Multi-Head Attention은 Transformer 아키텍처에서 사용되는 핵심 기술 중 하나입니다. 이 메커니즘은 문장이나 문서에서 중요한 정보를 더 잘 포착하기 위해, 단일 Attention 메커니즘을 여러 번 병렬로 실행하는 아이디어를 기반으로 합니다. 각각의 "Head"는 동일한 입력 데이터에 대해 서로 다른 방식으로 Attention을 계산합니다. 이렇게 함으로써, 모델은 다양한 서브스페이스(subspaces)에서 정보를 포착하고, 더 풍부한 문맥 정보를 학습할 수 있게 됩니다.
Multi-Head Attention의 작동 원리
Transformer 모델에서, 입력 데이터는 주로 문장의 각 단어를 나타내는 벡터로 구성됩니다. Multi-Head Attention 메커니즘은 이 입력 데이터를 받아, 다음과 같은 단계로 처리합니다:
- 선형 변환: 입력 벡터는 각 Attention Head에 대해 서로 다른 선형 변환(가중치 행렬을 사용)을 적용받아, 쿼리(Query), 키(Key), 값(Value) 벡터로 변환됩니다. 이 과정은 각 Head가 입력 데이터를 서로 다른 방식으로 "해석"할 수 있게 해줍니다.
- Scaled Dot-Product Attention: 각 Head는 변환된 쿼리, 키, 값 벡터를 사용하여 Scaled Dot-Product Attention을 계산합니다. 이 과정은 각 단어가 다른 단어들과 어떤 관계를 가지는지를 결정하고, 중요한 정보에 더 많은 가중치를 부여합니다.
- 결합: 모든 Head에서 계산된 Attention 결과를 연결(concatenate)합니다. 이 연결된 벡터는 다시 한 번 선형 변환을 거쳐 최종 출력 벡터를 생성합니다.
Multi-Head Attention의 이점
- 다양한 관점에서의 정보 포착: 각 Head가 입력 데이터를 다른 관점에서 해석할 수 있기 때문에, 모델은 더 넓은 범위의 문맥적 관계를 포착할 수 있습니다.
- 풍부한 문맥 정보 학습: 서로 다른 서브스페이스에서의 문맥 정보를 동시에 학습함으로써, 모델은 단어 사이의 복잡한 의존성을 더 잘 이해할 수 있습니다.
- 유연성 및 효율성: Multi-Head Attention은 모델이 다양한 유형의 정보(예: 단어의 의미적 관계, 문법적 구조 등)를 병렬로 처리할 수 있게 해주며, 이는 전반적인 모델의 성능 향상에 기여합니다.
Multi-Head Attention은 Transformer 모델의 핵심 구성 요소로, 기계 번역, 텍스트 요약, 질의 응답 시스템 등 다양한 자연어 처리(NLP) 작업에서 뛰어난 성능을 발휘합니다.
영상 처리 분야에서의 Multi-Head Attention은 Transformer 아키텍처를 영상 데이터에 적용한 것입니다. 자연어 처리(NLP)에서 큰 성공을 거둔 Transformer와 Multi-Head Attention 메커니즘은 최근 컴퓨터 비전 분야로 확장되었습니다. 이러한 접근 방식은 이미지나 비디오와 같은 영상 데이터에서 중요한 특징을 포착하고, 여러 레벨의 문맥 정보를 동시에 처리할 수 있게 해 줍니다.
영상에서의 Multi-Head Attention의 적용
- 영상을 패치로 분할: Transformer 모델을 영상에 적용하기 위해, 먼저 영상을 여러 개의 작은 패치(patch)로 분할합니다. 각 패치는 Transformer의 입력으로 사용될 수 있는 고정된 크기의 벡터로 변환됩니다.
- Positional Encoding: 영상의 공간적 구조를 유지하기 위해, 각 패치에 위치 정보를 추가하는 Positional Encoding이 사용됩니다. 이는 모델이 패치들의 상대적인 위치 관계를 이해하는 데 도움을 줍니다.
- Multi-Head Attention 적용: 변환된 패치와 위치 정보를 바탕으로, Multi-Head Attention 메커니즘이 적용됩니다. 이 과정에서 모델은 영상의 여러 부분 사이의 관계를 학습하며, 중요한 특징에 집중하게 됩니다.
- 여러 레이어를 통한 정보 통합: 대개 여러 개의 Attention 레이어와 Feed-Forward 네트워크를 거치면서, 영상의 고수준 특징이 점차적으로 추출됩니다. 이러한 과정을 통해, 모델은 영상의 복잡한 패턴과 구조를 이해할 수 있게 됩니다.
컴퓨터 비전에서의 활용 예
- 영상 분류(Image Classification): 모델이 영상의 전체적인 내용을 파악하여, 해당 영상이 어떤 카테고리에 속하는지 분류합니다.
- 객체 탐지(Object Detection): 영상 내의 여러 객체를 식별하고, 각 객체의 위치를 정확히 예측합니다.
- 세그멘테이션(Segmentation): 영상을 구성하는 각 픽셀이 어떤 객체에 속하는지 분류하여, 영상 내 객체의 경계를 세밀하게 구분합니다.
결론
컴퓨터 비전 분야에서 Multi-Head Attention의 적용은 Transformer 아키텍처의 유연성과 강력한 문맥 정보 처리 능력을 활용할 수 있게 합니다. 이를 통해, 모델은 영상 데이터의 복잡한 특징과 패턴을 더 잘 이해하고, 다양한 비전 관련 작업에서 뛰어난 성능을 발휘할 수 있게 됩니다.


attention = 여러개를 하나로 모은다.
멀티헤드 어텐션 = 어텐션을 전체적으로 모은다는 의미
완전히 분리된 상태에서 다른 파트의 attention을 concatenation한다. 머리를 다 모아서 붙인다고 생각하면 된다.
이미지에서 멀티 헤드 어텐션이 오히려 필요 없다?!
이미지는 한개다! -> 어텐션이 왜 필요하지?
이미지 처리에서 Multi-Head Attention이 필요 없다고 여겨질 수 있는 주장은 주로 이미지가 단일 데이터 덩어리로 취급될 수 있고, 전통적인 컨볼루션 신경망(CNN) 같은 기술만으로도 충분히 효과적으로 처리할 수 있다는 관점에서 비롯될 수 있습니다. 그러나, Multi-Head Attention을 활용하면 이미지 처리에서도 많은 이점을 얻을 수 있습니다. 여기 몇 가지 주요 포인트를 살펴보겠습니다:
1. 이미지 내 복잡한 관계 포착
이미지는 비록 하나의 데이터 덩어리로 볼 수 있지만, 그 내부에는 복잡한 구조와 패턴, 객체 간의 다양한 관계가 존재합니다. Multi-Head Attention 메커니즘을 사용하면, 이러한 복잡한 관계를 더 잘 포착하고 해석할 수 있습니다. 각 "Head"는 이미지의 다른 부분에 주목함으로써, 이미지 내 다양한 컨텍스트를 폭넓게 이해할 수 있게 됩니다.
2. 장거리 의존성 학습
전통적인 CNN은 지역적인 특징을 잘 포착할 수 있지만, 때로는 이미지의 먼 부분 사이에 중요한 의존성이 존재할 때 이를 적절히 학습하는 데 한계가 있습니다. Multi-Head Attention은 이러한 장거리 의존성을 자연스럽게 학습할 수 있으며, 이는 객체 탐지나 세그멘테이션 같은 작업에서 특히 중요할 수 있습니다.
3. 다양한 스케일의 특징 학습
이미지는 다양한 스케일에서의 특징을 포함하고 있으며, Multi-Head Attention은 이러한 다양한 스케일의 특징을 동시에 처리할 수 있습니다. 서로 다른 "Head"가 서로 다른 크기의 패턴이나 객체에 주목할 수 있기 때문입니다.
4. 유연성과 확장성
Transformer 기반 아키텍처는 매우 유연하며, 다양한 크기와 형태의 이미지 데이터에 적용할 수 있습니다. 또한, 추가적인 컨텍스트 정보나 다중 모달 데이터를 통합하기에도 용이합니다.
결론
비록 이미지가 단일한 데이터 덩어리로 볼 수 있으나, 내부의 복잡한 구조와 패턴을 이해하고, 이미지 전체의 컨텍스트를 파악하기 위해서는 Multi-Head Attention 같은 메커니즘이 매우 유용할 수 있습니다. 이러한 접근 방식은 이미지 처리를 넘어서, 컴퓨터 비전의 다양한 응용 분야에서 혁신적인 성과를 이끌어낼 잠재력을 가지고 있습니다.
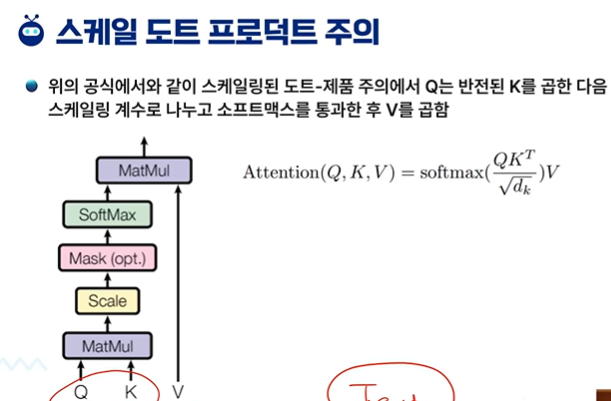


소프트 - 그라데이션식으로 연하게 한다. 가중치
하드 - 빡 집중해서 보기. 0,1





'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 5주차 - 퀴즈 (0) | 2024.04.02 |
|---|---|
| 생성형 인공지능 5주차 5차시 Transformer - 영상 트랜스포머 응용1 (0) | 2024.04.02 |
| 생성형 인공지능 5주차 3차시 Transformer - U-net 형 model (0) | 2024.04.02 |
| 생성형 인공지능 5주차 2차시 transformer - ViT 모델 (0) | 2024.04.02 |
| 생성형 인공지능 5주차 1차시 transformer - 영상 패치 임베딩 (0) | 2024.04.02 |