1주차 - 비지도 학습
고객들의 방문 로그 데이터를 이용하여 웹 사이트 이동 동선을 표시하는 프로세스 맵을 만들 수 있다.
이 프로세스 맵을 통해서 유입 경로와 유출 결로를 만들어 판매 전략을 수립할 수 있다.
라벨링이 되어 있지 않은 수많은 데이터로부터 데이터의 패턴 등 유용한 정보를 추출하는 것을 비지도 학습이라고 한다.

여태까지는 입력과 정답이 대응되어있는 데이터이다.
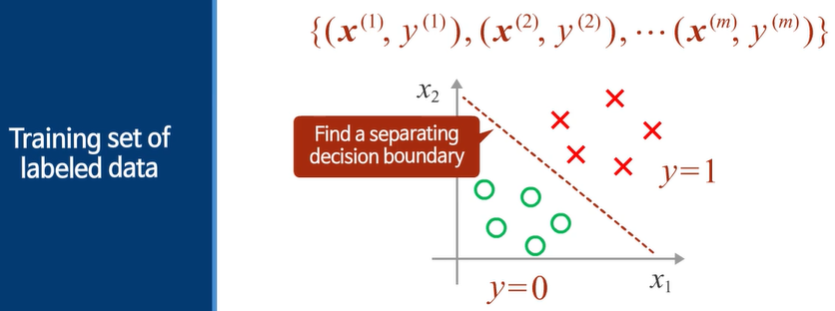
이 분류 경계선을 잘 찾는 것이 일이다.
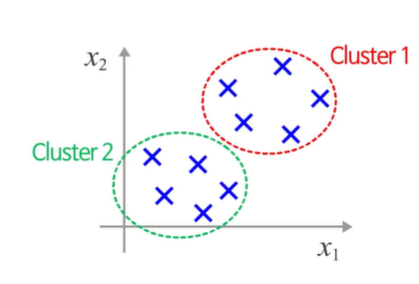
구조적인 특징을 잘 찾는 것이 일이다. 라벨이 존재하지 않는다.
유사한 데이터를 그룹핑하는 클러스터링이 목적이다.
소비자들의 그룹을 소비 패턴에 따라 몇 개의 그룹으로 clustering 할 수 있다.
소비자나 제품을 기준으로 판매 전략을 만들 수 있다.
클러스터링을 통해 패턴을 찾아낼 수 있다!
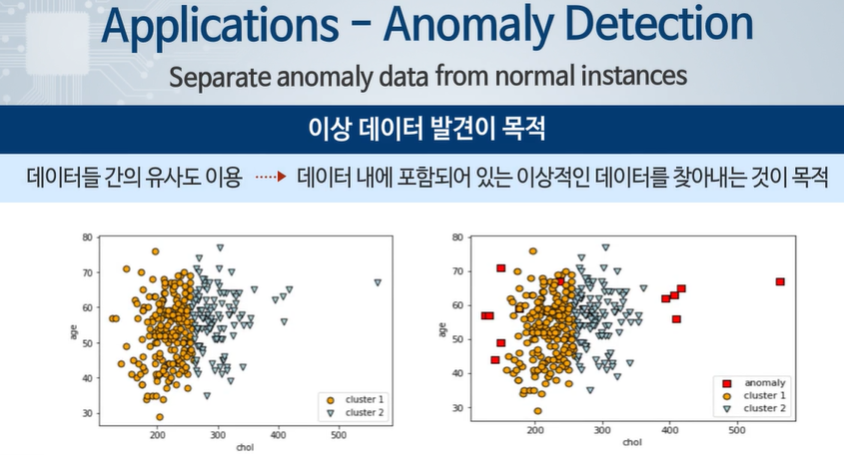
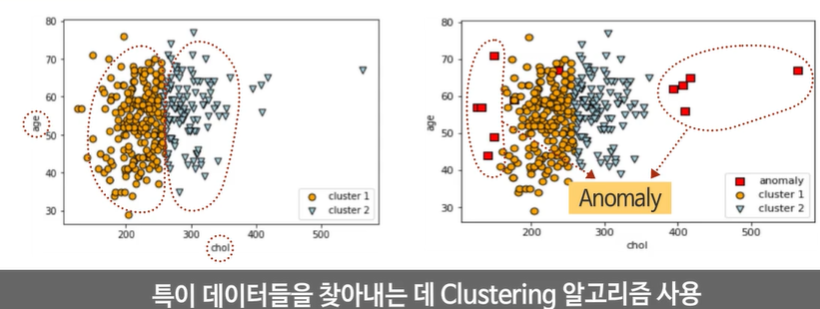
의료 진단에서 지금까지 알지 못했떤 새로운 종류의 증세/ 병의 종류, 정상 범위에서 벗어나는 환자를 찾는 데 사용이 될 수 있다.

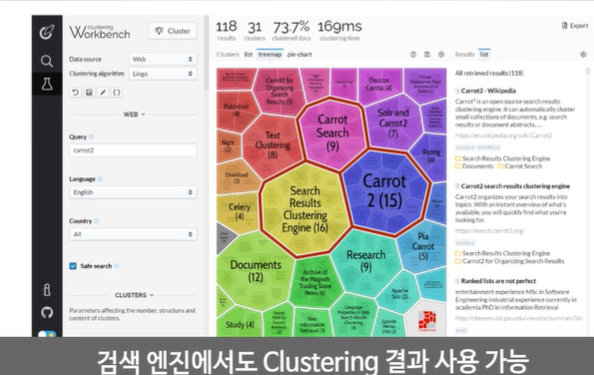

데이터 특성에 기반에서 찾아내고 라벨링해서 찾아낼 수 있다.


2차시 - K-means 알고리즘의 원리


상당히 널리 사용되는 알고리즘이다.
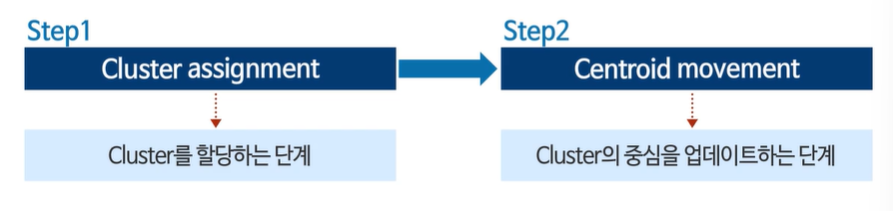
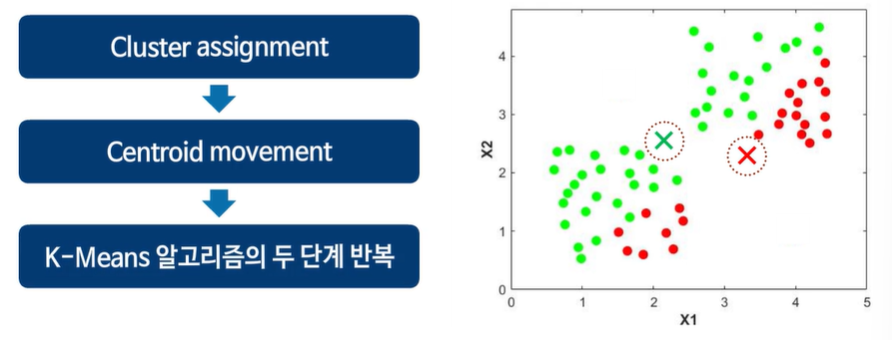
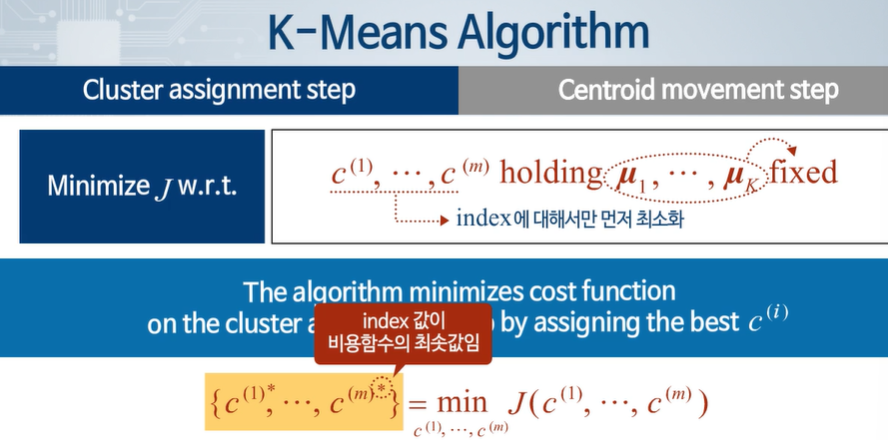
2 단계로 운영된다.

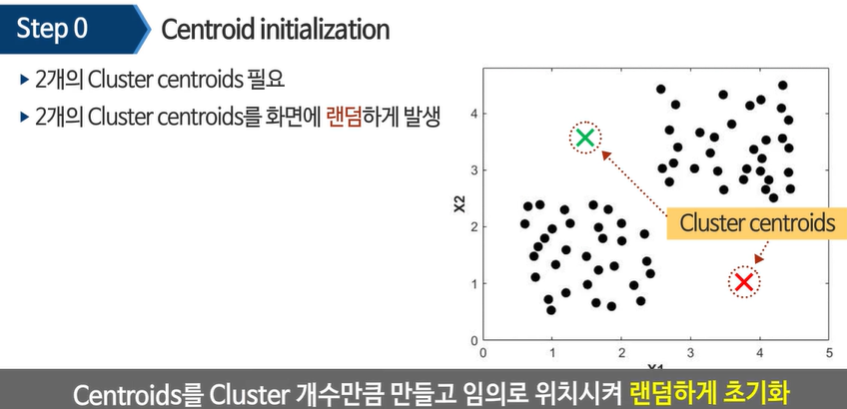
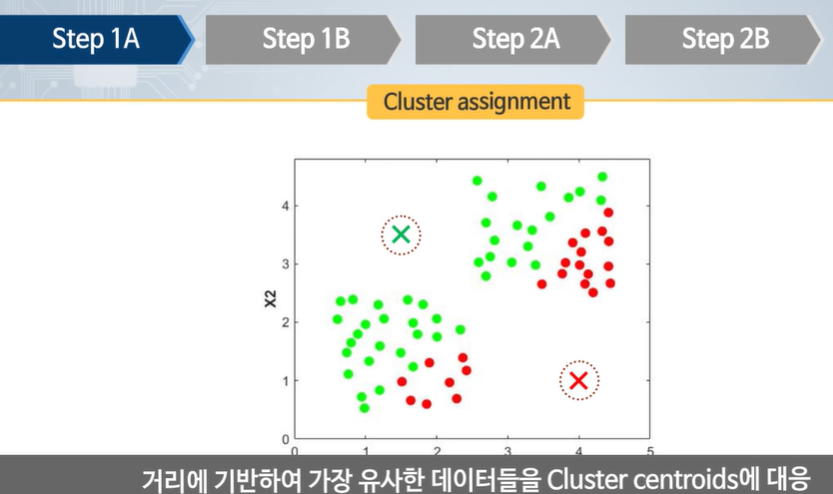
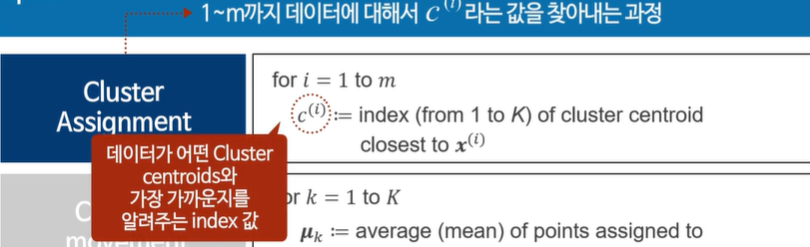
가장 가까운(유사한) 데이터들을 표시한다.
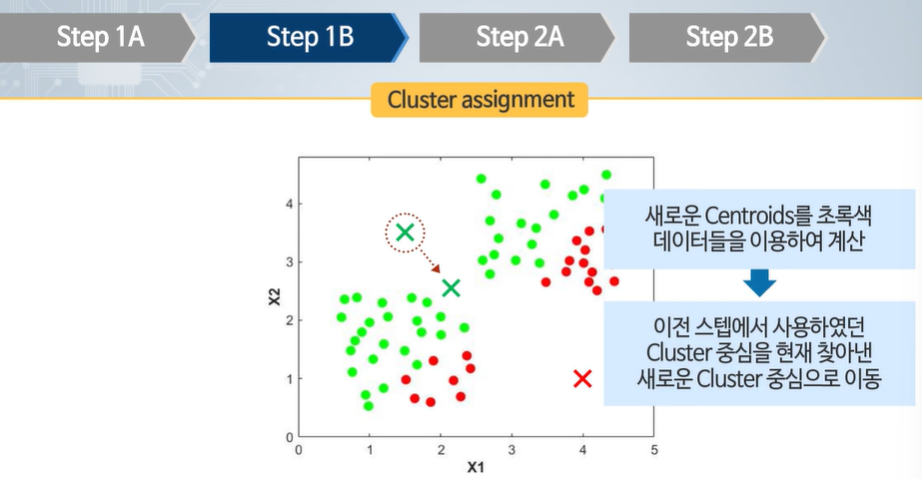
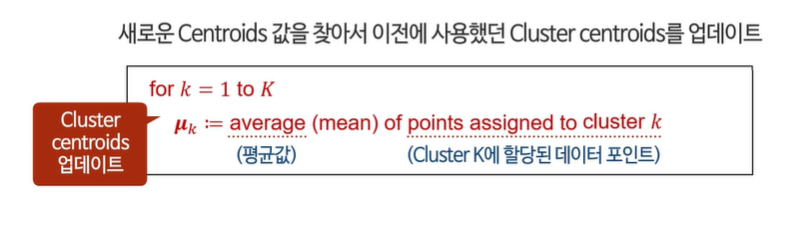
새로운 클러스터 중심을 계산한다.
지속적으로 반복한다.
유사한 데이터 표시 -> 센터로이드 옮기기 -> 다시 유사한 데이터들 표시 -> 센터로이드 옮기기





어떤 클러스터가 아무런 포인트도 포함하지 못한다!

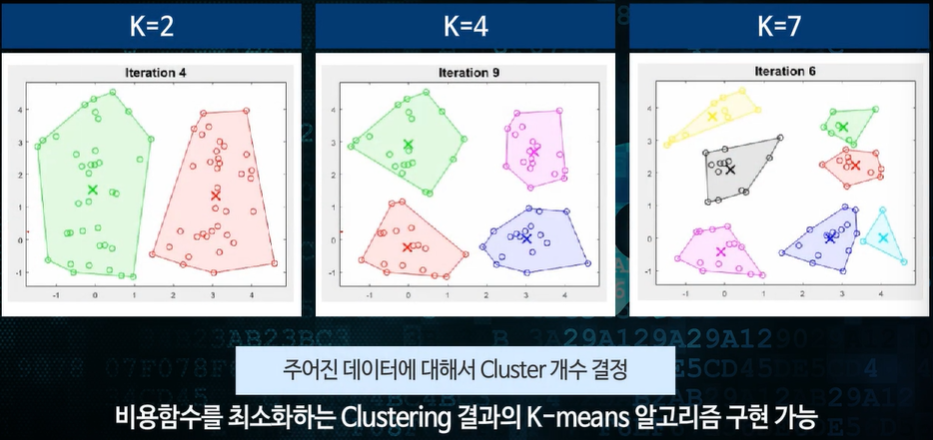
어떤 값이 가장 이상적일까?
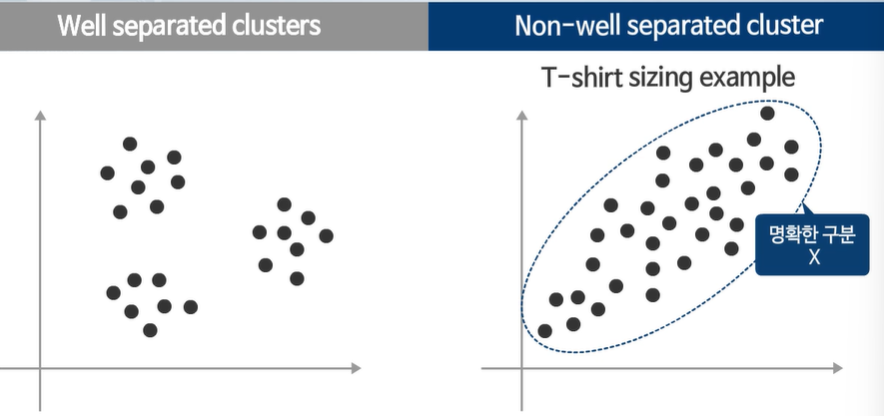
왼쪽은 명확하게 3개로 나누는 것이 좋아보인다.




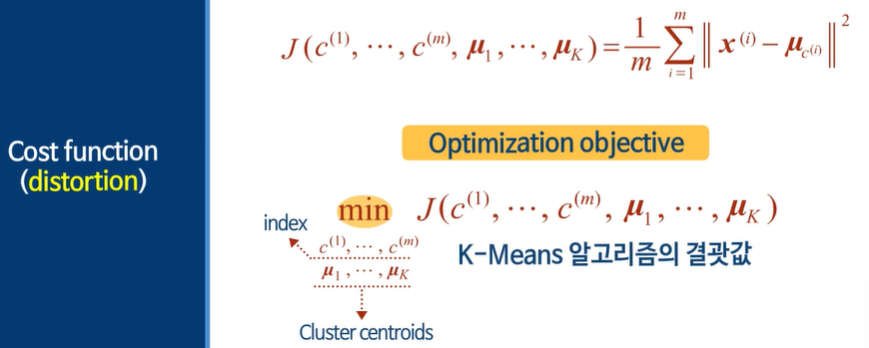
3차시 - K means 알고리즘의 최적화 목적 함수



C - 어떤 클러스터에 포함되어있는지
클러스터 중심 - 데이터 차원 수

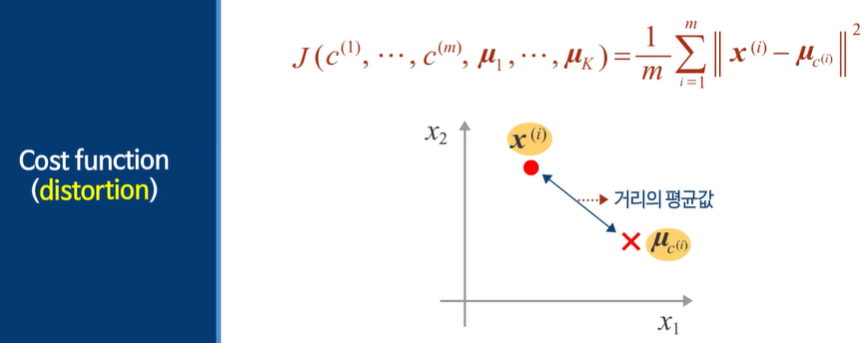
비용함수는 다른 말로 distortion이라고 부른다. 제곱의 평균이다!

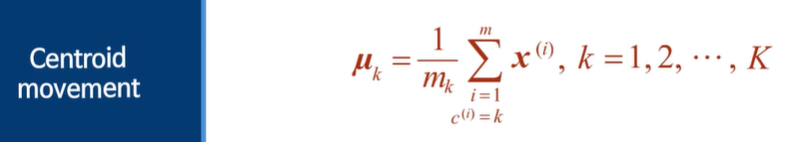



임의의 값이었으나 시각적으로 적절한 클러스터를 형성한다.

4차시 - 랜덤 초기화와 kMeans 알고리즘


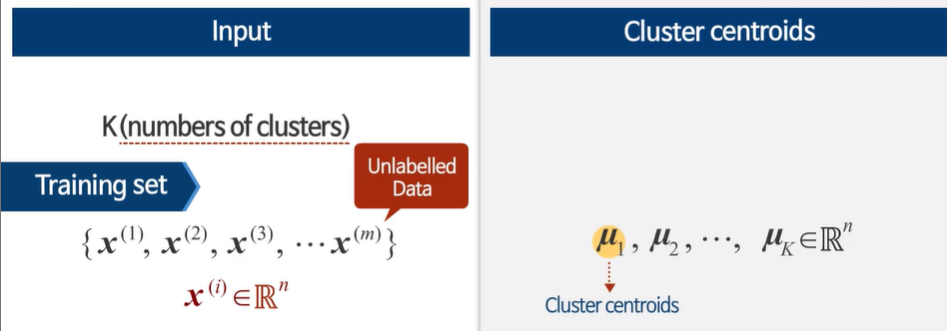
제일 처음 하는 일은 랜덤 하게 센트로이드를 초기화한다.
클러스터의 수는 데이터의 수보다 작아야 한다.
랜덤이기 때문에 초기화가 원하는 대로 될 수 있지만 이상하게 될 수도 있다.


이것도 반복을 계속하면 도달하지 않나?

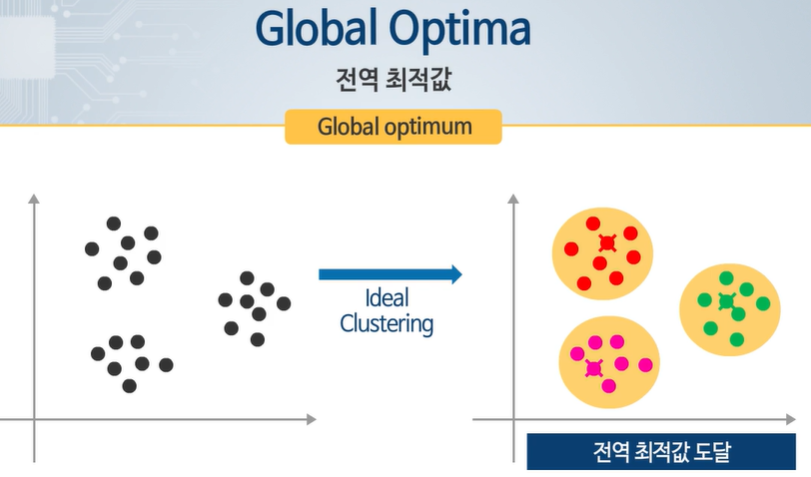
글로벌 옵티멈 - 제일 작은 값!
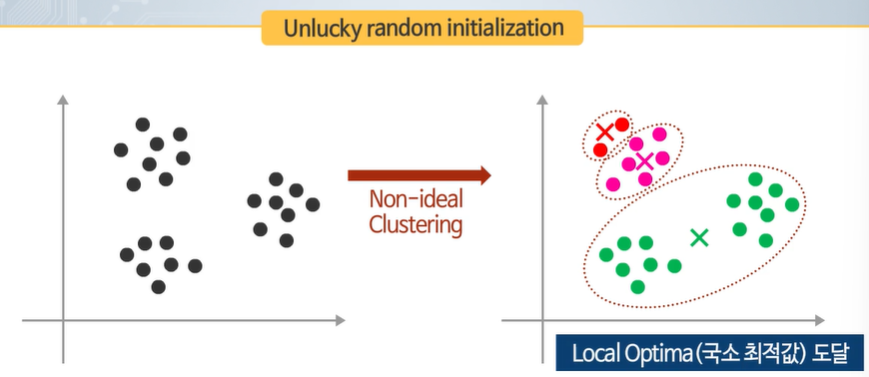
초기화에 따라 결과가 달라질 수 있다!


Local optima를 어떻게 벗어나야 할까?
여러 번 시도해 보는 게 도움이 된다!



클러스터의 개수가 많으면 랜덤 초기화를 반복해도 나은 결과가 안 나올 수 있다.
5차시 - 클러스터 수의 결정

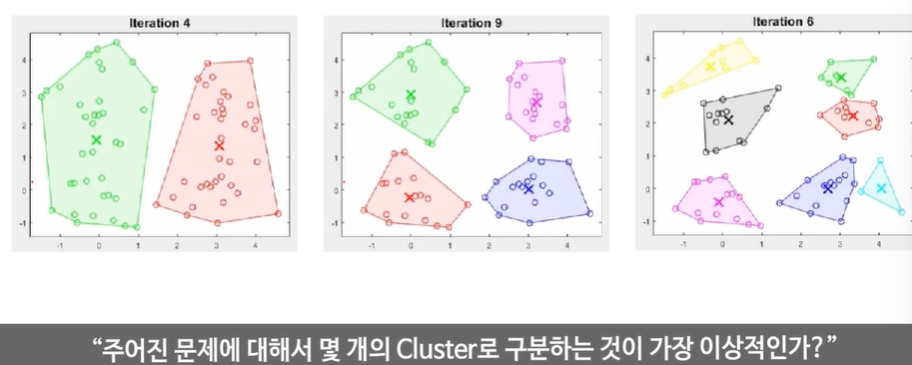
항상 명확한 답은 없다는 것을 알아야 한다!

애매모호성이 존재한다.


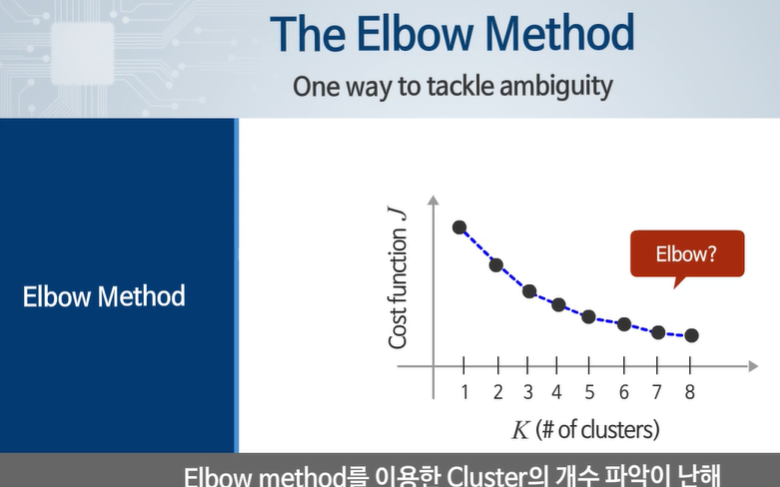
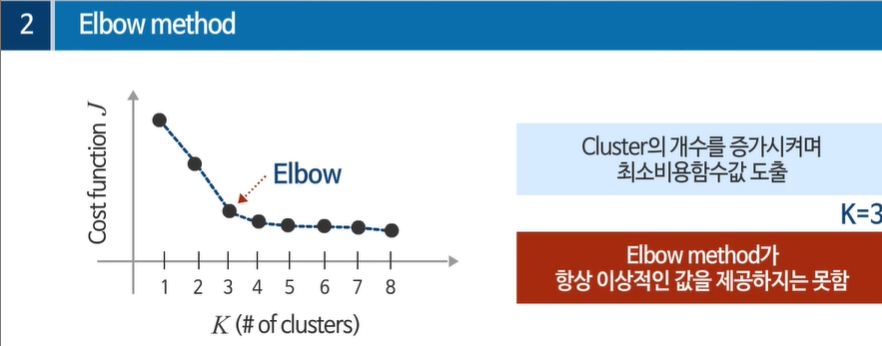
3인경우 까지는 비용함수가 큰 폭으로 줄어드나 그 이후로는 큰 폭으로 줄지 않았다.
엘보우 메서드가 항상 이상적인 것은 아니다.
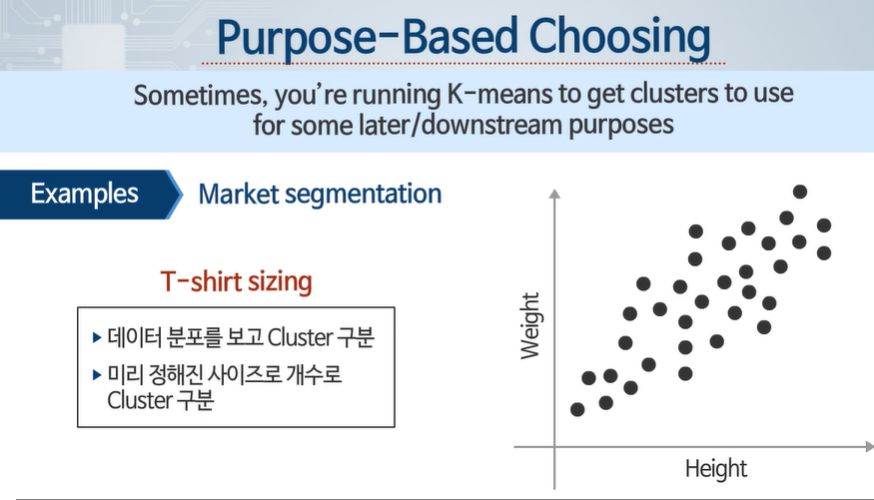
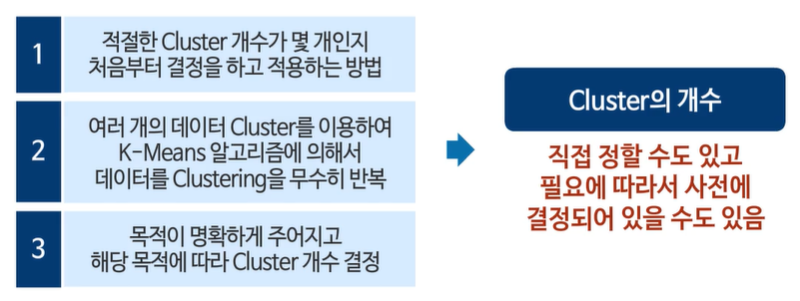
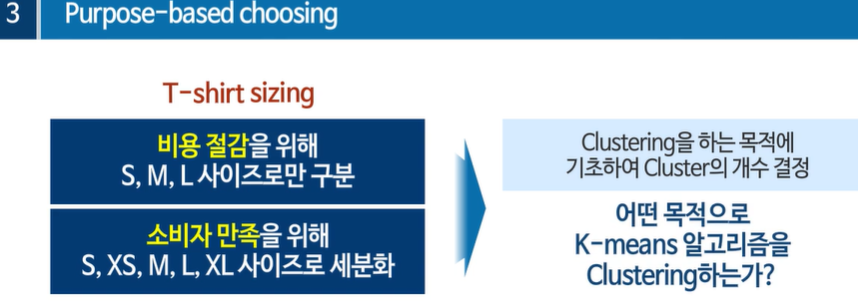
목적에 기초한 클러스터 개수
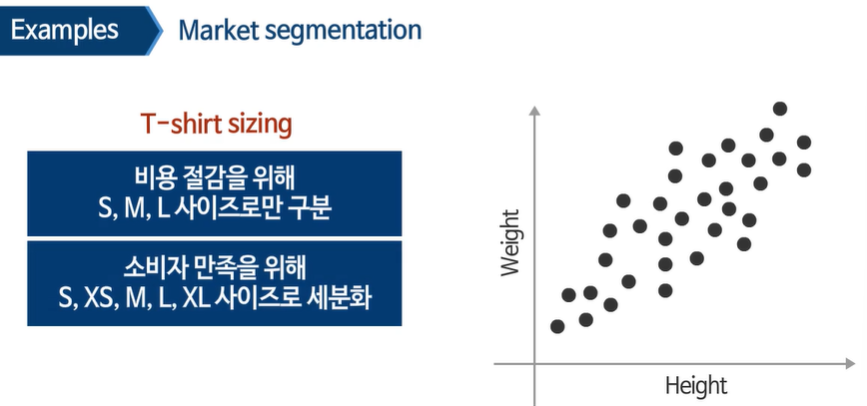


판매 전략에 따라 클러스터 개수를 적절하게 선택할 수 있다.

사람의 시야로 판단

'인공지능 > 공부' 카테고리의 다른 글
| 모두를 위한 머신러닝 과제2 - k means 진행, 계산 (0) | 2024.05.20 |
|---|---|
| 모두를 위한 머신러닝 12주차 퀴즈 (0) | 2024.05.20 |
| 생성형 인공지능 입문 11주차 퀴즈 (0) | 2024.05.18 |
| 생성형 인공지능 11주차 5차시 - 응용 사례 (0) | 2024.05.18 |
| 생성형 인공지능 11주차 4차시 - 분산 생성 모델 성능 비교 (0) | 2024.05.18 |