728x90
728x90
데이터 사이언즈 작업의 흐름, 데이터 수집, 관리, 분석
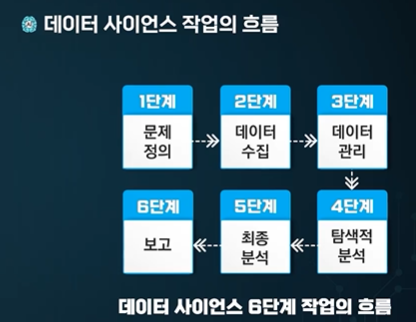
분야마다 다를 수 있지만 이 단계를 일반적으로 따른다.




가장 중요성이 크다!
원하는 목표를 달성하는 문제 정의를 잘 못하면 이상한 결과를 얻을 수 있다.
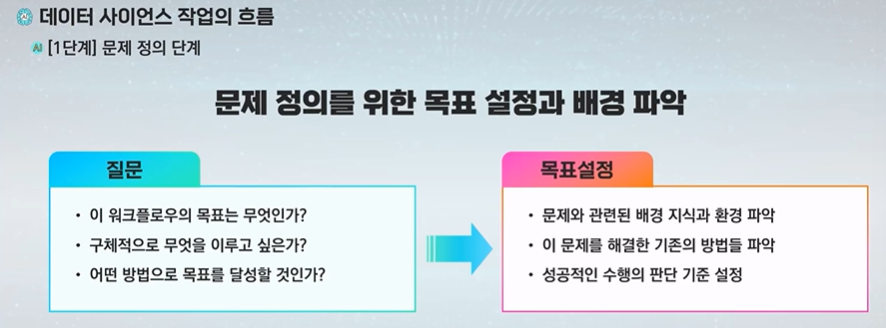

문제 정의의 중요성을 보여준다.

인터뷰, 데이터 베이스 활용 등 다양한 수집 방법이 있다.

질문을 통해 여러 수집 방법을 고안할 수 있다.


저장된 데이터를 활용한다.
인공지능 뿐만이 아니라 전통적인 방식이 효율적일 수 있다.

시각화 - 결과를 보기 쉽게 그래프나 표로 눈으로 보여주는 것
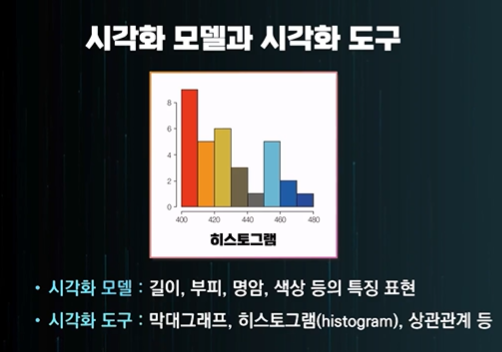
sns나 seaborn이 있었던 것 같네요
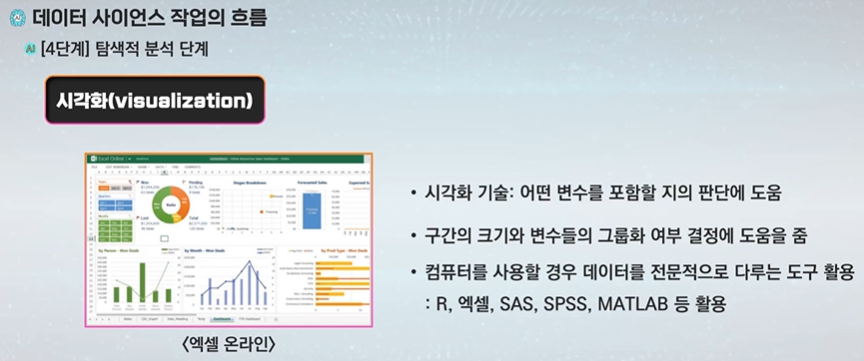
판다스를 활용하기도 한다.

1단계에서 정의했던 문제에 대해 달성했는지 확인하는 단계이다.

데이터 분석 단계를 좀 더 확인해보자!
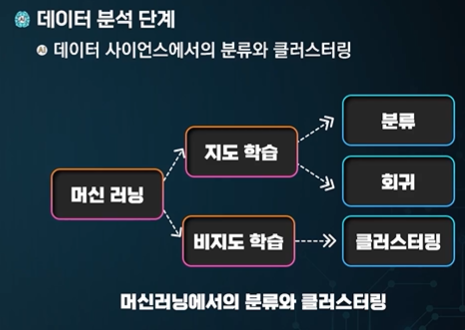
분류와 클러스터링이 지속적으로 사용된다.
라벨이 충분히 잘 되어 있다 -> 분류 - 지도학습
라벨 없이 데이터 자체로 존재한다 -> 클러스터링 - 비지도 학습

비지도 학습 이후에 지도학습이 연계되어 일어날 수 있다.
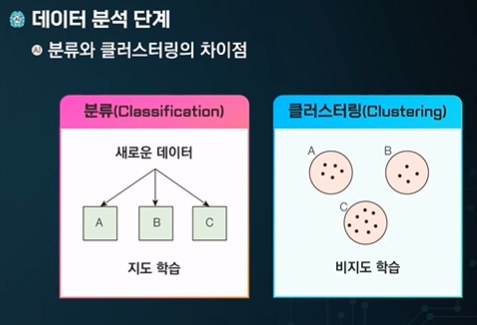
결국 정답을 알아야 분류를 할 수 있다.
클러스터링 된 것에 라벨링을 이 후에 진행할 수 있기 때문에 그 뒤 지도학습이 가능하다.


머신러닝과 딥러닝도 데이터 사이언스에 포함되어 있기 때문
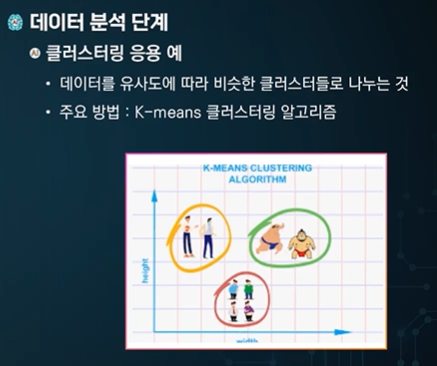
유사한 특징을 그룹으로 묶어준다.

지진 일어난 지역의 특징을 분석해서 다음 지진 일어난 곳을 예측하기도 한다. - 클러스터에 묶이면 유사한 지진이 일어날 수 있다.

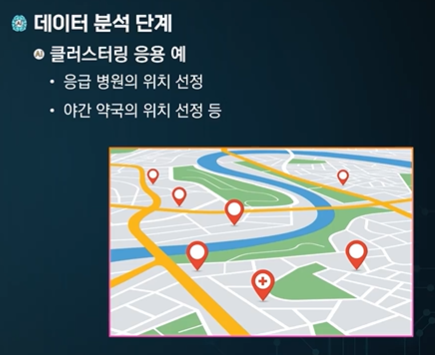
위치에 민감한 것들을 클러스터링을 통해 최적의 위치를 정할 수 있다.
728x90
'인공지능 > 공부' 카테고리의 다른 글
| 머신러닝 9주차 1차시 - 예측 함수 성능 평가(데이터 셋 분류) (1) | 2024.05.01 |
|---|---|
| 인공지능과 빅데이터 9주차 3차시 - 빅데이터와 데이터 마이닝 (0) | 2024.04.29 |
| 인공지능과 빅데이터 9주차 1차시 - 데이터 사이언스 개요, 활용 분야 (0) | 2024.04.29 |
| BahdanauAttention 정리하기 (1) | 2024.04.26 |
| 모두를 위한 머신러닝 중간고사 (0) | 2024.04.25 |