여긴 코드가 안보이네요
https://ieeexplore.ieee.org/document/10483658
Slice and Conquer: A Planar-to-3D Framework for Efficient Interactive Segmentation of Volumetric Images
Interactive segmentation methods have been investigated to address the potential need for additional refinement in automatic segmentation via human-in-the-loop techniques. For accurate segmentation of 3D images, we propose Slice-and-Conquer, a novel planar
ieeexplore.ieee.org
WACV 2024 Open Access Repository
Slice and Conquer: A Planar-to-3D Framework for Efficient Interactive Segmentation of Volumetric Images Wonwoo Cho, Dongmin Choi, Hyesu Lim, Jinho Choi, Saemee Choi, Hyun-seok Min, Sungbin Lim, Jaegul Choo; Proceedings of the IEEE/CVF Winter Conference on
openaccess.thecvf.com
논문 요약 및 주요 내용
논문 제목:
Slice and Conquer: A Planar-to-3D Framework for Efficient Interactive Segmentation of Volumetric Images
저자:
Wonwoo Cho, Dongmin Choi, Hyesu Lim, Jinho Choi, Saemee Choi, Hyun-seok Min, Sungbin Lim, Jaegul Choo
개요:
이 논문은 볼륨 이미지를 효율적으로 인터랙티브하게 분할하는 새로운 프레임워크인 "Slice and Conquer (SnC)"를 제안합니다. 이 프레임워크는 2D 상호작용 분할과 3D 분할을 결합하여 최소한의 사용자 상호작용으로 정확한 3D 마스크를 생성합니다. SnC는 사용자 상호작용을 통해 2D 슬라이스를 먼저 분할하고, 이를 기반으로 3D 마스크를 생성하는 두 단계의 파이프라인을 사용합니다.
주요 내용:
- 문제 정의:
- 3D 이미지 분할은 의료 영상에서 매우 중요하지만, 자동화된 방법은 아직 정확성과 견고성 면에서 개선이 필요합니다.
- 기존의 상호작용 방법은 주로 2D 이미지에 중점을 두었으며, 3D 이미지에 적합한 방법은 상대적으로 부족합니다.
- 제안된 방법 (Slice and Conquer):
- 2D 상호작용 분할:
- 사용자가 3D 볼륨에서 단일 슬라이스를 선택하여 상호작용적으로 분할합니다.
- 이 단계에서 생성된 2D 마스크는 강력한 형태 프라이어로 작용합니다.
- 3D 분할:
- 2D 상호작용을 통해 생성된 마스크를 기반으로 3D 모델이 정확한 3D 마스크를 생성합니다.
- 슬라이스 추천:
- 다음 상호작용 슬라이스를 추천하여 사용자의 인지적 부담을 줄이고 효율성을 높입니다.
- 2D 상호작용 분할:
- 기술적 세부사항:
- 2D와 3D 모델을 순차적으로 훈련하고, 2D 모델의 학습된 파라미터를 3D 모델의 초기 상태로 사용합니다.
- ACS 컨볼루션을 사용하여 3D 모델의 효율성을 높였습니다.
- 마스크 주의 모듈을 도입하여 마스크 지도를 효과적으로 활용합니다.
- 후처리 기법을 사용하여 2D 결과와 3D 예측의 정렬을 개선합니다.
- 실험 결과:
- 다양한 3D 생의학 이미지를 사용한 실험에서 제안된 SnC 프레임워크의 효과를 입증했습니다.
- SnC는 기존 방법들보다 높은 정확도와 효율성을 보였습니다.
- 특히 데이터가 부족한 상황에서도 견고한 성능을 유지했습니다.
- 기여점:
- 새로운 2단계 파이프라인을 통해 사용자 상호작용을 최소화하면서도 정확한 3D 분할을 가능하게 했습니다.
- 2D와 3D 모델 간의 파라미터 전이를 통해 효율적인 학습을 구현했습니다.
- 슬라이스 추천 알고리즘을 통해 사용자의 인지적 부담을 줄였습니다.
논문이 해결한 문제:
이 논문은 3D 이미지의 정확한 분할을 위해 필요한 사용자 상호작용을 최소화하면서도 높은 정확도를 유지할 수 있는 방법을 제안합니다. 기존의 3D 분할 방법들이 갖고 있는 높은 계산 비용과 인지적 부담 문제를 해결했습니다. SnC 프레임워크는 2D와 3D 모델을 결합하여 효율적이고 견고한 3D 분할을 가능하게 했습니다.
자동적으로 segment의 개선이 필요했다. Slice and-Conquer -> 1. inter active segmentation 2. guided 3D segmentation
1. 2D에 따른 Segmentation -> 3D 마스크 구성에 사용 2. planner guidence을 사용하여 최소한의 계산만으로 3D 구현
2단계가 끝날 때 주석을 달아 3D 공간에 대한 부담 감소
요약한 내용이 논문의 내용을 잘 반영하고 있지만, 일부 내용은 좀 더 명확하게 표현될 필요가 있습니다. 원문에서 언급된 주요 포인트를 포함하여 조금 더 자세하게 정리해보았습니다:
- 자동 세그먼트 개선 필요성:
- 기존의 자동 세그멘테이션 방법들은 여전히 정확성과 견고성을 개선할 필요가 있습니다.
- Slice-and-Conquer 프레임워크:
- 단계 1: 인터랙티브 세그멘테이션:
- 사용자들이 2D 슬라이스에서 상호작용적으로 세그멘테이션을 수행합니다.
- 이 단계에서 생성된 2D 예측 결과는 강력한 형태 프라이어로 작용합니다.
- 단계 2: 가이드된 3D 세그멘테이션:
- 2D 상호작용 세그멘테이션 결과를 사용하여 최소한의 사용자 상호작용으로 3D 마스크를 생성합니다.
- 이때 planar guidance를 통해 계산 비용을 최소화합니다.
- 단계 1: 인터랙티브 세그멘테이션:
- 부담 감소:
- 2단계가 끝날 때 시스템은 주석을 달아야 할 다음 슬라이스를 추천하여 사용자의 인지적 부담을 줄입니다.
- 이를 통해 사용자는 3D 공간 전체를 탐색할 필요 없이 몇몇 추천된 2D 슬라이스에만 주석을 달아 3D 세그멘테이션을 완성할 수 있습니다.
요약
자동 세그멘테이션의 개선 필요성을 해결하기 위해 Slice-and-Conquer 프레임워크는 2단계 접근 방식을 사용합니다. 첫 번째 단계에서는 사용자가 2D 슬라이스를 상호작용적으로 세그멘테이션하고, 두 번째 단계에서는 이 결과를 사용하여 최소한의 계산으로 3D 마스크를 생성합니다. 마지막으로 시스템은 다음에 주석을 달아야 할 슬라이스를 추천하여 사용자의 인지적 부담을 줄입니다.
DIOS라는 처음 보는 개념이 나오네요
Deep Interactive Object Selection (DIOS)는 딥러닝을 활용하여 이미지에서 객체를 상호작용적으로 선택하는 방법입니다. 이 방법은 사용자 상호작용을 통해 이미지의 특정 객체를 선택하고 분할하는 데 사용됩니다. DIOS는 특히 Convolutional Neural Networks (CNNs)를 기반으로 한 최초의 딥 인터랙티브 세그멘테이션 방법 중 하나로 잘 알려져 있습니다.
DIOS의 주요 특징과 과정
- 사용자 상호작용:
- DIOS는 사용자가 이미지에서 특정 지점을 클릭하여 관심 있는 객체를 선택하도록 합니다. 이러한 클릭은 보통 객체의 내부와 외부를 나타내기 위해 양성(positive) 클릭과 음성(negative) 클릭으로 구분됩니다.
- 예를 들어, 사용자가 분할하고자 하는 객체 내부에 양성 클릭을 하고, 객체 외부에 음성 클릭을 합니다.
- 클릭 인코딩:
- 사용자의 클릭 정보를 Gaussian 또는 다른 형태로 인코딩하여 CNN에 입력으로 사용합니다.
- 클릭 지점을 중심으로 하는 Gaussian 맵을 생성하여 네트워크에 추가 입력으로 제공함으로써 네트워크가 객체와 배경을 구분할 수 있도록 돕습니다.
- CNN을 활용한 세그멘테이션:
- 클릭 인코딩 맵과 원본 이미지를 CNN에 입력으로 제공하여 객체를 세그멘테이션합니다.
- 네트워크는 사용자가 클릭한 지점을 중심으로 객체의 경계를 학습하고 분할 결과를 생성합니다.
- 반복적 학습:
- 초기 분할 결과가 만족스럽지 않을 경우, 사용자는 추가적인 클릭을 통해 네트워크의 출력을 개선할 수 있습니다.
- 이러한 상호작용 과정을 반복함으로써 점진적으로 분할 결과를 개선합니다.
DIOS의 장점
- 상호작용적이고 직관적인 접근: 사용자가 직접 객체를 선택하고 분할 결과를 확인하며 수정할 수 있어 직관적입니다.
- 딥러닝 기반의 높은 정확도: CNN을 활용하여 복잡한 객체의 경계를 정확하게 분할할 수 있습니다.
- 반복적 개선 가능: 사용자가 여러 번의 상호작용을 통해 점진적으로 분할 결과를 개선할 수 있습니다.
DIOS의 한계
- 계산 비용: CNN을 반복적으로 사용하기 때문에 계산 비용이 높을 수 있습니다.
- 사용자 부담: 사용자가 여러 번의 클릭을 통해 분할 결과를 개선해야 하므로 사용자에게 부담이 될 수 있습니다.
요약
Deep Interactive Object Selection (DIOS)는 CNN을 기반으로 사용자가 상호작용적으로 이미지를 분할할 수 있도록 하는 방법입니다. 사용자의 클릭을 인코딩하여 네트워크에 제공하고, 네트워크는 이를 바탕으로 객체를 분할합니다. 반복적인 상호작용을 통해 점진적으로 분할 결과를 개선할 수 있으며, 이는 직관적이고 높은 정확도의 분할 결과를 제공합니다.
성능은 괜찮지만 리소스를 많이 잡아먹는 객체 구분해주는 DIOS...
여태까지 주목받지 못하여 최적의 알고리즘(인공지능)이 등장하지 않았고, 많은 리소스를 사용하며, 사용자가 수정까지 해야만 했었다.
그리고 데이터의 부족으로 부피 구조를 효율적으로 학습하지 못했다. Zhou et al이 제한한 방식도 전체 3D를 고려하지 않았기 때문에 2D가 불안정했다.
SnC의 새로운 두가지 파이프라인
1. 3D Data에서 추출한 단일 슬라이스에 segment하여 이름 부여하기
2. 1에서 얻은 데이터와 3D 데이터를 통해 정확한 3D segment진행
효율적으로 정확한 분할을 위해
1. 2D, 3D를 연속적으로 훈련
2. 3D Convolution -> ACS Convolution : transfer learning에 효과적
3. mask attention을 3D 모델에도 적용
4. 3D 모델에 후처리 진행하여 2D 결과와 3D mask 간 정렬성 강화
네, 요약하신 내용은 전반적으로 정확합니다. 그러나 더 명확하게 표현하기 위해 약간의 수정을 제안합니다:
- 2D와 3D 모델을 연속적으로 훈련:
- 2D 모델을 먼저 훈련한 후, 그 학습된 파라미터를 3D 모델의 초기 상태로 사용하여 연속적으로 훈련합니다.
- 3D Convolution을 ACS Convolution으로 대체:
- 3D 컨볼루션을 ACS(Asymmetric Convolutional Skeleton) 컨볼루션으로 대체하여 transfer learning에 효과적으로 활용합니다.
- 마스크 주의 모듈(mask attention)을 3D 모델에도 적용:
- 마스크 주의 모듈을 3D 모델에 적용하여 2D 마스크 지도를 더 효과적으로 활용합니다.
- 3D 모델에 후처리 진행:
- 2D 결과와 3D 마스크 간의 정렬성을 강화하기 위해 3D 모델의 후처리 단계를 추가합니다.
따라서, 정리한 내용을 다음과 같이 수정하면 좋을 것입니다:
- 2D와 3D 모델을 연속적으로 훈련하여 효율성을 높입니다.
- 3D Convolution을 ACS Convolution으로 대체하여 transfer learning에 효과적으로 활용합니다.
- 마스크 주의 모듈(mask attention)을 3D 모델에도 적용하여 마스크 지도를 효과적으로 활용합니다.
- 3D 모델의 후처리 단계를 통해 2D 결과와 3D 마스크 간의 정렬성을 강화합니다.
CNN을 활용한 interactive segmentation를 DIOS에서 말해줌. 이전의 반복에서 생성된 예측을 활용, 대량의 주석 데이터를 활용하여 강력함을 입증
Volumetric Propagation of Interactions: 메디컬에서 선택에 의한 segmentation은 모호한 경우가 많다. -> Geodesic encoding 사용 및 개선 BUT 많은 양의 데이터가 필요하고, 높은 리소스, 전이 학습에 어려움이 있다.
Slice Propagation for 3D Interactive Segmentation: 3D -> 2D . 슬라이스 전파 사용, 3D 정보가 손실될 가능성이 있고, 추론의 지속적인 실행에 따른 실행 시간 증가, 지속적인 전파에 의해 소실 가능성이 있지만 고해상도 2D DATA를 얻을 수 있고, 전이 학습에 효율적이다.
그리고 아까 말했던 파이프라인을 통해 효율성을 증가시켰다.
요약 및 설명
2. Related Work and Our Contribution
2.1. Interactive Segmentation
Deep Interactive Segmentation:
- DIOS (Deep Interactive Object Selection):
- DIOS는 CNN(Convolutional Neural Networks)을 활용한 인터랙티브 세그멘테이션의 가능성을 처음 제시했습니다.
- Mahadevan et al.는 이 방법을 개선하기 위해 반복적 훈련 전략을 제안했습니다.
- 이후 다양한 기술들이 제안되어 인터랙티브 세그멘테이션의 견고성을 향상시켰습니다.
- Konstantin Sofiiuk, Ilia A Petrov, and Anton Konushin의 연구자들은 이전 반복에서 생성된 마스크 예측을 활용하고, 대규모의 고품질 주석 데이터를 활용하여 강력한 인터랙티브 세그멘테이션 성능을 입증했습니다.
Volumetric Propagation of Interactions:
- 2D 자연 이미지의 인터랙티브 세그멘테이션에서는 클릭 기반 상호작용 및 변형(스크리블, 바운딩 박스 등)을 주로 사용합니다.
- 그러나 이러한 2D 인터페이스를 위한 인터랙티브 방법은 종종 3D 이미지를 포함하는 의료 응용에 적합하지 않습니다.
- 의료 이미지는 일반적으로 낮은 대비와 모호한 경계를 가지기 때문에 사용자 상호작용 정보를 전체 볼륨에 효과적으로 전파하는 것이 중요합니다.
- Wang et al.는 클릭 상호작용을 효과적으로 볼륨에 전파하기 위해 기존의 Gaussian 또는 디스크 인코딩 대신 Geodesic 인코딩을 사용했습니다.
- Luo et al.는 이러한 인코딩을 개선하여 더 나은 일반화 가능성을 제안했습니다.
- 그러나 이러한 인코딩 방법은 각 상호작용마다 높은 계산 비용이 필요하며, 볼륨 모델은 대규모의 파라미터를 요구합니다. 이는 작은 데이터셋에서 성능 저하를 초래할 수 있으며, 3D 의료 이미지에 적합한 전이 학습을 활용하는 데 어려움을 겪습니다.
Slice Propagation for 3D Interactive Segmentation:
- Zhou et al.는 비디오 객체 세그멘테이션 원칙을 따르는 슬라이스 전파 접근법을 제안했습니다.
- 이 방법은 상호작용한 슬라이스에서 이웃 슬라이스로, 그리고 그 후 나머지 슬라이스로 정보를 전파합니다.
- 즉, 모델은 이미 주석이 달린 슬라이스의 지도를 받아 2D CNN을 사용하여 볼륨 이미지를 슬라이스 단위로 분할합니다.
- 슬라이스 전파 방법은 고해상도 2D 슬라이스 형태의 볼륨 이미지를 처리할 수 있으며, 전이 학습 기술의 이점을 얻을 수 있습니다.
- 하지만 이 방법은 3D 정보를 무시할 수 있으며, 각 2D 주석 라운드가 끝날 때마다 여러 모델 추론이 필요하여 실행 시간을 크게 증가시킬 수 있습니다.
- 또한, 주석된 슬라이스에서의 지도가 전파가 계속됨에 따라 약해질 가능성이 높습니다.
설명
이 섹션은 기존 연구를 바탕으로 이 논문의 기여를 설명합니다. 특히, 인터랙티브 세그멘테이션, 볼륨 상호작용의 전파, 그리고 3D 인터랙티브 세그멘테이션을 위한 슬라이스 전파 방법에 대해 다룹니다.
- 인터랙티브 세그멘테이션: DIOS와 같은 초기 연구는 CNN을 사용하여 사용자가 제공하는 힌트를 기반으로 이미지에서 객체를 분할하는 방법을 제시했습니다. 이후의 연구들은 반복 훈련과 대규모 데이터셋을 활용하여 이 방법의 견고성을 향상시켰습니다.
- 볼륨 상호작용 전파: 의료 이미지는 3D 볼륨을 포함하기 때문에 2D 방법은 적합하지 않습니다. Geodesic 인코딩과 같은 방법을 사용하여 사용자 상호작용을 전체 볼륨에 효과적으로 전파하려는 시도가 있었습니다.
- 슬라이스 전파: 비디오 객체 세그멘테이션의 원칙을 따르는 슬라이스 전파 방법은 2D 슬라이스를 통해 3D 볼륨을 분할합니다. 이 방법은 고해상도 2D 슬라이스를 처리할 수 있지만, 3D 정보를 무시하고 실행 시간이 길어질 수 있습니다.
이 논문은 이러한 기존 방법들의 한계를 극복하고, 보다 효율적이고 정확한 3D 세그멘테이션을 가능하게 하는 새로운 프레임워크인 Slice and Conquer를 제안합니다.
2.2. Our Contribution 요약 및 설명
우리의 기여 (Our Contribution):
이 논문은 기존 방법의 문제를 해결하기 위해 새로운 두 단계 파이프라인을 제안합니다. 이 파이프라인의 세부 사항은 다음 섹션에서 설명됩니다. 우리의 접근 방식은 다음과 같은 요소들을 고려하여 설계되었습니다:
- 2단계 반복 파이프라인:
- 1) 2D 인터랙티브 세그멘테이션
- 2) 가이드된 3D 세그멘테이션
- 사용자는 소수의 2D 슬라이스만 연속적으로 주석을 달아 정확한 3D 마스크를 구축할 수 있습니다.
- 3축 2D 마스크 예측:
- 첫 번째 단계의 3축 2D 마스크 예측은 두 번째 단계에서 강력한 형태 프라이어로 작용합니다.
- 이를 통해 볼륨 전파를 위한 복잡한 3D 거리 맵 인코딩(예: 지오데식)을 필요로 하지 않습니다.
- SnC 파이프라인의 이점:
- 2D 모델에서 3D 모델로의 가중치 파라미터 전이를 가능하게 합니다.
- 첫 번째 단계의 결과를 기반으로 두 번째 단계에서 3D 결과의 후처리를 수행합니다.
- 이를 통해 3D 모델은 단일 전방 패스를 통해 더 정교한 결과를 제공합니다.
설명
주요 기여:
- 2단계 반복 파이프라인:
- 이 방법은 두 단계로 구성된 파이프라인을 사용하여 3D 볼륨 이미지를 세그멘테이션합니다.
- 첫 번째 단계에서는 사용자가 2D 슬라이스를 선택하고 상호작용적으로 세그멘테이션합니다.
- 두 번째 단계에서는 첫 번째 단계에서 생성된 2D 마스크를 기반으로 3D 세그멘테이션을 수행합니다.
- 형태 프라이어로서의 3축 2D 마스크:
- 첫 번째 단계에서 생성된 3축의 2D 마스크 예측은 두 번째 단계에서 강력한 형태 프라이어로 사용됩니다.
- 이는 복잡한 3D 거리 맵 인코딩을 필요로 하지 않으며, 효율적으로 3D 세그멘테이션을 수행할 수 있게 합니다.
- 파라미터 전이 및 후처리:
- SnC 파이프라인은 2D 모델에서 학습된 가중치 파라미터를 3D 모델로 전이시킬 수 있습니다.
- 또한, 첫 번째 단계의 결과를 기반으로 두 번째 단계에서 3D 결과의 후처리를 수행하여 더 정교한 3D 세그멘테이션 결과를 제공합니다.
이러한 기여를 통해 제안된 방법은 기존 방법들의 한계를 극복하고, 더 효율적이고 정확한 3D 볼륨 이미지 세그멘테이션을 가능하게 합니다.
NFL??
교차 엔트로피에 가중치를 부여햐여 잘 예측된 샘플의 손실을 줄이고, 잘못 예측된 샘플의 손실을 증가시킨다.
데이터의 클래스 불균형이 있는 경우 사용
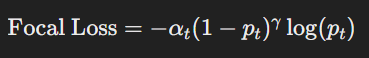
그럼 일단 3D를 2D slice로 다 나눈 다음에 2D를 segmentation 진행 후 3D에 퍼트리기, 그 후 계속 반복하다가 만족스러운 결과가 나오면 종료하는거야? - ㅇㅇ
3. Proposed Method 요약 및 설명
개요
우리의 제안인 Slice and Conquer (SnC)은 3D 이미지에 대한 세그멘테이션 마스크를 처음부터 생성하거나 기존 마스크를 정제하는 것을 목표로 합니다. SnC에서 3D 인터랙티브 세그멘테이션의 단일 반복(iteration)은 2D 인터랙티브 세그멘테이션(내부 반복)과 가이드된 3D 세그멘테이션(외부 반복)으로 구성됩니다. 이 과정에서 슬라이스 추천 알고리즘이 새로운 3D 정제를 시작하도록 도와줍니다. 논문 전반에 걸쳐, 우리는 클릭 기반 인터랙티브 스킴을 고려합니다.
프로세스
- 2D 인터랙티브 세그멘테이션 (Sec. 3.1):
- 사용자는 3D 이미지 I3D에서 단일 슬라이스 I2Dt를 추출하여 세그멘테이션을 수행합니다.
- 이 단계에서는 기존의 2D 인터랙티브 세그멘테이션 방법을 따라 2D 세그멘테이션 마스크 M2Dt를 생성합니다.
- 가이드된 3D 세그멘테이션 (Sec. 3.2):
- 누적된 클릭 상호작용과 M2Di(t=1)을 목표 전경 영역의 형태 프라이어로 사용하여, 3D 세그멘테이션 모델 f3D가 세그멘테이션 마스크 M3Dt를 생성합니다.
- 슬라이스 추천 (Sec. 3.3):
- 첫 번째 반복(t=1)에서는 사용자가 첫 번째 슬라이스 I2D1를 선택하여 주석을 달고 M3D1을 획득합니다.
- 이후, 만족스러운 3D 마스크가 구축될 때까지 이 과정을 반복할 수 있습니다. 사용자가 결과를 정제하는 것을 돕기 위해 시스템은 다음에 주석을 달 슬라이스를 자동으로 선택합니다.
2D 인터랙티브 세그멘테이션
- 사용자가 긍정 및 부정 클릭을 제공하여 오분할된 영역을 정제합니다.
- 사용자는 단일 슬라이스에 집중하여 2D 마스크를 완성합니다.
- 각 반복에서 클릭 지도를 업데이트하고, 2D 세그멘테이션 모델 f2D가 이를 기반으로 새로운 2D 마스크를 생성합니다.
3D 세그멘테이션
- 전이 학습을 통해 2D 모델의 가중치를 3D 모델에 통합합니다.
- Mean-ACS 컨볼루션을 사용하여 3D 컨볼루션 필터를 세 개의 2D 컨볼루션 필터 조합으로 해석하여 효율적인 계산을 지원합니다.
- 마스크 주의 모듈을 사용하여 3D 모델의 세그멘테이션 예측을 개선합니다.
슬라이스 추천 및 후처리
- 3D 마스크 예측의 품질이 만족스럽지 않을 경우, 다음 주석할 슬라이스를 추천합니다.
- 사용자의 노력을 최소화하기 위해 시스템은 다음 주석할 슬라이스를 선택합니다.
- 각 반복에서 3D 결과가 2D 마스크를 반영하도록 후처리를 수행하여 정렬성을 강화합니다.
이러한 방법들을 통해 SnC 프레임워크는 3D 볼륨 이미지의 효율적이고 정확한 세그멘테이션을 가능하게 합니다.
3. Proposed Method 요약 및 수식 설명
개요
우리의 제안인 Slice and Conquer (SnC)은 3D 이미지에 대한 세그멘테이션 마스크를 처음부터 생성하거나 기존 마스크를 정제하는 것을 목표로 합니다. SnC에서 3D 인터랙티브 세그멘테이션의 단일 반복(iteration)은 2D 인터랙티브 세그멘테이션(내부 반복)과 가이드된 3D 세그멘테이션(외부 반복)으로 구성됩니다. 슬라이스 추천 알고리즘을 통해 SnC는 새로운 3D 정제를 시작할 수 있습니다. 논문 전반에 걸쳐 클릭 기반 인터랙티브 스킴을 고려하며, 이는 바운딩 박스 및 스크리블과 같은 다른 상호작용 유형으로 쉽게 확장될 수 있습니다.
2D 인터랙티브 세그멘테이션 (Sec. 3.1)
- 2D 인터랙티브 세그멘테이션:
- 사용자는 3D 이미지 I3D에서 단일 슬라이스 I2Dt를 추출하여 세그멘테이션을 수행합니다.
- 기존의 2D 인터랙티브 세그멘테이션 방법을 따라 f2D는 해당 2D 세그멘테이션 마스크 M2Dt를 생성합니다.
- 가이드된 3D 세그멘테이션:
- 누적된 클릭 상호작용과 M2Di(t=1)을 형태 프라이어로 사용하여, 3D 세그멘테이션 모델 f3D가 세그멘테이션 마스크 M3Dt를 생성합니다.
- 슬라이스 추천:
- 첫 번째 반복(t=1)에서는 사용자가 첫 번째 슬라이스 I2D1를 선택하여 주석을 달고 M3D1을 획득합니다.
- 이후, 만족스러운 3D 마스크가 구축될 때까지 이 과정을 반복할 수 있습니다. 사용자가 결과를 정제하는 것을 돕기 위해 시스템은 다음 주석할 슬라이스를 자동으로 선택합니다.
손실 함수 및 수식 설명
- 2D 인터랙티브 세그멘테이션의 손실 함수 (L2Dseg):
- 2D 모델 f2D는 normalized focal loss (NFL)을 사용하여 최적화됩니다.
- 이 손실 함수는 2D 세그멘테이션의 정확도를 높이는 데 사용됩니다.
- 3D 세그멘테이션의 손실 함수 (L3Dseg):
- 3D 모델 f3D는 L2Dseg의 3D 버전인 L3Dseg로 훈련됩니다.
- 3D 모델은 또한 마스크 주의 모듈(mask attention module)을 사용하여 {M2Di}t=1에서 얻은 마스크 가이던스를 효과적으로 반영합니다.
- 마스크 주의 모듈은 또 다른 NFL 기반 손실 Lattn으로 훈련됩니다.
- 종합 손실 함수:
- 최종적으로 2D 및 3D 모델의 손실 함수는 다음과 같이 정의됩니다:
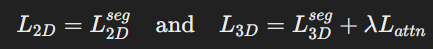
- 여기서 각 항은 NFL이고, λ는 하이퍼파라미터입니다.
- 최종적으로 2D 및 3D 모델의 손실 함수는 다음과 같이 정의됩니다:
알고리즘 요약
- 알고리즘 1: Slice and Conquer Pipeline
- 3D 이미지 I3D와 2D 및 3D 모델 {f2D, f3D}, 기존(또는 빈) 마스크 M3D0을 입력으로 받습니다.
- t = 1로 설정하고 반복을 시작합니다.
- 선택된 또는 추천된 I2Dt를 I3D에서 추출합니다.
- P2Dt,0와 M2Dt,0을 초기화합니다.
- s = 1로 설정하고 내부 반복을 시작합니다.
- 새로운 클릭을 추가하여 P2Dt,s를 업데이트합니다.
- M2Dt,s를 f2D(I2Dt ⊕ M2Dt,s-1, P2Dt,s)를 사용하여 업데이트합니다.
- P2Dt와 M2Dt를 각각 P2Dt,s와 M2Dt,s로 설정합니다.
- 만족스러운 M2Dt,s를 얻을 때까지 s를 증가시키며 반복합니다.
- {P2Di}t=1을 집계하여 P2D→3Dt로 변환합니다.
- {M2Di}t=1을 집계하여 M2D→3Dt로 변환합니다.
- f3D(I3D ⊕ M3Dt-1, P2D→3Dt ⊕ M2D→3Dt)를 사용하여 M3Dt를 생성합니다.
- Eq. (2)를 통해 다음 2D 슬라이스를 추천합니다.
- Eq. (3)의 후처리를 통해 M3Dt를 업데이트합니다.
- t를 증가시키며 반복합니다.
- 만족스러운 M3Dt를 얻을 때까지 반복합니다.
- 최종 3D 세그멘테이션 마스크 M3D를 반환합니다.
추가 수식 설명
- 슬라이스 추천:
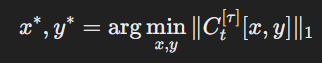
- 여기서 ( C^{[\tau]}_t[x, y] )는 임계값 τ보다 큰 픽셀 수준의 최대 softmax 확률 점수로 정의된 신뢰도 맵입니다.
- 이는 신뢰도가 낮은 픽셀이 많은 2D 슬라이스를 선택합니다.
- 3D 마스크 후처리:

- 여기서 ( \phi_n )는 임의의 변환 연산으로, optical flow estimation 및 warping operation을 사용하여 3D 마스크를 2D 마스크와 정렬시킵니다.
이 설명은 논문의 방법론과 수식을 명확하게 이해하는 데 도움이 될 것입니다.
3. Proposed Method 요약
개요:
- SnC(Slice and Conquer)는 3D 이미지의 세그멘테이션 마스크를 처음부터 생성하거나 기존 마스크를 정제하는 것을 목표로 합니다.
- SnC의 단일 반복(iteration)은 2D 인터랙티브 세그멘테이션(내부 반복)과 가이드된 3D 세그멘테이션(외부 반복)으로 구성됩니다.
- 슬라이스 추천 알고리즘을 통해 SnC는 새로운 3D 정제를 시작할 수 있습니다.
- 논문 전반에 걸쳐 클릭 기반 인터랙티브 스킴을 고려하며, 이는 바운딩 박스 및 스크리블과 같은 다른 상호작용 유형으로 쉽게 확장될 수 있습니다.
세부 과정:
- 2D 인터랙티브 세그멘테이션 (Sec. 3.1):
- 사용자는 3D 이미지 I3D에서 단일 슬라이스 I2Dt를 추출하여 세그멘테이션을 수행합니다.
- 기존의 2D 인터랙티브 세그멘테이션 방법을 따라 f2D는 해당 2D 세그멘테이션 마스크 M2Dt를 생성합니다.
- 가이드된 3D 세그멘테이션 (Sec. 3.2):
- 누적된 클릭 상호작용과 M2Di(t=1)을 형태 프라이어로 사용하여, 3D 세그멘테이션 모델 f3D가 세그멘테이션 마스크 M3Dt를 생성합니다.
- 슬라이스 추천 (Sec. 3.3):
- 첫 번째 반복(t=1)에서는 사용자가 첫 번째 슬라이스 I2D1를 선택하여 주석을 달고 M3D1을 획득합니다.
- 이후, 만족스러운 3D 마스크가 구축될 때까지 이 과정을 반복할 수 있습니다.
- 시스템은 다음 주석할 슬라이스를 자동으로 선택하여 사용자가 결과를 정제하는 것을 돕습니다.
손실 함수:
- 2D 인터랙티브 세그멘테이션의 손실 함수 (L2Dseg):
- 2D 모델 f2D는 normalized focal loss (NFL)을 사용하여 최적화됩니다.
- 3D 세그멘테이션의 손실 함수 (L3Dseg):
- 3D 모델 f3D는 L2Dseg의 3D 버전인 L3Dseg로 훈련됩니다.
- 마스크 주의 모듈을 사용하여 {M2Di}t=1에서 얻은 마스크 가이던스를 효과적으로 반영합니다.
- 마스크 주의 모듈은 또 다른 NFL 기반 손실 Lattn으로 훈련됩니다.
- 종합 손실 함수:
- 최종적으로 2D 및 3D 모델의 손실 함수는 다음과 같이 정의됩니다:

- 여기서 각 항은 NFL이고, λ는 하이퍼파라미터입니다.
- 최종적으로 2D 및 3D 모델의 손실 함수는 다음과 같이 정의됩니다:
이 요약은 SnC 방법론의 주요 구성 요소와 그 과정을 명확하게 전달합니다.
3.1. 2D Interactive Segmentation 요약
개요
2D 인터랙티브 세그멘테이션에서는 사용자가 긍정적 및 부정적 클릭을 반복적으로 제공하여 잘못 세그멘테이션된 영역을 정제합니다. 이 클릭 방식은 유연하게 적용될 수 있습니다.
사용자 친화적 환경
SnC의 첫 번째 단계에서는 사용자가 단일 슬라이스 I2Dt에 대해 2D 마스크 M2Dt를 완성하는 데 집중하게 합니다. 이렇게 함으로써 3D 인터랙티브 세그멘테이션에서 사용자의 인지적 부담을 크게 줄일 수 있습니다.
단계 설명:
- t 번째 SnC 반복에서 사용자는 M2Dt,0을 정제하기 시작합니다. 이는 M3Dt-1에서 추출됩니다. t = 1일 때, M2D1,0은 0 행렬이거나 기존 M3D0의 2D 슬라이스일 수 있습니다.
- 긍정적 또는 부정적 클릭을 통해 각각 false-negative 또는 false-positive 세그멘테이션 영역을 표시하면, M2Dt,s-1은 f2D에 의해 M2Dt,s로 정제될 수 있습니다.
- s 번째 2D 정제에서 사용자가 M2Dt,s를 만족스러운 것으로 받아들이면(예: 충분히 높은 정확성) 이를 M2Dt로 확정합니다.
이 과정에서 디스크 클릭 인코딩과 Conv1S 모듈을 사용합니다. 즉, f2D는 (I2Dt ⊕ M2Dt,s-1)과 디스크 인코딩된 클릭 맵 P2Dt,s를 입력으로 받습니다. f2D는 사용자가 단일 2D 슬라이스에 주석을 달도록 하여 3D의 다른 슬라이스를 고려하지 않게 합니다. 이는 사용자 친화적인 상호작용 환경을 제공합니다.
Dense-Hint Generator
2D 모델 f2D는 사용자 친화적인 환경을 제공할 뿐만 아니라, 조밀한 힌트를 생성하는 역할도 합니다. SnC 접근법은 소수의 2D 슬라이스만으로 정확한 세그멘테이션 결과를 구축하는 것을 목표로 하기 때문에, 다음 단계의 f3D가 목표 전경의 형태에 대한 충분한 힌트를 제공받지 못할 수 있습니다. 따라서 M2Dt를 추가적인 가이던스로 사용합니다. 이를 위해 f2D를 훈련하여 세 개의 직교 평면(축, 시상, 관상면)의 2D 슬라이스를 처리하도록 합니다. 이렇게 하면 사용자가 단일 축 슬라이스만 사용할 때 얻을 수 없는 보완적인 형태 정보를 추가로 제공할 수 있습니다.
Algorithm 1: Slice and Conquer Pipeline 요약
입력: 3D 이미지 I3D, 2D 및 3D 모델 {f2D, f3D}, 기존(또는 빈) 마스크 M3D0
출력: 3D 세그멘테이션 마스크 M3D
- t = 1로 설정하고 반복을 시작합니다.
- 선택된 또는 추천된 I2Dt를 I3D에서 추출합니다.
- P2Dt,0와 M2Dt,0을 초기화합니다.
- s = 1로 설정하고 내부 반복을 시작합니다.
- 새로운 클릭을 추가하여 P2Dt,s를 업데이트합니다.
- M2Dt,s를 f2D(I2Dt ⊕ M2Dt,s-1, P2Dt,s)를 사용하여 업데이트합니다.
- P2Dt와 M2Dt를 각각 P2Dt,s와 M2Dt,s로 설정합니다.
- 만족스러운 M2Dt,s를 얻을 때까지 s를 증가시키며 반복합니다.
- {P2Di}t=1을 집계하여 P2D→3Dt로 변환합니다.
- {M2Di}t=1을 집계하여 M2D→3Dt로 변환합니다.
- f3D(I3D ⊕ M3Dt-1, P2D→3Dt ⊕ M2D→3Dt)를 사용하여 M3Dt를 생성합니다.
- Eq. (2)를 통해 다음 2D 슬라이스를 추천합니다.
- Eq. (3)의 후처리를 통해 M3Dt를 업데이트합니다.
- t를 증가시키며 반복합니다.
- 만족스러운 M3Dt를 얻을 때까지 반복합니다.
- 최종 3D 세그멘테이션 마스크 M3D를 반환합니다.
요약
2D 인터랙티브 세그멘테이션 과정은 사용자 클릭을 통해 2D 마스크를 반복적으로 정제하며, 이렇게 생성된 2D 마스크는 3D 세그멘테이션의 가이드로 사용됩니다. 사용자 친화적인 환경을 제공하고, Dense-Hint Generator로서의 역할을 통해 3D 세그멘테이션의 정확성을 높입니다. Algorithm 1은 전체 SnC 파이프라인의 세부 단계를 설명합니다.
3.2. Guided 3D Segmentation 요약
전이 학습 (Transfer Learning)
- 배경: 의료 영상 분석에서는 데이터 부족 문제를 해결하기 위해 사전 학습된 2D 특징 추출기의 가중치를 3D 모델에 적용하는 연구가 진행되었습니다. 예를 들어, 이전 연구들은 ImageNet에서 사전 학습된 2D 가중치를 3D 모델에 전이하면 도메인 차이에도 불구하고 3D 세그멘테이션 정확도를 높일 수 있음을 보여주었습니다.
- 적용: 이러한 기술에서 영감을 받아 SnC 파이프라인을 설계하여 f2D의 가중치를 f3D에 유연하게 통합합니다. 구체적으로, Mean-ACS 컨볼루션 기법을 사용하여 3D 컨볼루션 필터를 축, 시상, 관상면의 세 개의 2D 컨볼루션 필터 조합으로 해석하여 3D 컨볼루션보다 더 효율적인 계산을 지원합니다. f2D는 3D 이미지에서 추출한 세 개의 직교 평면의 2D 슬라이스를 활용하여 훈련되므로, 이 필터들은 대응하는 3D ACS 컨볼루션 필터의 축, 시상, 관상 성분으로 원활하게 전이될 수 있습니다.
마스크 주의 모듈 (Mask Attention Module)
- 설명: f2D의 입력 방법을 약간 수정하여, f3D는 t 번째 SnC 반복에서 (I3D ⊕ M3Dt-1)과 (P2D→3Dt ⊕ M2D→3Dt)를 입력으로 받습니다. 여기서 M2D→3Dt와 P2D→3Dt는 첫 번째 반복 이후 축적된 2D 마스크와 포인트 상호작용을 포함하는 3D 볼륨입니다. I3D, M2D→3Dt, P2D→3Dt는 동일한 차원을 가집니다.
- 기능: M2D→3Dt 마스크는 P2D→3Dt보다 더 강력한 형태 프라이어로 작용하여 M3Dt를 구성하는 데 도움을 줍니다. FCA에서 영감을 받아, f3D에 추가 모듈을 적용하여 마스크 가이던스를 강화합니다. 이 모듈은 Eq. (1)에 제시된 것처럼 3D 세그멘테이션 예측을 생성하도록 훈련됩니다.
요약
SnC 파이프라인은 3D 세그멘테이션 모델을 훈련시키기 위해 2D 모델의 가중치를 유연하게 전이하는 전이 학습 방법을 사용합니다. 또한, 마스크 주의 모듈을 통해 2D 마스크 가이던스를 강화하여 3D 세그멘테이션의 정확성을 높입니다.
3.3. Slice Recommendation and Post-processing 요약
다음 슬라이스 추천
- 목표: SnC 프레임워크는 반복적인 정제를 통해 정확한 3D 마스크 예측을 생성하는 것을 목표로 합니다. 즉, t번째 반복에서 3D 마스크 예측 M3Dt의 품질이 만족스럽지 않으면, I2Dt+1을 선택하여 또 다른 반복을 시작해야 합니다.
- 문제점: 부피가 큰 공간에서 오류가 있는 영역을 수동으로 조사하고 다음 주석할 2D 슬라이스를 선택하는 것은 비효율적일 수 있습니다.
- 해결책: 사용자의 노력을 줄이기 위해 추가 정제가 필요한 슬라이스를 추천하는 것이 필요합니다. 하지만 이러한 과정은 볼륨 세분화에서 도전적인 슬라이스를 찾기 위해 추가 계산 또는 메모리 자원을 필요로 할 수 있습니다.
- 방법: 이전 연구들에서는 품질 평가 모듈이나 여러 예측 결과를 기반으로 한 불확실성 추정 기술을 사용했습니다. 추가 모듈이나 여러 예측을 사용하는 것을 피하기 위해, 우리는 평가 정책을 사용합니다.
- 구현: 각 M3Dt에 대해, 픽셀 수준의 최대 소프트맥스 확률(MSP) 점수를 포함하는 볼륨 신뢰도 맵 Ct를 계산합니다. 그런 다음 Ct의 요소가 임계값 τ보다 큰 경우 1, 그렇지 않으면 0으로 정의된 C[τ]t를 정의합니다. 이 신뢰도 맵을 사용하여, 추천 알고리즘은 I2Dt+1의 후보로 C[τ]t[x∗, y∗]를 선택합니다:
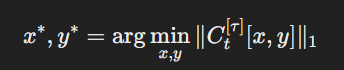
여기서 ∥C[τ]t[x, y]∥1은 C[τ]t의 y번째 축의 L1-노름을 나타내며, 이는 신뢰도가 낮은 픽셀이 많은 2D 슬라이스를 선택합니다. - 추가적인 기술: 더 나은 슬라이스 추천을 위해, 주석된 슬라이스에 인접한 슬라이스를 건너뛰고 엣지 신뢰도 향상 및 LogitNorm 기술을 적용합니다.
3D 마스크 후처리
- 과정: SnC의 각 반복에서, 사용자는 2D 인터랙티브 세그멘테이션을 완료하고 3D 세그멘테이션 예측을 얻습니다. 2D 모델의 클릭 주석 지원 외에도, 사용자가 2D 세그멘테이션을 수동 주석 도구(예: 브러쉬 또는 폴리곤 도구)를 통해 정제할 수 있습니다.
- 문제점: 사용자가 수정한 영역을 유지해야 하지만, f3D의 3D 결과는 각 반복에서 완료된 2D 마스크를 반영하지 않을 수 있습니다.
- 해결책: 이 문제를 해결하기 위해, M3Dt와 사용자 주석 2D 마스크 M2D→3Dt 간의 정렬을 향상시키는 후처리 기법을 제안합니다. M3Dt[x, y]를 x축의 y번째 2D 슬라이스로 정의하고, 다음과 같이 정의할 수 있습니다:

여기서 ϕn은 M3Dt[xn, yn]을 M3Dt로 변환할 수 있는 임의의 연산입니다. 이 방법에서는 optical flow estimation 및 warping operation을 통해 이 연산을 구현합니다. 필요한 벡터 필드는 TV-L1 솔버를 통해 얻을 수 있습니다. - 구체적인 방법: ϕn을 사용하여 M3Dt[xn, yn]과 그 인접 슬라이스를 ϕn(M3Dt[xn, yn + k], max(1 − γ|k|, 0))로 대체합니다. 여기서 γ는 하이퍼파라미터입니다. 정확도 저하를 방지하기 위해 충분히 정확한 2D 마스크에만 후처리 기법을 사용합니다.
성능 비교
- SnC 방법은 여러 볼륨 세분화 방법(자동 및 인터랙티브 방법 포함)과 비교하여 우수한 성능을 보입니다.
- 6번의 반복 후 SnC의 성능을 다른 방법들과 비교한 결과가 표 1에 제시되어 있습니다.
4. Experiments 요약
4.1. Training Details
- 모델 설정:
- f2D: HRNet-18 백본을 사용.
- f3D: f2D에 Mean-ACS 컨볼루션을 적용하여 구성.
- 사전 학습된 가중치를 초기 상태로 사용.
- 훈련 방법:
- 클릭 시뮬레이션 전략 및 반복 훈련 방식 사용.
- AdamWR 옵티마이저와 코사인 학습률 스케줄링 적용.
- 초기 학습률은 0.0003, f2D는 90 epoch, f3D는 120 epoch 훈련.
- 커리큘럼 학습을 적용하여 점진적으로 사용자 클릭 수를 감소시킴.
- f3D 훈련 시, 2D 마스크 입력의 수를 제어하여 성능 향상.
4.2. Datasets
- 데이터셋:
- Medical Segmentation Decathlon (MSD) 데이터셋 사용: 폐종양, 대장암, 좌심방, 간, 췌장, 뇌종양 세그멘테이션.
- 2019 Kidney Tumor Segmentation Challenge (KiTS19) 데이터셋 사용: 신장 및 신장종양 세그멘테이션.
4.3. Compared Models
- 비교 모델:
- nnU-Net: 비인터랙티브 세그멘테이션 기준 모델.
- 3D 버전의 인터랙티브 세그멘테이션 방법 (DIOS, FCA, f-BRS, RITM) 테스트.
- 의료 이미지를 위한 볼륨 세그멘테이션 모델 (DeepIGeoS, MIDeepSeg).
- 슬라이스 전파 방법 VMN과 SnC 비교.
4.4. Evaluation Protocol
- 평가 방법:
- 세그멘테이션 정확도 측정을 위해 Dice Similarity Coefficient (DSC) 사용.
- [34]의 평가 프로토콜을 따름: 6개의 슬라이스 주석을 통한 결과 보고.
- 초기 주석 슬라이스는 가장 큰 전경 영역 인접 슬라이스를 무작위로 선택.
- 2D 마스크 예측이 충분히 정확할 때 (DSC > 0.9) 또는 5번의 클릭 후 다음 단계로 진행.
5. Experimental Results
- 정량적 결과:
- SnC는 이전 방법들보다 더 정확한 볼륨 세그멘테이션 결과를 보여줌.
- MSD 데이터셋에서 SnC의 두 단계 접근 방식이 단일 단계 방법보다 높은 세그멘테이션 정확도를 달성함.
- Table 2에 따르면 SnC는 VMN보다 더 높은 성능을 보임.
- 시각적 데모:
- Figure 4에서 SnC 파이프라인의 인터랙티브 세그멘테이션 과정을 시각적으로 설명.
- 추가된 2D 마스크 가이던스가 세그멘테이션 정확도를 크게 향상시킴.
- 추가 결과:
- 기존 마스크의 정제: SnC는 nnU-Net 마스크 예측을 효과적으로 정제.
- 데이터 부족 상황에서도 SnC는 높은 세그멘테이션 정확도를 유지함.
- 실행 시간 분석: SnC는 VMN 및 3D nnU-Net보다 짧은 실행 시간으로 높은 정확도를 달성.
- Ablation Study:
- SnC 파이프라인의 하위 구성 요소의 영향을 분석.
- 전이 학습, 마스크 주의 모듈, 후처리 방법이 세그멘테이션 성능을 향상시킴.
결론
- SnC는 3D 이미지 세그멘테이션을 위한 새로운 두 단계 접근 방식을 제안.
- 2D 인터랙티브 세그멘테이션 단계는 사용자가 각 반복에서 단일 슬라이스에 집중할 수 있게 하고, 3D 이미지 세그멘테이션을 위한 밀집 힌트를 제공.
- 3D 세그멘테이션 모듈은 2D 마스크 예측을 가이드로 사용하여 3D 마스크를 구성.
- SnC는 반복적인 정제를 위한 유연성을 높이기 위해 주석할 2D 슬라이스를 자동으로 추천.
- 실험 결과 SnC는 이전 방법들보다 효율성과 효과 면에서 우수한 성능을 보임.