K-NN - 최근접 이웃인가?

다수결의 원칙으로 판단하므로 k값은 보통 홀수이다.
경계선에서의 입력은 적절한 k값이 아니면 이상한 답을 출력한다.
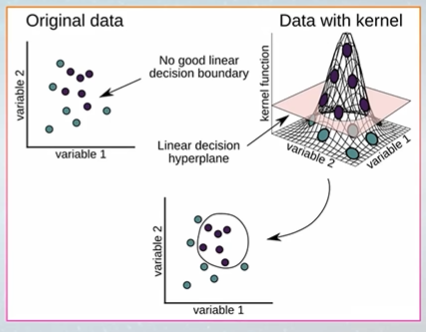
SVM - Support Vector Machine
이건 안써봤네요
아니네요 많이 써봤네요 ㅎㅎ...
여백이 최대화 하도록 선을 만든다.
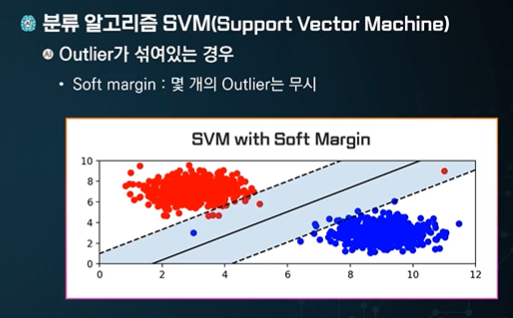
Outlier - 이상치 - 원하지 않는 이상한 값들
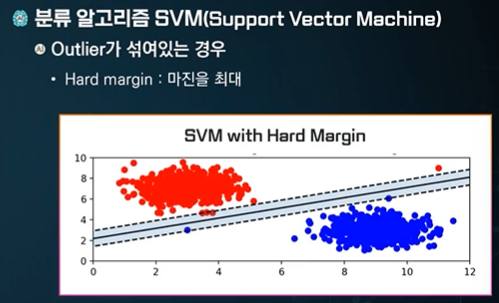
마진을 최대화 한다.
outlier - 저기 뚝 떨어진 점, 데이터가 잘 못된 경우도 있다.
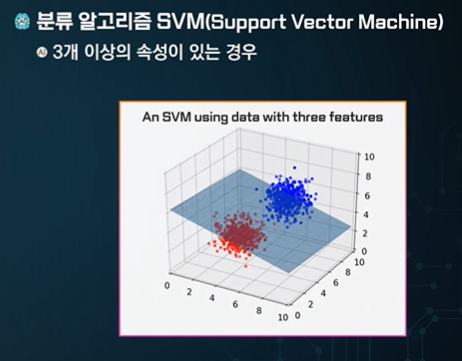
3개이상의 feature가 있으면 3차원으로 표현하면 된다.
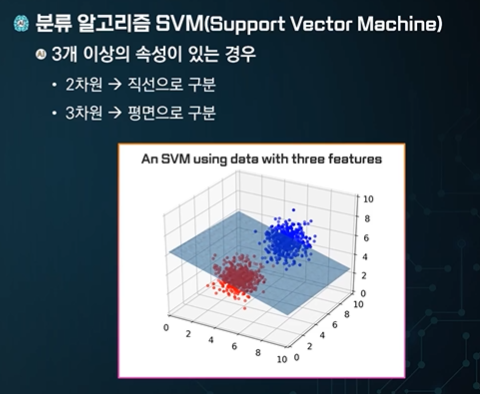

직선으로 분류가 힘든 경우

결정트리 Decision Tree


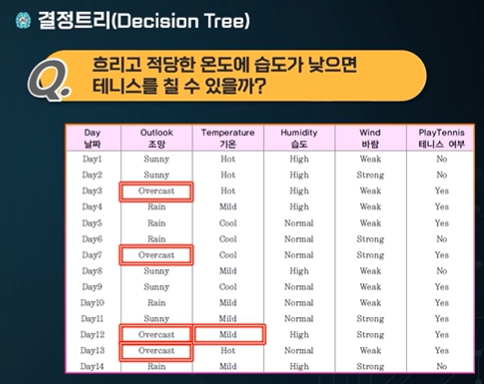
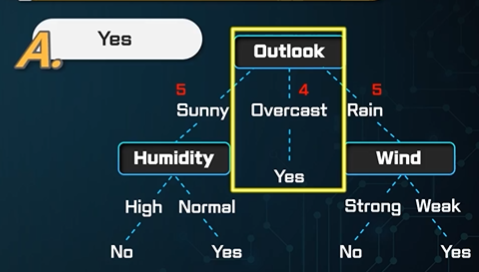
알려주지 않은 정보를 알아서 판단한다.
노드 분할한 이유가 중요하다!


구체적인, 수치적인 분류 기준을 다르지 않지만 간단히만 본다.

그러니까 가장 큰 분류부터 분할하겠네유
앙상블 분류기 - Ensemble classifier
정형화된 데이터에서 성능이 좋다.

한 명의 전문가가 전문성은 높겠지만 개인 의견이 들어갔을 수 있다.
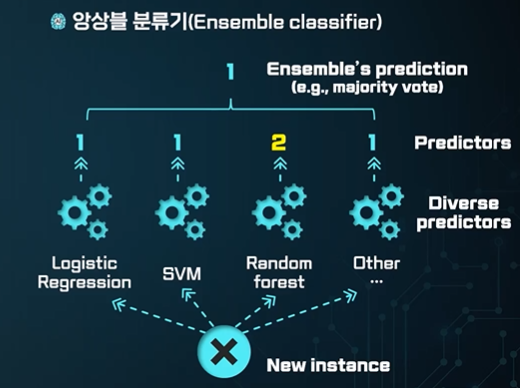
변수가 많이 작용하더라도 더 좋은 성능을 낸다.

배깅 - Bootstrap aggregating

여러개 병렬적인 결과를 내서 튜표를 한다는 것이다.
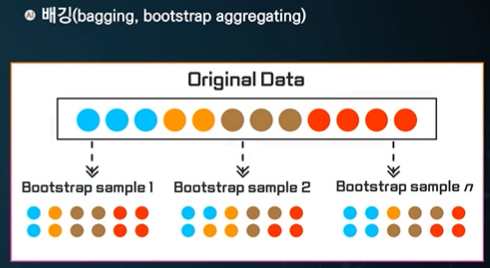
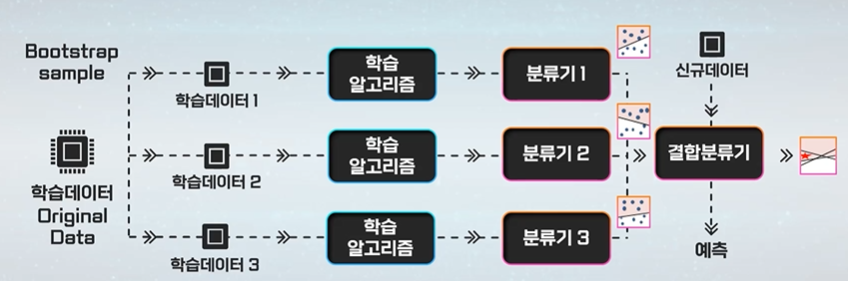
학습데이터 n개를 뽑는다 -> 학습 데이터의 특징이 다 다르다. -> 각각의 분류기를 돌려 투표한다.
랜덤 포레스트
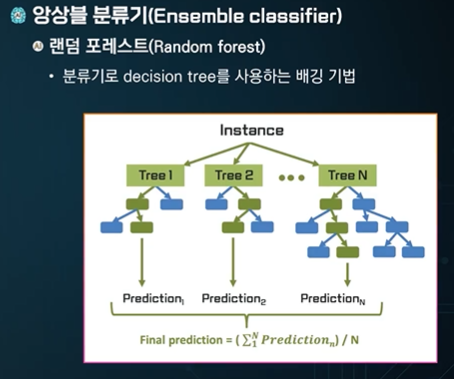
여러개의 트리를 만들어 병렬적으로 처리하기!
부스팅 - boosting - 병렬이 아니라 순차적으로 만들어간다.

ML 분류 알고리즘 -> 정형데이터에 강하다.

비정형데이터 - 사진, 동영상, 음성신호, 텍스트
딥러닝에서 많이 푼다.
'인공지능 > 공부' 카테고리의 다른 글
| 머신러닝 4주차 2차시 - 분류 경계선 decision boundary (0) | 2024.03.25 |
|---|---|
| 머신러닝 4주차 1차시 - 이진분류 Binary classification (0) | 2024.03.25 |
| 인공지능과 빅데이터 4주차 2차시 - 지도학습(분류, 회귀) supervised Learning(classification, regression) (0) | 2024.03.25 |
| 인공지능과 빅데이터 4주차 1차시 - 머신러닝 개요 (1) | 2024.03.25 |
| 강화학습 과제 1.1 (0) | 2024.03.25 |