강화학습은 시스템은 복잡하지만 결과는 간단할 때 사용할 수 있다.
관찰되는 정보만으로 action을 정하고, 리워드가 큰 행동이 바람직하다.
미래의 평균 누적 보상을 최대화 하는 행동을 선택
즉각 보상과 장기 보상의 균형이 필요하다.
높은 보상을 얻기 위해 전략이 필요하다.
히스토리 - 과거 관찰, 행동, 보상의 시퀸스 - (a1,o1,r1,...,at,ot,rt)
에이전트는 히스토리에 기반해 행동 선택
state는 다음 시점에 무슨 일이 일어나는지에 대한 정보 st = f(ht)
세계 상태 - 에이전트와 무관한 정보를 포함하는 실제 세계 상태
다음 관찰과 보상을 어떻게 생성할지에 대한 실제 상태
일부 숨겨지거나 에이전트에게 알려지지 않을 수 있다. - MDP가 아닐 때
에이전트에게 알려진 경우에도 불필요한 정보가 포함될 수 있다.
에이전트 상태 - 에이전트의 (상태에 의한)내부 표현
어떻게 행동할지 결정을 내리기 위해 사용
히스토리 함수로 표현된다. st = f(ht)
알고리즘의 상태(에피소드가 끝날 때 까지 남은 결정의 수)와 같은 메타 정보가 포함될 수 있다.
마르코프 가정 - 미래는 주어진 현재 이전의 과거와 무관하다.
정보 상태 : 충분한 히스토리의 통계
P(s(t+1)|st,at) = P(s(t+1),ht,at)
결정론적(deterministic) : 주어진 히스토리 및 행동, 단일 관찰 및 보상
- 로봇 공학 및 제어에서 일반적인 가정 - 정책에 s를 넣으면 a가 나온다.
확률론거(Stochastic) : 주어진 히스토리 및 행동, 많은 잠재력 관찰 및 보상
- 고객, 환자, 모델링하기 어려운 영역에 대한 일반적인 가정 - 정책에 s와 a를 넣고 그에 대한 확률값
모델 : 에이전트의 행동에 따라 세상이 어떻게 변화하는지 표현
정책 : 에이전트의 상태에 행동을 매핑시키는 함수
가치 함수 : 특정 정책을 따를 때 얻어지는 미래의 보상
모델 : 행동에 따라 세계가 어덯게 변하는지에 대한 에이전트 관점에서의 표현
Transition / dynamics model - 에이전트의 다음 state를 예측
Reward - 즉각 보상을 예측
가치 - 미래 얻어질 감쇠 보상의 합
상태 가치 함수 : 현재 시점 t에서 s 상태이고, 정책을 따를 때 미래 얻어질 감쇠 보상의 합
상태와 행동의 좋고 나쁨을 정향화 하는데 사용될 수 있어 정책을 비교하여 어떻게 행동할지 결정
평가 : 주어진 정책을 때를 때 예상되는 보상을 예측
제어 : 최상의 정책을 찾는 것으로 최적화
개발/활용(Exploitation) : 경험을 바탕으로 좋은 보상을 얻을 것으로 예상되는 행동 선택
탐색/탐험(Exploration) : 미래에 더 나은 결정을 내릴 수 있도록 새로운 행동 시도
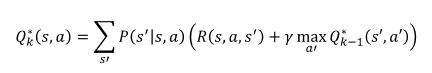


코드 진행 확인하기
Q가 다 0이다 == 시도를 잘 안하게 된다. == 계속 같은 것만 뽑는다.
랜덤을 집어넣어보자 - 조금 성장하긴 했으나 많이는 안높다.
입실론을 통해 랜덤과 맥스를 섞어서 쓴다. == 성능이 조금 늘었다.
입실론을 너무 줄이면 성능이 안나온다. == 성능 감소
할인률과 학습률을 넣었더니 그래도 좀 학습한다== 성능 약간 상승
Q 테이블에 랜덤 노이즈를 더한다. - 나은 선택지 중 한개를 선택할 수 있어 좋은 학습을 보여준다.
미끄러짐 끄면 엄청 잘한다.
Q로 Q를 업데이트 할 때 업데이트하는 Q가 자기 자신을 참조할 때 문제가 생긴다. ~ 딥러닝 지식이 필요
목표 불안정 (Target unstable) : Q목표가 Q 자체에 따라 달라지며 동적인 목표를 쫓게된다.
Q의 i.i.d 특성 : Q의 파라미터를 업데이트하면서 다른 추정값들에 대해 동시에 영향을 미치게 된다. - 환경의 상태가 함께 변한다.
샘플의 i.i.d. 특성 : 샘플이 무작위로 섞이고 배치는 동일한 분포를 갖도록 한다. 동일 배치 내 샘플은 서로 독립적이고, 그렇지 않으면 모델은 오버피팅되고, 일반화 성능이 떨어질 수 있다.
해결방안
타겟 네트워크 : 두개의 신경망을 만들어서 목표로 하는 심층망은 따라오는 신경망이 충분히 따라온 다음에 업데이트하여 100% i.i.d.는 아니더라도 심각한 문제 상황이 발생하지 않는다.
경험 재생 : 경험 재생 버퍼를 구축하여 무작위로 샘플링하면 독립적이고, i.i.d.에 가까운 입력을 만들 수 있어 학습에 안정적인 입력 데이터 셋을 형성할 수 있다.


'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 입문 기말고사 간단 정리 (1) | 2024.06.16 |
|---|---|
| 생성형 인공지능 기말고사 대비 문제만들기 (2) | 2024.06.15 |
| 딥러닝 개론 12 ~ 13장 생성모델 (0) | 2024.06.15 |
| 딥러닝개론 10 ~ 11 장 AutoEncoder (1) | 2024.06.15 |
| 딥러닝개론 8~9장 순환 신경망 (0) | 2024.06.15 |