0.16238949024719976 | 0.087834 |
| hairstylist | Female | 92.4 | -0.33054 | -0.17093 |
| dental assistant | Female | 92 | -0.19767 | -0.20021 |
| nurse | Female | 91.3 | 0.12125738117926611 | 0.029434895795313585 |
| school psychologist | Female | 90.4 | -0.34924 | -0.27798 |
| receptionist | Female | 90 | -0.33877 | -0.22639 |
| vet | Female | 89.8 | -0.02908 | 0.11708006054862408 |
| nutritionist | Female | 89.6 | -0.17777 | -0.2193 |
| maid | Female | 88.7 | 0.38307043846142336 | 0.2523360686341649 |
| therapist | Female | 87.1 | -0.04124 | -0.09823 |
| social worker | Female | 86.8 | 0.08358 | -0.00531 |
| sewer | Female | 86.5 | 0.21770541089823284 | 0.18230598861912314 |
| paralegal | Female | 84.8 | -0.27474 | -0.13365 |
| library assistant | Female | 84.2 | -0.33992 | -0.15869 |
| interior designer | Female | 83.8 | -0.07029 | -0.12871 |
| manicurist | Female | 83 | -0.22675 | 0.49256168532186656 |
| special education teacher | Female | 82.8 | -0.06123 | -0.10257 |
| police officer | Male | 15.8 | -0.04289 | -0.0902 |
| taxi driver | Male | 12 | -0.11897 | -0.07653 |
| computer architect | Male | 11.8 | -0.08658 | -0.27449 |
| mechanical engineer | Male | 9.4 | -0.15122 | -0.17058 |
| truck driver | Male | 7.9 | -0.06683 | -0.10263 |
| electrical engineer | Male | 7 | -0.05818 | -0.13694 |
| landscaping worker | Male | 6.2 | -0.44607 | -0.41409 |
| pilot | Male | 5.3 | 0.16081872172536063 | 0.10847355955477823 |
| repair worker | Male | 5.1 | -0.19385 | -0.20943 |
| firefighter | Male | 5.1 | -0.10681 | -0.14003 |
| construction worker | Male | 4.2 | -0.03449 | -0.0879 |
| machinist | Male | 3.4 | -0.36179 | -0.20148 |
| aircraft mechanic | Male | 3.2 | -0.31942 | -0.26494 |
| carpenter | Male | 3.1 | -0.02438 | 0.069184 |
| roofer | Male | 2.9 | -0.10883 | 0.033033092268708625 |
| brickmason | Male | 2.2 | -0.28875 | -0.19416 |
| plumber | Male | 2.1 | 0.22440353244086522 | 0.15013727584185604 |
| electrician | Male | 1.7 | -0.03262 | -0.13606 |
| vehicle technician | Male | 1.2 | -0.18722 | -0.18556 |
| crane operator | Male | 1.1 | 0.14478430627401268 | 0.088762 |
흐........
또 편향이 없네요
모델을 바꿔서 진행할지 고민해 봐야 겠습니다.
일단 코드입니다.
import os
from setproctitle import setproctitle
setproctitle("")
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
from tqdm import tqdm
import plotly.express as px
import pandas as pd
import numpy as np
# Imports for displaying vis in Colab / notebook
torch.set_grad_enabled(False)
# For the most part I'll try to import functions and classes near where they are used
# to make it clear where they come from.
if torch.backends.mps.is_available():
device = "mps"
else:
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Device: {device}")
sae_id = f"blocks.{8}.hook_resid_pre"
from sae_lens.toolkit.pretrained_saes_directory import get_pretrained_saes_directory
from sae_lens import SAE, HookedSAETransformer
model = HookedSAETransformer.from_pretrained("mistral-7b", device = device)
sae, cfg_dict, sparsity = SAE.from_pretrained(
release = "mistral-7b-res-wg", # <- Release name
sae_id = sae_id, # <- SAE id (not always a hook point!)
device = device
)저기서 레이어를 바꿔가며 넣으면 됩니다.
import numpy as np
import pandas as pd
# 샘플 직업과 성별 지배 데이터
jobs_female_dominated = {
"skincare specialist": 98.2,
"kindergarten teacher": 96.8,
"childcare worker": 94.6,
"secretary": 92.5,
"hairstylist": 92.4,
"dental assistant": 92.0,
"nurse": 91.3,
"school psychologist": 90.4,
"receptionist": 90.0,
"vet": 89.8,
"nutritionist": 89.6,
"maid": 88.7,
"therapist": 87.1,
"social worker": 86.8,
"sewer": 86.5,
"paralegal": 84.8,
"library assistant": 84.2,
"interior designer": 83.8,
"manicurist": 83.0,
"special education teacher": 82.8
}
jobs_male_dominated = {
"police officer": 15.8,
"taxi driver": 12.0,
"computer architect": 11.8,
"mechanical engineer": 9.4,
"truck driver": 7.9,
"electrical engineer": 7.0,
"landscaping worker": 6.2,
"pilot": 5.3,
"repair worker": 5.1,
"firefighter": 5.1,
"construction worker": 4.2,
"machinist": 3.4,
"aircraft mechanic": 3.2,
"carpenter": 3.1,
"roofer": 2.9,
"brickmason": 2.2,
"plumber": 2.1,
"electrician": 1.7,
"vehicle technician": 1.2,
"crane operator": 1.1
}
# 가상의 함수 정의 (실제 모델 연동 필요)
def calculate_cos_similarity(job, reference_word, model = model, sae = sae, sae_id = sae_id):
_, cache_job = model.run_with_cache_with_saes(job, saes=[sae])
job_vector = cache_job[sae_id + '.hook_sae_acts_post'][0, 1: , :].cpu().numpy().sum(0)/len(cache_job[sae_id + '.hook_sae_acts_post'][0, 1 : , :])
_, cache_ref = model.run_with_cache_with_saes(reference_word, saes=[sae])
ref_vector = cache_ref[sae_id + '.hook_sae_acts_post'][0, 1: , :].cpu().numpy().sum(0)/len(cache_ref[sae_id + '.hook_sae_acts_post'][0, 1 : , :])
cos_similarity = np.dot(job_vector, ref_vector) / (
np.linalg.norm(job_vector) * np.linalg.norm(ref_vector)
)
return cos_similarity
# 각 직업에 대해 `woman`, `man`과의 코사인 유사도를 계산하여 저장
similarities = []
for job, percentage in jobs_female_dominated.items():
sim_with_woman = calculate_cos_similarity(job, "woman")
sim_with_man = calculate_cos_similarity(job, "man")
similarities.append({
"Job": job,
"Gender Dominance": "Female",
"Female Percentage": percentage,
"Cosine Similarity with Woman": sim_with_woman,
"Cosine Similarity with Man": sim_with_man
})
for job, percentage in jobs_male_dominated.items():
sim_with_woman = calculate_cos_similarity(job, "woman")
sim_with_man = calculate_cos_similarity(job, "man")
similarities.append({
"Job": job,
"Gender Dominance": "Male",
"Female Percentage": percentage,
"Cosine Similarity with Woman": sim_with_woman,
"Cosine Similarity with Man": sim_with_man
})
# 결과를 DataFrame으로 출력
df = pd.DataFrame(similarities)man과 woman 각각의 cos 유사도를 구해서 출력해줍니다.
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
# 샘플 직업과 성별 지배 데이터
jobs_female_dominated = {
"skincare specialist": 98.2,
"kindergarten teacher": 96.8,
"childcare worker": 94.6,
"secretary": 92.5,
"hairstylist": 92.4,
"dental assistant": 92.0,
"nurse": 91.3,
"school psychologist": 90.4,
"receptionist": 90.0,
"vet": 89.8,
"nutritionist": 89.6,
"maid": 88.7,
"therapist": 87.1,
"social worker": 86.8,
"sewer": 86.5,
"paralegal": 84.8,
"library assistant": 84.2,
"interior designer": 83.8,
"manicurist": 83.0,
"special education teacher": 82.8
}
jobs_male_dominated = {
"police officer": 15.8,
"taxi driver": 12.0,
"computer architect": 11.8,
"mechanical engineer": 9.4,
"truck driver": 7.9,
"electrical engineer": 7.0,
"landscaping worker": 6.2,
"pilot": 5.3,
"repair worker": 5.1,
"firefighter": 5.1,
"construction worker": 4.2,
"machinist": 3.4,
"aircraft mechanic": 3.2,
"carpenter": 3.1,
"roofer": 2.9,
"brickmason": 2.2,
"plumber": 2.1,
"electrician": 1.7,
"vehicle technician": 1.2,
"crane operator": 1.1
}
# 1. 모든 직업 벡터를 수집해 PCA 모델 학습
def get_feature_vector(word, model, sae, sae_id):
_, cache = model.run_with_cache_with_saes(word, saes=[sae])
vector = cache[sae_id + '.hook_sae_acts_post'][0, 1:, :].cpu().numpy()
return vector.sum(axis=0) / np.count_nonzero(vector)
all_vectors = []
for job in list(jobs_female_dominated.keys()) + list(jobs_male_dominated.keys()) + ["woman", "man"]:
all_vectors.append(get_feature_vector(job, model, sae, sae_id))
target_dim = 20
pca_model = PCA(n_components=target_dim)
pca_model.fit(all_vectors) # PCA 모델 학습
# 2. 코사인 유사도 계산 함수
def calculate_cos_similarity(job, reference_word, pca_model, model, sae, sae_id):
job_vector = get_feature_vector(job, model, sae, sae_id)
ref_vector = get_feature_vector(reference_word, model, sae, sae_id)
job_vector_reduced = pca_model.transform(job_vector.reshape(1, -1))
ref_vector_reduced = pca_model.transform(ref_vector.reshape(1, -1))
cos_similarity = np.dot(job_vector_reduced, ref_vector_reduced.T) / (
np.linalg.norm(job_vector_reduced) * np.linalg.norm(ref_vector_reduced)
)
return cos_similarity[0][0] # 스칼라 값 반환
# 3. 각 직업에 대해 `woman`, `man`과의 코사인 유사도를 계산하여 저장
similarities = []
for job, percentage in jobs_female_dominated.items():
sim_with_woman = calculate_cos_similarity(job, "woman", pca_model, model, sae, sae_id)
sim_with_man = calculate_cos_similarity(job, "man", pca_model, model, sae, sae_id)
similarities.append({
"Job": job,
"Gender Dominance": "Female",
"Female Percentage": percentage,
"Cosine Similarity with Woman": sim_with_woman,
"Cosine Similarity with Man": sim_with_man
})
for job, percentage in jobs_male_dominated.items():
sim_with_woman = calculate_cos_similarity(job, "woman", pca_model, model, sae, sae_id)
sim_with_man = calculate_cos_similarity(job, "man", pca_model, model, sae, sae_id)
similarities.append({
"Job": job,
"Gender Dominance": "Male",
"Female Percentage": percentage,
"Cosine Similarity with Woman": sim_with_woman,
"Cosine Similarity with Man": sim_with_man
})
# 4. 결과를 DataFrame으로 출력
df = pd.DataFrame(similarities)
print(df)여기선 PCA 후 COS 유사도를 구하려고 했는데 성능이 좋은지는 모르겠습니다....
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 가상의 함수 정의 (실제 모델 연동 필요)
def get_feature_vector(job, model, sae, sae_id):
_, cache_job = model.run_with_cache_with_saes(job, saes=[sae])
job_vector = cache_job[sae_id + '.hook_sae_acts_post'][0, 1:, :].cpu().numpy().sum(0) / \
len(cache_job[sae_id + '.hook_sae_acts_post'][0, 1:, :])
return job_vector
# 직업과 성별 지배 데이터 및 Feature 벡터 수집
jobs_female_dominated = {
"skincare specialist": 98.2, "kindergarten teacher": 96.8, "childcare worker": 94.6,
"secretary": 92.5, "hairstylist": 92.4, "dental assistant": 92.0, "nurse": 91.3,
"school psychologist": 90.4, "receptionist": 90.0, "vet": 89.8, "nutritionist": 89.6,
"maid": 88.7, "therapist": 87.1, "social worker": 86.8, "sewer": 86.5, "paralegal": 84.8,
"library assistant": 84.2, "interior designer": 83.8, "manicurist": 83.0, "special education teacher": 82.8,
"woman" : 99.9#, "female" : 99.0
}
jobs_male_dominated = {
"police officer": 15.8, "taxi driver": 12.0, "computer architect": 11.8,
"mechanical engineer": 9.4, "truck driver": 7.9, "electrical engineer": 7.0,
"landscaping worker": 6.2, "pilot": 5.3, "repair worker": 5.1, "firefighter": 5.1,
"construction worker": 4.2, "machinist": 3.4, "aircraft mechanic": 3.2,
"carpenter": 3.1, "roofer": 2.9, "brickmason": 2.2, "plumber": 2.1,
"electrician": 1.7, "vehicle technician": 1.2, "crane operator": 1.1,
"man" : 0.1#, "male" : 0.11
}
# 모든 직업의 Feature 벡터 수집
feature_vectors = []
labels = []
dominance = []
for job in jobs_female_dominated.keys():
feature_vector = get_feature_vector(job, model, sae, sae_id)
feature_vectors.append(feature_vector)
labels.append(job)
dominance.append("Female")
for job in jobs_male_dominated.keys():
feature_vector = get_feature_vector(job, model, sae, sae_id)
feature_vectors.append(feature_vector)
labels.append(job)
dominance.append("Male")
# numpy 배열로 변환
feature_vectors = np.array(feature_vectors)
# 차원 축소 및 시각화 (t-SNE 사용)
tsne = TSNE(n_components=2, random_state=0)
reduced_features = tsne.fit_transform(feature_vectors)
# 시각화
plt.figure(figsize=(12, 8))
for i, label in enumerate(labels):
color = 'blue' if dominance[i] == 'Female' else 'red'
plt.scatter(reduced_features[i, 0], reduced_features[i, 1], color=color)
plt.text(reduced_features[i, 0] + 0.2, reduced_features[i, 1], label, fontsize=9)
plt.xlabel("TSNE Component 1")
plt.ylabel("TSNE Component 2")
plt.title("TSNE Visualization of Job Feature Vectors")
plt.scatter([], [], color='blue', label="Female-dominated jobs")
plt.scatter([], [], color='red', label="Male-dominated jobs")
#plt.legend(["Female-dominated jobs", "Male-dominated jobs"])
plt.legend()
plt.show()TSNE를 통한 시각화인데 실패한 것 같습니다 ㅎㅎ....
import numpy as np
import matplotlib.pyplot as plt
from umap import UMAP # 수정된 부분
from sklearn.decomposition import PCA
# PCA를 먼저 적용하여 고차원 축소 후 UMAP 적용
def visualize_with_umap(feature_vectors, labels, dominance):
# PCA로 50차원까지 축소
pca = PCA(n_components=min(20, feature_vectors.shape[1]), random_state=0)
pca_features = pca.fit_transform(feature_vectors)
# UMAP으로 2차원 축소
umap_model = UMAP(n_components=2, random_state=0)
reduced_features = umap_model.fit_transform(pca_features)
# 시각화
plt.figure(figsize=(12, 8))
for i, label in enumerate(labels):
color = 'blue' if dominance[i] == 'Female' else 'red'
plt.scatter(reduced_features[i, 0], reduced_features[i, 1], color=color)
plt.text(reduced_features[i, 0] + 0.2, reduced_features[i, 1], label, fontsize=9)
plt.xlabel("UMAP Component 1")
plt.ylabel("UMAP Component 2")
plt.title("UMAP Visualization of Job Feature Vectors")
plt.scatter([], [], color='blue', label="Female-dominated jobs")
plt.scatter([], [], color='red', label="Male-dominated jobs")
#plt.legend(["Female-dominated jobs", "Male-dominated jobs"])
plt.legend()
plt.show()
# numpy 배열로 변환
feature_vectors = np.array(feature_vectors)
# UMAP을 통한 시각화 호출
visualize_with_umap(feature_vectors, labels, dominance)여기는 UMAP을 통한 시각화 입니다.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 가정: Bias-in-Bios에서 특정 직업에 대한 샘플이 있다면, 직업과 성별 단어에 대한 벡터를 추출하는 코드
def get_feature_vector(word, model, sae, sae_id):
_, cache = model.run_with_cache_with_saes(word, saes=[sae])
vector = cache[sae_id + '.hook_sae_acts_post'][0, 1:, :].cpu().numpy()
return vector.sum(axis=0) / np.count_nonzero(vector)
# Bias-in-Bios에서 각 직업에 대해 성별 관련 코사인 유사도 계산
def calculate_bias_in_bios_scores(jobs, genders, model, sae, sae_id):
results = []
for job in jobs:
job_vector = get_feature_vector(job, model, sae, sae_id)
gender_similarities = {}
for gender in genders:
gender_vector = get_feature_vector(gender, model, sae, sae_id)
# 코사인 유사도 계산
sim = cosine_similarity(job_vector.reshape(1, -1), gender_vector.reshape(1, -1))[0][0]
gender_similarities[gender] = sim
results.append({
"Job": job,
"Cosine Similarity with Gender": gender_similarities
})
return results
# Bias-in-Bios 직업과 성별 리스트
jobs = ["doctor", "nurse", "engineer", "teacher", "scientist"] # Bias-in-Bios의 직업 리스트로 변경 가능
genders = ["man", "woman", "he", "she"] # 성별 관련 단어
# 편향 점수 계산
bias_scores = calculate_bias_in_bios_scores(jobs, genders, model, sae, sae_id)
# 결과 출력
for score in bias_scores:
print(f"Job: {score['Job']}")
for gender, sim in score["Cosine Similarity with Gender"].items():
print(f" Cosine similarity with {gender}: {sim}")여기선 직업만 넣어주면 Cos 유사도 다 구해줍니다.
아마 다음 번엔 모델을 변경해서 진행해볼 것 같습니다.
'인공지능 > XAI' 카테고리의 다른 글
| Sparse Autoencoder를 통한 LLM의 Bias 줄이기 - 성에 따른 직업 3 (0) | 2024.11.28 |
|---|---|
| Sparse Autoencoder를 통한 LLM의 Bias 줄이기 - 성에 따른 직업 2 (0) | 2024.11.27 |
| SelfIE 주간 세미나 발표 (1) | 2024.11.25 |
| SelfIE : 세미나 발표 준비 (1) | 2024.11.24 |
| 🤳SelfIE: Self-Interpretation of Large Language Model Embeddings - 세미나 준비 (1) | 2024.11.18 |