728x90
728x90
목표 - 단어의 출현 빈도가 중요하다는 가설에 기반한 임베딩 구축 방법에 대해 이해하자

주제가 비슷한 문서라면 출현 횟수가 비슷할 것이라는 전제가 깔려있다.




행렬이 너무 크기도 하고, 정보의 양도 적어 효율성이 너무 떨어진다.


중복 원소를 포함한다. 출현 횟수로 표현하는 것이다.

코퍼스 범위에서 문서 범위로 줄인 것이다.



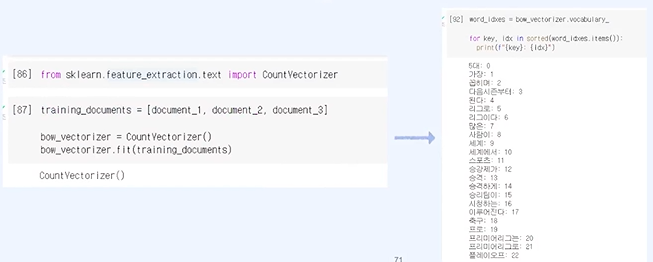



the 같은 의미가 적지만 출현 횟수가 높은 것들이 종요하다고 보일 수 있다.

빈도 이상의 무엇인가를 고려한다.

단어의 중요도와 비례한다.

n이 엄청 커서 log를 씌워 스케일링하는 것이다.
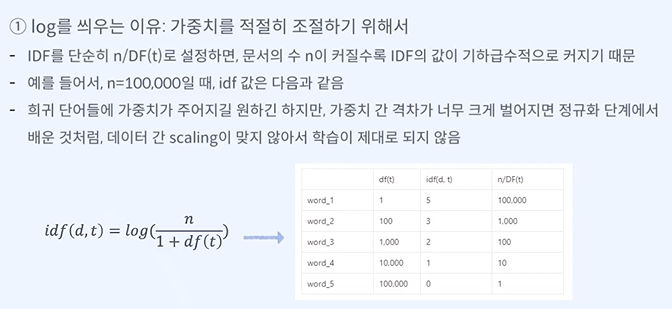
여기서 로그는 10의 로그네요



단어 문서 행렬에 idf값이 들어가는 것이다.

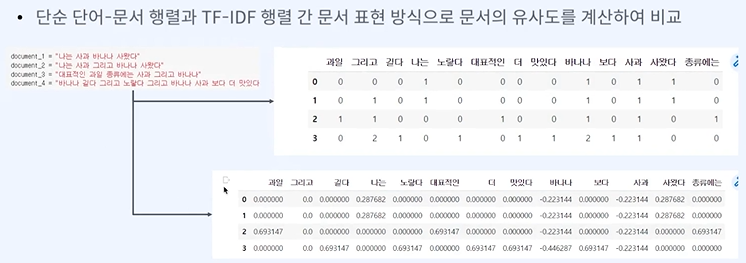

유사도가 좀 더 높긴 하다.


맥락적 유사도를 반영하지 못하는 것이 큰거 같은데. 그리고 행렬도 아직도 너무 크고

728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 임베딩이란 ? - 임베딩 간 유사도 계산 (0) | 2024.03.07 |
|---|---|
| 임베딩이란? - 임베딩 구축 방법 2 - 분포 가설과 언어 모델 (0) | 2024.03.07 |
| 자연어 처리 python - 컴퓨터는 자연어를 어떻게 이해하는가? (0) | 2024.03.06 |
| 컴퓨터는 자연어를 어떻게 이해하는가? - 자연어 특성 (1) | 2024.03.06 |
| 한국어 데이터 전처리 - 한국어 코퍼스 전처리 Python 실습 (1) | 2024.03.06 |