2024.03.20 - [인공지능/공부] - 자연어 처리 - 과제 1.1
자연어 처리 - 과제 1.1
요즘 릴스에 많이 나오는 max와 hamilton으로 했습니다... import numpy as np from numpy import dot from numpy.linalg import norm import pandas as pd # Cosine Simiarity def cos_sim(A, B): return dot(A, B)/(norm(A)*norm(B)) from sklearn.feature
yoonschallenge.tistory.com
과제 설명은 이전에 있었으니 간단하게 넘어가겠습니다.

import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import re
TEXT = ['Verstappen is the son of former Formula One driver Jos Verstappen, and former go-kart racer Sophie Kumpen. He had a successful run in karting and single-seater categories – including FIA European Formula 3 – breaking several records.',
'At the 2015 Australian Grand Prix, when he was aged 17 years, 166 days, he became the youngest driver to compete in Formula One. After spending the 2015 season with Scuderia Toro Rosso, Verstappen started his 2016 campaign with the Italian team before being promoted to parent team Red Bull Racing after four races as a replacement for Daniil Kvyat. At the age of 18, he won the 2016 Spanish Grand Prix on his debut for Red Bull Racing, becoming the youngest-ever driver and the first Dutch driver to win a Formula One Grand Prix.',
'After winning ten Grands Prix during the 2021 season, Verstappen became Formula One World Drivers Champion for the first time, being the first Dutch driver and the 34th driver to do so.[6] He won the next two consecutive Formula One championships in 2022 and 2023. As of the 2024 Saudi Arabian Grand Prix, Verstappen has had 56 victories, 34 pole positions and 31 fastest laps. In addition to being the youngest Grand Prix winner, he holds several Formula One records, including the most wins in a season, the highest percentage of wins in a season, and the most consecutive wins. Verstappen is set to remain at Red Bull until at least the end of the 2028 season after signing a contract extension.',
'His family has a long association with motor sports: his father is a Dutch former Formula One driver, his Belgian mother competed in karting,[12][13] and his first cousin once removed, Anthony Kumpen, competed in endurance racing and is a two-time NASCAR Whelen Euro Series champion currently serving as the team manager for PK Carsport in Euro Series.[12] Although Verstappen has a Belgian mother, was born in Belgium and resided in Bree, Belgium, he decided to compete with a Dutch racing licence. He stated he "feels more Dutch", having spent more time with his father than with his mother during his upbringing, and was always surrounded by Dutch people while growing up in Maaseik, a Belgian town at the Dutch border.[13] Verstappen said in 2015: I actually only lived in Belgium to sleep, but during the day I went to the Netherlands and had my friends there too. I was raised as a Dutch person and thats how I feel.[14] In 2022, however, Verstappen stated that he appreciates both sides and is half-half at the end of the day',
'He competed in Formula One for more than a season before obtaining a road driving licence on his 18th birthday.[16] Verstappen moved to Monaco the day after, in October 2015, and has lived there since and has said it was not for tax reasons.[17] In November 2020, Verstappen bought a Dassault Falcon 900EX aircraft from Virgin Galactic. The aircraft is registered PH-DTF and operated by Exxaero',
'Sir Lewis Carl Davidson Hamilton MBE HonFREng (born 7 January 1985) is a British racing driver competing in Formula One, driving for Mercedes, and has also driven for McLaren. Hamilton has won a joint-record seven Formula One World Drivers Championship titles (tied with Michael Schumacher), and holds the records for most number of wins (103), pole positions (104), and podium finishes (197), among other records.',
'Born and raised in Stevenage, Hertfordshire, he began karting in 1993 at the age of eight and achieved success in local, national and international championships',
'Hamilton joined the inaugural McLaren-Mercedes Young Driver Programme in 1998, and progressed to win the 2003 British Formula Renault Championship, 2005 Formula 3 Euro Series and the 2006 GP2 Series. This led to a Formula One drive with McLaren-Mercedes from 2007 to 2012, making him the first black driver to race in the series. In his debut season, Hamilton set numerous records as he finished runner-up to Kimi Räikkönen by one point. In 2008, he won his maiden title in dramatic fashion—making a crucial overtake on the last lap of the 2008 Brazilian Grand Prix, the last race of the season—to become the then-youngest ever Formula One World Champion. Following six seasons with McLaren, Hamilton signed with Mercedes in 2013',
'Changes to the regulations for 2014 mandating the use of turbo-hybrid engines saw the start of a highly successful period for Hamilton, during which he won six further drivers titles. Consecutive titles came in 2014 and 2015 during the intense Hamilton–Rosberg rivalry. Following teammate Rosbergs title win and retirement in 2016, Ferraris Sebastian Vettel became Hamiltons closest rival in two championship battles, in which he twice overturned mid-season point deficits to claim consecutive titles again in 2017 and 2018. His third and fourth consecutive titles followed in 2019 and 2020 to equal Schumachers record of seven drivers titles. After surpassing 100 race wins and pole positions and finishing runner-up to Max Verstappen in 2021, Hamilton has not managed to win races during Formula Ones current ground effect era with Mercedes. Hamilton is set to join Ferrari for the 2025 season',
'Hamilton has been credited with furthering Formula Ones global following by appealing to a broader audience outside the sport, in part due to his high-profile lifestyle, environmental and social activism, and exploits in music and fashion. He has also become a prominent advocate in support of activism to combat racism and push for increased diversity in motorsport. Hamilton was listed in the 2020 issue of Time as one of the 100 most influential people globally (Time 100), and was knighted (Knight Bachelor) in the 2021 New Year Honours'
]
## Your code here
def my_preprocessing(text, customized_stopwords=None):
# 1. 불필요한 symbols과 marks 제거하기
filtered_content = re.sub(r'[^\s\d\w]','',text)
# 2. Case conversion; 대문자를 소문자로 바꾸기
filtered_content = filtered_content.lower()
return filtered_content
docs_nouns = [my_preprocessing(doc, stopwords) for doc in TEXT] #학습에 필요없는 문장이 너무 많았습니다...
# CountVectorizer 이용하기
tf_vectorizer = CountVectorizer(min_df=4, max_df=0.9, ngram_range=(1,2)) # 문장이 크고 길다-> 최소 등장 횟수를 늘린다.
tf_features = tf_vectorizer.fit_transform(docs_nouns) # 주변 단어까지 봐서 맥락의 확인 더 크게!
# 벡터화 된 문서 확인
features = np.array(tf_features.todense())
print(' 0~ 4: max 5 ~ 9 : hamilton')
# Cosine 유사도 계산
for i in range (0,9):
print (f'문서 {i}와 문서{i+1}의 유사도',cos_sim(features[i], features[i+1]))
for i in range (0,9): #
print (f'문서 {0}와 문서{i+1}의 유사도',cos_sim(features[0], features[i+1]))코드의 설명 대부분은 주석으로 붙여놨습니다
tf유사도인데 역시 결과를 보면 뭔가 많이 부족한 것을 알 수 있습니다.

왜 이전의 언어 모델들이 일반인에게 사용이 안되었는지 알 수 있을 정도로 납득 안되는 유사도...
이번엔 tf-idf로 합니다.
tfidf_vectorizer = TfidfVectorizer(min_df=4, max_df=0.9, ngram_range=(1,2))
tfidf_features = tfidf_vectorizer.fit_transform(docs_nouns)
tfidf_features = np.array(tfidf_features.todense())
print(' 0~ 4: max 5 ~ 9 : hamilton')
# Cosine 유사도 계산
for i in range (0,9):
print (f'문서 {i}와 문서{i+1}의 유사도',cos_sim(tfidf_features[i], tfidf_features[i+1]))
for i in range (0,9): #
print (f'문서 {0}와 문서{i+1}의 유사도',cos_sim(tfidf_features[0], tfidf_features[i+1]))tf-idf가 tf보단 많은 정보를 가지고 있다곤 하지만 그래도... 별로...

max와의 유사도가 그래도 좀 더 높네요 ㅎㅎ...

from sklearn.feature_extraction.text import TfidfVectorizer # tf-idf based DTM
tfidf_vectorizer = TfidfVectorizer(min_df=2, max_df=0.9, ngram_range=(1,2)) # 최소 등장 횟수를 너무 늘리니까 남는 단어가 없어서 최소한 2...
tfidf_features = tfidf_vectorizer.fit_transform(documents_filtered)
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
tfidf_features = np.array(tfidf_features.todense())
print('0:apple1 \n1:kevin \n2:serena \n3:apple2 \n')
# Cosine 유사도 계산
for i in range (0,3):
print (f'문서 {i}와 문서{i+1}의 유사도',cos_sim(tfidf_features[i], tfidf_features[i+1]))
for i in range (0,3): #
print (f'문서 {0}와 문서{i+1}의 유사도',cos_sim(tfidf_features[0], tfidf_features[i+1]))그래도 문서와 문서간의 유사도를 비교하니까 apple끼리의 유사도는 확실하게 높게 나왔습니다.
저 두 사람은 운동선수라고 하던데 apple과는 거의 없고 운동 선수끼리는 조금이라도 나오네요
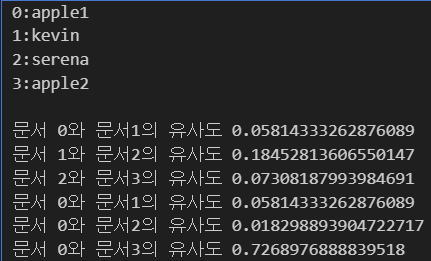

이건 저장한 데이터 상에서 보이지 않네요 ㅎㅎ...

import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
plt.rc('font', family='NanumBarunGothic')
def change_matplotlib_font(font_download_url):
FONT_PATH = 'MY_FONT'
font_download_cmd = f"wget {font_download_url} -O {FONT_PATH}.zip"
unzip_cmd = f"unzip -o {FONT_PATH}.zip -d {FONT_PATH}"
os.system(font_download_cmd)
os.system(unzip_cmd)
font_files = fm.findSystemFonts(fontpaths=FONT_PATH)
for font_file in font_files:
fm.fontManager.addfont(font_file)
font_name = fm.FontProperties(fname=font_files[0]).get_name()
matplotlib.rc('font', family=font_name)
print("font family: ", plt.rcParams['font.family'])
font_download_url = "https://fonts.google.com/download?family=Noto%20Sans%20KR"
change_matplotlib_font(font_download_url)이건 인터넷 뒤져서 겨우 찾았네요
kaggle에서 한글 사용하기!
## your code here
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import numpy as np
# 유사 단어 목록을 얻고, 해당 단어들의 벡터를 배열로 준비
similar_words = ['치킨', '음악', '양주', '소주', '열정'] # 단어 목록 만들기
all_similar_words = []
word_categories = []
for idx, word in enumerate(similar_words):
similar = [item[0] for item in model_sg_n10.wv.most_similar(word, topn=10)]# 비슷한 위치의 단어 10개 뽑기
all_similar_words.extend(similar)# 단어 추가해서 저장하기
word_categories.extend([idx] * len(similar)) # 같은 종류의 단어들을 같은 카테고리 번호로 분류
# 유사 단어들의 벡터 추출
word_vectors = np.array([model_sg_n10.wv[word] for word in all_similar_words]) # 추출하여 저장
# t-SNE 적용
tsne = TSNE(n_components=2, random_state=42)
X_reduced = tsne.fit_transform(word_vectors) # 2차원 벡터 저장하기
# 시각화
plt.figure(figsize=(10, 10))
colors = ['red', 'green', 'blue', 'purple', 'orange'] # 각 종류별 색상 지정
for idx, color in enumerate(colors):
indices = [i for i, x in enumerate(word_categories) if x == idx]
plt.scatter(X_reduced[indices, 0], X_reduced[indices, 1], c=color, label=similar_words[idx])
# 각 점 위에 단어 표시
for i in indices:
plt.text(X_reduced[i, 0], X_reduced[i, 1], all_similar_words[i], fontsize=9)
plt.legend()
plt.show()이미 학습된 word2vec을 이용하여 비슷한 유사도의 단어 10개를 뽑고, 시각화 시키기!
코드 구성은 살짝 복잡하니까 잘 보면서 이해해봐야 합니다 ㅎㅎ....

잘 나왔습니다.

# your code here
kiwi = Kiwi()
def preprocess(content):
stopwords = ['아니','그','저','하다','에서','은''는','이','가','에게','부터','저'] # 불용어 리스트
content = [w for w in content.split(' ') if w not in stopwords] # 불용어 제거
content = ' '.join(content) # 리스트를 str로
if len(content.strip()) > 3:
filtered_content = re.sub(r'[^\s\w\d]',' ', content) #필요없는 것 지우기
kiwi_tokens = kiwi.tokenize(filtered_content)# 토큰화
results = [token.form for token in kiwi_tokens]# 한글이 적혀있는 from만 저장
return results
reviews = [doc[1].strip() for doc in docs][:600000]
reviews[100] # 문장 전체를 하나의 벡터로 만든다. -> 단어의 백터를 하나로 합쳐서 만든다.
preprocessed_reviews = [preprocess(review) for review in reviews]
print(preprocessed_reviews[100]) # 과거형 했다 -> 하 어 ㅆ
# doc2vec 학습이 가능한 형태로 변형
from gensim.models.doc2vec import TaggedDocument
tagged_docs = [TaggedDocument(doc, tags=[i]) for i, doc in enumerate(preprocessed_reviews) if doc != None]
from gensim.models.doc2vec import Doc2Vec
model = Doc2Vec(tagged_docs, vector_size=120,window=3, min_count=5, epochs=100, dm=1, negative=10,
alpha=0.001,hs=1)
print(model.dv.most_similar(100, topn=10))
results = model.dv.most_similar(100, topn=10)
print("\nOriginal Review:")
print(reviews[100])
for i, result in enumerate(results):
print("\nSimilar Reviews", i+1)
print(result)
review_id = result[0]
print(reviews[review_id])여기선 필요없는 한국어 불용어들을 내가 지정해서 다 지워줬고, 학습을 시키는데 그 비교 문장이 중요합니다...
너무 애매한 비교문장을 고르면 유사도가 높은걸 골라도 기교가 안되더라구여
확실하게 긍정이나 부정문장을 고르면 확실한 결과를 확인 가능합니다.
너무 많아서 몇개만 가져오겠습니다.



'인공지능 > 공부' 카테고리의 다른 글
| 인공지능과 빅데이터 4주차 1차시 - 머신러닝 개요 (1) | 2024.03.25 |
|---|---|
| 강화학습 과제 1.1 (0) | 2024.03.25 |
| 자연어 처리 - 과제 1.1 (0) | 2024.03.20 |
| 생성형 인공지능 퀴즈 - 3주차 (0) | 2024.03.20 |
| 생성형 인공지능 3주차 5차시 - 컨볼루션 신경망의 한계 (0) | 2024.03.20 |