https://arxiv.org/abs/2405.19333
Multi-Modal Generative Embedding Model
Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To exp
arxiv.org
여기선 Multi modal에서 gen과 emb를 동시에 진행하는 모델을 만드려고 했습니다.
| 파이프라인(예: BLIP류/하이브리드) | MM-GEM | |
| 비전 경로 | ViT 등 Vision encoder | 동일: Vision encoder 유지 |
| 텍스트 경로(임베딩) | Text encoder로 문장 임베딩 생성 | LLM 한 개가 [EMB] 토큰의 마지막 히든을 문장 임베딩으로 사용(= 인코더 역할) |
| 텍스트 경로(생성) | Text decoder로 캡션 생성 | 같은 LLM이 [CAP] + Vin(이미지 컨텍스트)로 오토레그 생성(= 디코더 역할) |
| 접합/정렬 | 보통 별도 헤드/크로스어텐션 | 얇은 프로젝션 h1/h2/h3로 공간 정렬 |
Vision Encoder는 그대로 존재하고, 토큰을 통해 Embedding과 Generation을 진행하려고 한 점은 GRIT과 비슷한 것 같네요 ㅎㅎ

결국 NCE Loss를 사용하는 것은 동일하네요


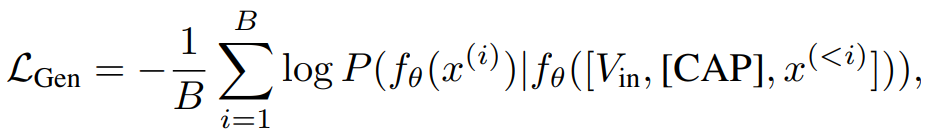


사진에 대한 캡션을 생성하는 것을 볼 수 있다.

text와 사진의 유사도를 보여준다
제대로 학습된 것을 보여준다.
파란색은 1단계만 학습되었을 경우로, 제대로 유추하지 못하는 모습을 보인다.
| 문제 상황 (Problem) | 멀티모달 모델에서 텍스트 인코더(임베딩)와 텍스트 디코더(생성)를 따로 두면 파라미터/파이프라인이 중복되고, 사전학습 LLM 재사용이 번거로움. 임베딩과 생성 목적을 하나의 LLM 안에서 충돌 없이 공동 학습·활용할 수 있는가? |
| 핵심 아이디어 (Method – 개요) | 텍스트 모듈을 완전 단일화. 동일 LLM 경로를 공유하되 두 개의 모드 토큰으로 역할을 전환: [EMB](임베딩용, 마지막 히든을 문장 임베딩으로 사용) vs [CAP](생성용, 오토레그 캡셔닝). 비전 특징은 얕은 선형 프로젝션( h1/h2/h3 )과 PoolAggregator로 LLM 내부 공간과 결합. 최종 손실은 L = LEmb(InfoNCE) + LGen(CE), 가중치 없이 단순 합. |
| 구성요소 (Method – 모듈) | • h1: ViT 특징 → 이미지 임베딩 VEmb (대조학습용) • h2: LLM 출력 헤드 Wout → 텍스트 임베딩 WEmb (대조학습용) • h3: VEmb → LLM 입력에 붙일 비전 컨텍스트 Vin (캡셔닝용) • h4: (Stage-2 전용) 얇은 선형 헤드, 지역 리트리벌만 미세 업데이트 • PoolAggregator: 전역 MeanPool(Stage-1) ↔ RoIAlign(Stage-2, 박스/마스크). |
| 학습 목표 (Loss) | 임베딩 경로: 이미지–텍스트 임베딩 v,tv,t로 InfoNCE(v→t, t→v). 텍스트 임베딩은 [EMB] 마지막 히든. 생성 경로: 입력에 [CAP]을 붙이고 VinVin을 텍스트 토큰과 연결해 다음 토큰 예측(CE). 동일 배치에서 두 경로를 동시에 학습, 합산 손실로 최적화. |
| 2-Stage 전략 (Method – 학습 절차) | Stage-1(전역, 스케일링): ViT 특징맵을 MeanPool로 요약 → VEmb=h1(⋅), Vin=h3(VEmb). 대규모 배치로 LEmb+LGen을 함께 학습(전역 정렬+기본 캡션 능력 확보). Stage-2(영역, 경량 미세화): RoIAlign(V,R)으로 영역 특징을 사용. 캡션은 h3/소프트 프롬프트만 업데이트, 리트리벌은 h4만 학습해 전역 정렬을 보존하면서 세밀 능력(영역 캡션·지역 검색)을 부착. |
| 데이터 (Training Data) | Stage-1: LAION-2B + COYO-700M ≈ 2.3B 이미지–텍스트 쌍(alt-text 중심). Stage-2: CC3M/CC12M/SBU/BLIP-filtered LAION의 캡션과 Visual Genome dense(영역 캡션) 혼합. |
| 학습법/하이퍼 (Training Setup) | 백본: ViT-B/L/L-336(OpenCLIP init) + TinyLlama(LLM). 옵티마이저: LAMB, wd=0.05. 러닝레이트: 프로젝션 5e-4, 백본·LLM 5e-5. 텍스트 길이: max 50(장문 실험 시 ↑). 온도 τ: 0.07→0.01 스케줄. 총배치 ≈ 81,920, 80k iters, 64×H800(분산 대규모). Stage-2: 소프트 프롬프트=64, 캡셔닝 배치≈2,048(60k iters), 지역 리트리벌 배치≈49,152(15k iters), 업데이트 범위 제한(h3/soft-prompt 또는 h4만). |
| 실험 설정 (Evaluation) | 리트리벌: COCO(5k), Flickr30k(1k), R@{1,5,10}. 분류: ICinW(ELEVATER) 제로샷. 캡셔닝: COCO/NoCaps. 정밀 능력: Dense Caption/지역 리트리벌(+ 시각화), L-DCI(장문 캡션 기반 리트리벌). |
| 주요 결과 (Results) | • 리트리벌/분류: OpenCLIP급(ICinW 평균 ≈ 66.3%), CLIP 상회. • 캡셔닝: Flamingo-9B보다 우수; COCO에 특화된 ClipCap보단 COCO에서 낮을 수 있으나 NoCaps에선 우위. • 장문 리트리벌(L-DCI): R@1 +5%p 이상 개선, 해상도 336에서 추가 이득. • Stage-2 효과: 동일 백본에서 L-DCI R@1 ≈ +5%p(예: 49.4→54.1) 및 영역 국소화 시각화 개선. |
| 해석/결론 (Conclusions) | 하나의 LLM에서 임베딩(InfoNCE)과 생성(CE)을 동시에 학습해도 성능 충돌이 작다는 실증. PoolAggregator + 2-Stage로 전역 정렬을 보존하면서 영역 단위의 세밀 능력을 저비용으로 부착 가능. LLM 텍스트 모듈은 장문 질의/설명 기반 리트리벌에 특히 유리. |
| 기여 (Contributions) | ① 텍스트 모듈 완전 단일화: [EMB]/[CAP] 토큰 & h1/h2/h3로 임베딩·생성 공존을 실증. ② 경량 미세화 레시피: MeanPool→RoIAlign, 일부 모듈만 업데이트(h3/soft-prompt, h4)로 세밀 능력 추가. ③ 균형 성능: 리트리벌/분류(OpenCLIP급)과 캡셔닝(경쟁력)을 동시에 달성. ④ 장문 리트리벌 이득: LLM 텍스트 모듈의 이점을 정량화. |
| 한계 (Limitations) | • Stage-1 데이터 노이즈(alt-text)로 세부 캡션 품질 한계. • 영역 데이터 부족 시 파인그레인드 능력이 즉시 발현되지 않음(소량 영역 데이터로 부트스트랩 가능). • 생성 과제는 캡셔닝 중심으로 검증—일반 언어 데이터 추가, 멀티턴 대화 등은 후속 과제. |
| 재현 체크리스트 (바로 적용용) | 1) 토큰 주입: 임베딩은 항상 [EMB] 마지막 히든, 생성은 [CAP]+Vin. 2) Stage-1: MeanPool + LEmb+LGen 함께, 큰 배치·τ 스케줄 설정. 3) Stage-2: RoIAlign로 영역/밀집 캡션·지역 리트리벌; 캡션=h3/소프트프롬프트만, 리트리벌=h4만 업데이트. 4) 정렬 보존: h4는 Identity 초기화, 본체 동결 범위 유지. 5) 장문 과제: 텍스트 maxlen↑, 입력 해상도 336 옵션 병행. |
- 목표: “하나의 LLM” 안에서 임베딩(대조학습)과 생성(캡셔닝) 목적을 동시에 학습·활용하는 텍스트 모듈 단일화(text encoder/decoder 통합). 이를 위해 Projection 층 h1/h2/h3와 PoolAggregator로 비전 특징과 LLM의 내부 공간을 연결.
- 핵심 아이디어:
- 동일 LLM 경로를 공유하면서 임베딩용 [EMB] 토큰의 마지막 히든 상태로 문장 임베딩을 만들고(InfoNCE), 생성은 [CAP] 토큰을 붙여 비전 특징 Vin과 함께 오토레그로 캡셔닝(CE Loss). 최종 손실은 단순 합.
- PoolAggregator + 2단계 학습: 1단계는 MeanPool로 글로벌 특징에 두 손실을 함께 걸어 대규모 효율 학습, 2단계는 RoIAlign으로 영역 단위(dense caption, regional pair) 미세화·강화(일부 모듈만 업데이트).
- 핵심 결과: ViT-L+TinyLlama 기준, COCO/Flickr 리트리벌 성능은 OpenCLIP과 비슷, CLIP보다 뚜렷한 향상. 장문 캡션 기반 L-DCI에서는 R@1이 +5%p 이상 개선, 336 해상도에서 추가 이득.
1) 문제 설정
멀티모달 파이프라인에서 텍스트 인코더(임베딩)와 텍스트 디코더(생성)를 따로 두면 파라미터/파이프라인이 중복되고, 사전학습 텍스트 모델을 그대로 활용하기 어려움. 본 연구는 텍스트 모듈을 하나로 통합해 효율·단순화를 달성할 수 있는지, 그리고 임베딩/생성 목적이 충돌하지는 않는지를 실증적으로 검증.
2) 방법론(설계와 학습 절차)
2.1 모듈 연결: h1/h2/h3와 단일 LLM 경로
- 가정: LLM의 입력/출력 임베딩 공간(Win/Wout) 간 변환은 근사 선형이므로, 가벼운 선형 프로젝션(h1,h2,h3)로 비전 V ↔ LLM 내부 공간을 연결 가능.
- VEmb=h1(V), WEmb=h2(Wout), Vin=h3(VEmb).
- 임베딩 경로: 텍스트는 시퀀스 끝의 [EMB] 토큰 히든을 문장 임베딩으로 사용, 이미지 임베딩과 InfoNCE(v2t,t2v)로 정렬. 최종 임베딩 손실 L_Emb=L_v2t+L_t2v.
- 생성 경로: 입력에 [CAP]을 붙이고 VinVin(비전 특징)과 함께 다음 토큰 예측(캡션 CE). 손실 L_{Gen}. 두 목적은 동일 LLM 전방경로를 공유, 최종 손실은 단순합 L=L_{Emb}+L_{Gen}.
2.2 PoolAggregator + 2단계 학습
- 1단계(대규모·글로벌): ViT 특성맵 V를 MeanPool로 요약해 대조(임베딩)+생성을 함께 학습(대규모 배치로 InfoNCE 효율↑).
- 2단계(미세·영역 강화): RoIAlign(V,R)으로 영역 R에 맞춘 특성으로 캡셔닝/리트리벌을 미세화. 이때 [CAP] → 다중 소프트 프롬프트 [CAP_i], h3·소프트프롬프트만 업데이트(임베딩 능력 보존). 미세 리트리벌은 h1 출력 위에 얇은 선형 헤드 h4를 추가해 h4만 학습(정렬 파괴 방지).
왜 2단계가 필요한가?
일반 CLIP/캡셔너는 글로벌 정보가 공간 전체를 지배해서 위치별 구분이 약함 → 영역 데이터로 h3/h4만 가볍게 조정하면 지역 구분·정밀 정렬이 유의미하게 개선됨(시각화/수치로 확인).
3) 실험 설정(재현 체크리스트)
3.1 데이터·모델
- Stage-1: LAION-2B + COYO-700M ≈ 2.3B 쌍, LLM=TInyLlama, ViT-B/L/L-336(OpenCLIP 초기화). 옵티마이저 LAMB(wd=0.05). Proj lr=5e-4, 백본들과 LLM lr=5e-5. 텍스트 maxlen=50, τ 초기 0.07, 하한 0.01. 총배치 81,920, 80k iters, 64×H800.
- Stage-2(미세 캡셔닝): CC3M/CC12M/SBU/BLIP-filtered LAION + Visual Genome dense(약 3,800만 캡션 + 180만 영역캡션), soft prompt=64, 배치 2,048, 60k iters, h3/소프트프롬프트만 업데이트.
- Stage-2(미세 리트리벌): 동일 데이터, 배치 49,152, 15k iters, h4=Identity로 초기화, h4만 학습.
3.2 평가
- 리트리벌: COCO(5k test), Flickr30k(1k), R@{1,5,10}.
- 분류: ELEVATER ICinW(여러 실세계 세트, zero-shot).
- 캡셔닝: COCO/NoCaps.
- 정밀(미세) 능력: Dense Caption/지역 리트리벌(시각화 & L-DCI 정량 벤치마크 추가).
4) 결과(주요 수치)
4.1 임베딩 vs 생성 충돌 검증
- 동일 설정에서 CLIP-Only(LEmb), Cap-Only(LGen), MM-GEM(동시) 비교 → 리트리벌·분류에서 CLIP-Only ≈ MM-GEM, 캡셔닝은 Cap-Only ≈ MM-GEM(stage-1에선 격차 미미). 즉 두 목적 동시 학습 충돌 크지 않음.
4.2 SOTA 대비(대규모 ViT-L)
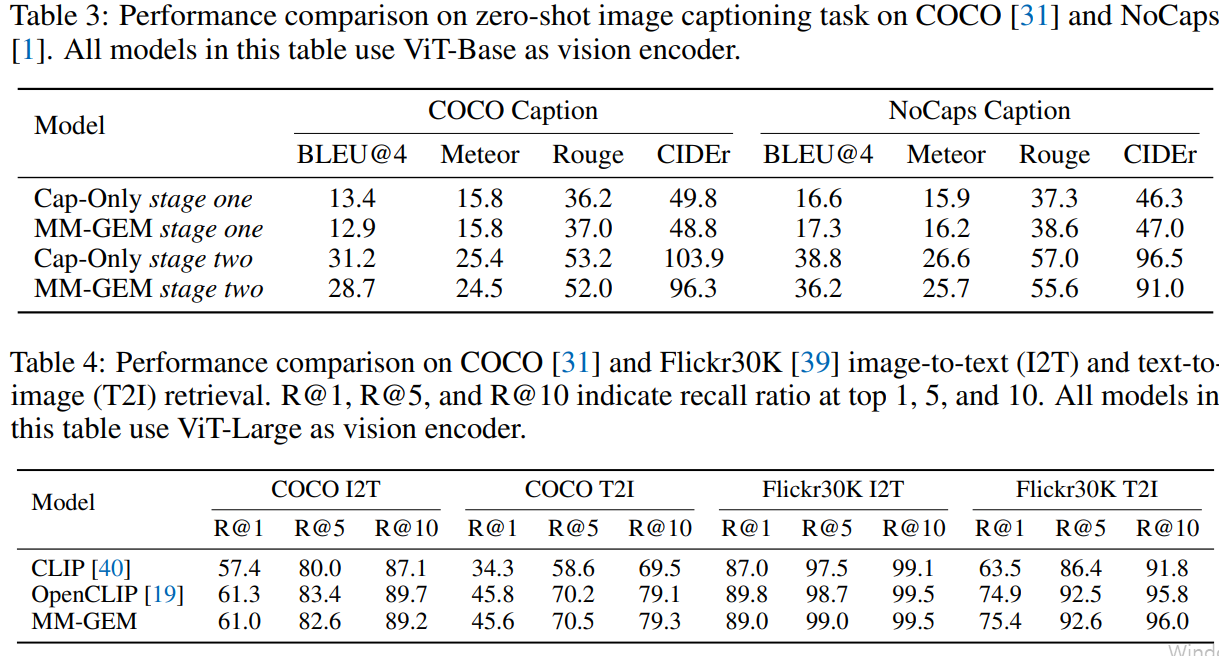
- COCO/Flickr 리트리벌: MM-GEM ≈ OpenCLIP, CLIP 대비 크게 우수(예: Flickr T2I R@1 75.4 vs 74.9(OpenCLIP), 63.5(CLIP)).
- ICinW 분류: 평균 66.3%, OpenCLIP(66.1)과 비슷·우위, CLIP(61.8) 상회.
- 캡셔닝: Flamingo-9B보다 우수(특히 NoCaps), COCO에 파인튜닝된 ClipCap보단 COCO에서 낮지만 NoCaps에선 우세.
4.3 미세(영역) 능력과 긴 텍스트
- L-DCI(장문 캡션 기반): R@1이 5%p+ 개선, 336 해상도에서 추가 향상. **개선의 주 원인=고급 텍스트 모듈(LLM)**임을 CLIP-Only-Base vs MM-GEM-Base 비교로 확인.
- 2단계 효과: 동일 백본에서 Stage-2 후 L-DCI R@1이 ~5%p 상승(예: ViT-L: 49.4→54.1).
- 시각화: Stage-2는 텍스트 질의가 해당 영역으로 정확히 국소화, Stage-1은 실패.
5) 표로 요약
| 문제 | 텍스트 인코더/디코더 분리로 파라미터/파이프라인 중복, 통합 시 임베딩–생성 충돌 우려. |
| 핵심 아이디어 | h1/h2/h3 프로젝션으로 비전–LLM 공간 정렬, [EMB]/[CAP]로 동일 LLM 경로에서 임베딩/생성 동시 학습. 최종 손실은 합. |
| PoolAggregator & 2단계 | 1단계: MeanPool 글로벌 특징 + 대규모 대조/생성 동시학습. 2단계: RoIAlign으로 영역 캡션/지역 페어에 맞춰 h3/소프트프롬프트(캡션)·h4만(리트리벌) 업데이트. |
| 데이터/세팅 | 2.3B(LAION-2B+COYO-700M), TinyLlama, ViT-B/L/L-336(OpenCLIP init), LAMB(0.05), Proj lr 5e-4 / 백본·LLM 5e-5, 배치 81,920×80k iters, τ 0.07→0.01, 64×H800. |
| 결과(요지) | OpenCLIP급 리트리벌, CLIP 대비 우수(COCO/Flickr). ICinW 평균 66.3%. 장문 리트리벌(L-DCI) +5%p, Stage-2로 추가 상승. |
| 기여 | (i) 텍스트 모듈 단일화 실증, (ii) PoolAggregator+2단계로 미세 정렬 가능, (iii) LLM 텍스트 모듈이 장문 리트리벌에 유효. |
| 한계 | Stage-1 텍스트 품질/세부성 부족, 영역 데이터 부재로 미세 능력 즉시 발현 어려움 → 소량의 영역 데이터로 쉽게 부트스트랩되지만 더 이른 도입이 유리할 수 있음. |
6) 왜 “충돌이 크지 않나?”
- 동일 LLM 경로를 쓰되, 임베딩은 [EMB] 마지막 히든, 생성은 [CAP]+Vin로 다음토큰이라는 입·출력 포인트 분리가 설계적으로 상보적이며, 실험적으로 CLIP-Only ≈ MM-GEM, Cap-Only ≈ MM-GEM(stage-1)로 확인됨 → 유의미한 성능 저하 없음.
7) 재현/응용 가이드
학습 절차(step-by-step)
- 백본 구성: ViT-L(또는 B) + TinyLlama, h1/h2/h3 프로젝션 초기화(OpenCLIP 가중치로 ViT 초기화 권장).
- Stage-1(글로벌): LAION·COYO 같은 대규모 alt-text로 InfoNCE + 캡션 CE를 동시에. MeanPool, 큰 배치(≈8만), τ/스케줄/길이(50 토큰) 설정.
- Stage-2(미세): BLIP-filtered 캡션 + Visual Genome dense로 RoIAlign 기반 영역 캡션/지역 리트리벌을 분리 헤드로 경량 업데이트(캡션=h3/소프트프롬프트만, 리트리벌=h4만).
- 긴 텍스트 과제(예: L-DCI, 도메인 캡션): LLM 텍스트 모듈의 길이/어휘를 늘리면 추가 이득(저자는 테스트에서만 maxlen=200으로 조정).
실전 팁
- 임베딩 보존: Stage-2에서 백본 동결+헤드/프롬프트만 학습하면 Stage-1의 제로샷 정렬 성능을 보존하면서 미세 능력을 얹을 수 있음.
- RAG 적용: 긴 질의/답변이 많은 도메인(예: 기술 문서)에서는 LLM 텍스트 모듈의 장문 이해가 리트리벌 Recall@1을 끌어올릴 여지가 큼(L-DCI 결과 근거).
8) 결론
MM-GEM은 하나의 LLM으로 임베딩+생성 통합을 실증했고, PoolAggregator+2단계로 미세 수준 정렬/생성까지 확장했습니다. 대규모 리트리벌/분류는 OpenCLIP 급으로 유지하고(CLIP 상회), 장문 기반 리트리벌에서는 뚜렷한 이득을 보였습니다. 통합의 실용성과 확장성을 확인했다는 점이 가장 큰 메시지입니다.
큰 지도: 패러다임별 비교
| 대표 연구 | 핵심 아이디어 | 임베딩(검색) | 생성(캡션/대화) | MM-GEM과의 차이·시사점 | |
| Dual-encoder 대조학습 | CLIP (400M 웹 쌍, 텍스트/이미지 이중 인코더로 InfoNCE) (arXiv, Proceedings of Machine Learning Research) / ALIGN(10억+ alt-text, 노이즈 허용) (arXiv, Proceedings of Machine Learning Research) / OpenCLIP(LAION 공개데이터로 재현·스케일링) (arXiv, GitHub) |
대규모 웹 쌍으로 텍스트·이미지 임베딩 정렬 | 매우 강함(리트리벌·제로샷 분류 SOTA) | 비지원(생성 전용 모듈 없음) | MM-GEM은 동일 LLM 경로 안에서 [EMB] 토큰의 마지막 히든을 임베딩으로 쓰고, [CAP]로 생성도 수행 → 텍스트 모듈 단일화로 임베딩·생성 동시 학습(손실 단순합) |
| Encoder-Decoder 공동학습(대조+생성) | CoCa(대조+캡션 동시 사전학습, 디코더 전반/후반을 단일·멀티모달로 분할) (arXiv, OpenReview, r.jordan.im) | 한 모델에서 contrastive+captioning을 동시에 최적화 | 강함 | 강함 | CoCa는 디코더를 단일/멀티모달 절반으로 분할(forward path 이원화). MM-GEM은 하나의 LLM forward를 공유하고 [EMB]/[CAP] 입력만 다르게 하며, h1/h2/h3 경량 프로젝션으로 시공간을 연결 → 사전학습 LLM 재사용 용이 |
| LLM 접합(어댑터/프로젝션) | Flamingo(Perceiver Resampler로 frozen LM 연결) (arXiv, NeurIPS Proceedings) / BLIP-2(Q-Former로 frozen LLM에 브리지) (arXiv) / FROMAGe(LLM 입·출력에 선형 프로젝션 접합, LLM 동결) (arXiv) |
강한 텍스트 생성 LLM을 동결하고 비전 특징을 어댑터로 주입 | (대개 보조적) | 매우 강함(지시 따름·Few-shot) | MM-GEM은 LLM 자체를 임베딩/생성 공용 모듈로 공동학습(동결 X) → 임베딩·생성 충돌이 유의미하게 크지 않음을 실증(1단계 결과) |
| 유니파이드 멀티태스크 | BLIP(노이즈 캡션 부트스트랩, 이해·생성 전이) (arXiv, Proceedings of Machine Learning Research) / OFA(시퀀스-투-시퀀스로 여러 과제 통합) (arXiv) / X-VLM(multi-grained 정렬) (Proceedings of Machine Learning Research) |
다양한 과제를 하나의 프레임으로 | 중간~강 | 중간~강 | BLIP/InternVL 등은 텍스트 인코더/디코더를 대부분 공유하되 일부 층을 분리하는 식의 부분 통합. MM-GEM은 완전 단일 텍스트 모듈로 통합(“one model per modality”)을 전면 채택 |
| 캡션 전용(임베딩 보조) | ClipCap(CLIP 임베딩→LM 프리픽스 매핑) (arXiv) | CLIP → 소형 맵핑 네트워크 → LM로 캡션 | 약함 | 강함 | MM-GEM은 리트리벌/분류에서도 OpenCLIP급을 유지하면서 캡션도 수행(단일 LLM) |
MM-GEM의 설계 한 줄 요약: h1/h2/h3 프로젝션 + [EMB]/[CAP] 토큰으로 하나의 LLM에서 InfoNCE 임베딩과 오토레그 캡션을 동시에 학습하고, PoolAggregator + 2단계(RoIAlign)로 미세(영역) 수준까지 확장.
MM-GEM의 차이점/차별점 (관련 연구 대비)
- 텍스트 모듈 완전 단일화(One LLM for both embedding & generation)
- 기존 통합 시도는 텍스트 경로를 분기(예: CoCa의 디코더 분할, BLIP/InternVL의 일부 층 분리)하거나 LLM을 동결해 브리지로 연결(Flamingo/BLIP-2/ FROMAGe)하는 경우가 많았습니다. MM-GEM은 같은 LLM forward를 [EMB]/[CAP] 입력 구분만으로 재사용해 텍스트 인코더와 디코더를 하나로 통합했습니다.
- 손실은 단순 합 L = LEmb + LGen으로 가중치 조정 없이 공동학습하고도 충돌이 작음을 정량 확인(1단계에서 CLIP-Only ≈ MM-GEM, Cap-Only ≈ MM-GEM).
- PoolAggregator + 2-Stage로 ‘미세(영역) 능력’을 경량 부착
- 1단계: MeanPool 특징으로 대규모 배치 대조·생성을 함께 학습(효율/스케일 확보).
- 2단계: RoIAlign(V,R)로 영역 특징을 뽑아 캡션은 h3/소프트 프롬프트만, 리트리벌은 얇은 h4만 업데이트 → 기존 정렬 성능을 해치지 않고 미세 능력만 증설.
- 대비: CLIP/일반 캡셔너는 전역 특징이 지배되어 위치 구분이 약함. 제안 2단계로 영역 캡션·지역 리트리벌이 뚜렷이 향상(시각화 & L-DCI R@1 약 +5%p).
- 장문 텍스트 리트리벌(L-DCI)에서 LLM 텍스트 모듈의 이점 실증
- ViT-L+TinyLlama 조합에서 L-DCI 기준 OpenCLIP 대비 R@1 5%p+ 향상(해상도 336에서 추가 이득). 원인: LLM 텍스트 모듈의 언어 처리 능력이 긴 서술과 문맥 대응에 유리.
- 리트리벌·분류 성능은 OpenCLIP급 유지 + 캡션도 가능
- COCO/Flickr 리트리벌과 ICinW 제로샷 분류에서 OpenCLIP과 유사/근접, CLIP 대비 뚜렷한 우위를 보이면서도, 캡셔닝(COCO/NoCaps) 성능을 함께 달성.
관련 연구별 핵심 차이를 조금 더 구체적으로
- CLIP / ALIGN / OpenCLIP: 이중 인코더 + InfoNCE로 전역 정렬에 최적화. 생성 기능은 없음. MM-GEM은 동일 LLM 경로에서 임베딩/생성을 동시에 수행. (arXiv)
- CoCa: 대조·캡션을 함께 학습하되, 디코더를 단일/멀티모달 절반으로 분할하여 텍스트 경로가 이원화됨. MM-GEM은 경로를 나누지 않고 [EMB]/[CAP]로 역할만 분리. (arXiv)
- Flamingo / BLIP-2 / FROMAGe: frozen LLM을 비전 어댑터(Perceiver Resampler, Q-Former, 선형 프로젝션 등)로 연결. MM-GEM은 LLM을 동결하지 않고 임베딩/생성 공동최적화로 충돌이 작음을 보임. (NeurIPS Proceedings, arXiv)
- BLIP / InternVL: 텍스트 인코더·디코더 대부분 공유(일부 self/cross-attn만 분리) 등 부분 통합 경향. MM-GEM은 완전 단일 텍스트 모듈을 전제로 설계.
- ClipCap: CLIP 임베딩을 프리픽스 매핑으로 캡션. 검색은 약함. MM-GEM은 리트리벌과 캡션을 동시에 강하게 수행. (arXiv)
이 논문의 기여(Contribution)를 한 줄씩 콕 집어 정리
- 텍스트 모듈 단일화의 실증: [EMB]/[CAP] 트리거 + h1/h2/h3 프로젝션으로 한 LLM에서 임베딩·생성을 동시에 학습·사용 가능함을 보였고, 충돌이 의미 있게 크지 않음을 데이터로 확인.
- 미세 정렬을 위한 경량 2-Stage 전략: PoolAggregator(MeanPool→RoIAlign) + 소수 모듈만 업데이트(h3/soft-prompt 또는 h4)로, 전역 정렬을 보존하면서 영역 캡션·지역 리트리벌 능력을 추가.
- 장문 기반 리트리벌 이득: L-DCI에서 OpenCLIP 대비 R@1 +5%p 수준의 개선을 보이며, LLM 기반 텍스트 모듈의 장문 이해 이점을 정량화.
- 효율적 사양으로 광범위 벤치마크 커버: ViT-L + TinyLlama 조합에서 리트리벌/분류는 OpenCLIP급, 캡셔닝도 경쟁력을 유지하는 균형형 성능을 달성.
1) 큰 그림: “하나의 LLM으로 임베딩+생성”
MM-GEM의 핵심은 텍스트 인코더와 디코더를 따로 두지 않고, 한 개의 LLM 경로를 임베딩·생성에 공용한다는 점입니다. 비전 특징은 가벼운 선형 프로젝션(h1/h2/h3)과 PoolAggregator를 통해 LLM 내부 공간과 정렬되고, LLM은 임베딩용 [EMB], 생성용 [CAP] 토큰으로 “역할 전환”을 합니다. 그림 1에도 이 전체 흐름이 요약되어 있습니다.
2) 텍스트–비전 결합: h1/h2/h3 프로젝션과 두 가지 목적함수
2.1 프로젝션 층: 시각–언어 잠재공간을 가볍게 연결
생성형 LM은 입력 임베딩 공간(Win)과 예측 헤드(Wout)가 근사 선형으로 이어진다는 가정하에,
- h1: 비전 특징 V → 이미지 임베딩 VEmb,
- h2: LM의 Wout → 텍스트 임베딩 WEmb,
- h3: 이미지 임베딩 VEmb → LM 입력으로 주입할 비전 특징 Vin
으로 변환합니다. 수식 (1)에 해당합니다.
직관
- h1은 “CLIP의 이미지 타워 마지막 벡터”를 LM이 쓰기 좋은 공유 임베딩 공간으로 매핑.
- h3는 “그 공유 임베딩을 LM 입력 토큰과 나란히 붙일 수 있는 형태”로 바꿔 생성 시 컨텍스트로 투입.
2.2 임베딩 목적(대조학습, InfoNCE)
이미지–텍스트 임베딩 v, t를 정규화하고 InfoNCE(v→t, t→v)를 합친 LEmb로 정렬합니다(수식 (2)). 텍스트 임베딩은 시퀀스 끝에 붙인 [EMB] 토큰의 마지막 히든 상태를 사용합니다.
- 미니 예시(임베딩):
문장 “고양이가 의자 위에 누워 있다[EMB]”의 마지막 히든을 t로, 같은 이미지의 글로벌 특징을 h1로 투영한 v로 두고, v·t 유사도가 같은 배치 내 다른 쌍보다 높아지도록 학습합니다.
2.3 생성 목적(오토레그 캡셔닝)
생성은 [CAP] 토큰을 선두에 두고, Vin(=h3(h1(V)))을 텍스트 토큰과 연결(concatenate)하여 다음 토큰 예측(크로스엔트로피)으로 학습합니다(수식 (3)).
한 배치에 대해 임베딩·생성 두 경로를 모두 전파하고, 가중치 없이 단순 합 L = LEmb + LGen으로 최적화합니다(수식 (4)).
- 미니 예시(생성):
입력: [Vin, [CAP], "A", "cat", ...] → 다음 토큰을 순차적으로 생성. 동일 모델이지만, [CAP]가 “이건 생성 모드야”라고 신호를 주는 셈.
3) Vision PoolAggregator와 2단계 학습: 전역→영역 미세화
임베딩과 생성을 동시에 학습할 때 생기는 두 난점:
(1) 임베딩은 보통 전역 특징 1개만 쓰지만, 생성은 공간적 세부가 필요함.
(2) 대규모 대조 데이터(alt-text)는 노이즈가 있어 생성 품질 저하 우려.
이를 풀기 위해 MM-GEM은 PoolAggregator + 2-Stage 전략을 씁니다.
Stage-1: 전역(mean-pool)으로 빠르고 크게
이미지 특징맵 V∈ℝ^{C×H×W}에서 MeanPool(V)로 전역 벡터를 만들고,
- 임베딩용 VEmb = h1(MeanPool(V)),
- 생성용 Vin = h3(h1(MeanPool(V)))
으로 써서 LEmb + LGen을 함께 학습합니다(수식 (5)). 이렇게 하면 대형 배치(대조학습에 유리)로 빠르게 수렴시킬 수 있습니다. - 효과: 전역 정렬과 기본 캡션 능력을 가성비 좋게 확보.
Stage-2: RoIAlign으로 영역 단위로 미세화
Stage-2에서는 이미지-캡션 + 영역 캡션(dense caption) 혼합 데이터에서 RoIAlign(V,R)으로 영역 R에 맞춘 특징을 뽑아 세밀한 생성/검색 능력을 붙입니다(수식 (6)). 이때
- 생성 경로: [CAP] → 다중 소프트 프롬프트 [CAP_i]로 바꾸고 h3와 소프트 프롬프트만 업데이트(임베딩 정렬 보존).
- 리트리벌 경로: h1 출력 위에 얇은 선형 헤드 h4를 추가하고 h4만 학습해, 기존 전역 정렬을 깨지 않습니다(수식 (7)).
- 왜 이렇게? 전통적 CLIP/캡셔너는 전역 특징이 공간 전체를 지배해 위치 구분이 약합니다. 영역 데이터로 h3/소프트프롬프트(생성) 또는 h4(임베딩)만 건드리면, 세밀 능력만 추가로 얻고 본체의 전역 제로샷 성능은 보존됩니다.
- 미니 예시(세밀 캡션):
빨간 박스(R)가 “가로수” 영역이라면, RoIAlign으로 그 부분 특징만 뽑아 “Green leaves on the tree” 같은 영역 캡션을 안정적으로 생성(그림 2 사례). - 미니 예시(세밀 검색):
질의: “파란 표지판이 보이는 구역”. Stage-1은 전역 정보에 끌려 오탐이 잦지만, Stage-2에서 h4를 학습하면 해당 영역 유사도가 또렷이 높아져 정확한 지역 매칭이 됩니다(그림 3 비교).
4) 한 장 요약: 구성요소–입출력–학습 신호
| 구성/기호 | 하는 일 | 입/출력 | 학습 신호 |
| h1 | 비전→공유 임베딩 | V → VEmb | InfoNCE(임베딩) |
| h2 | LM Wout→텍스트 임베딩 | Wout → WEmb | InfoNCE(임베딩) |
| h3 | 비전 임베딩→LM 입력 컨텍스트 | VEmb → Vin | 캡션 CE(생성) |
| [EMB] | “임베딩 모드” 트리거 | 마지막 히든 = 텍스트 임베딩 | InfoNCE(임베딩) |
| [CAP]/[CAP_i] | “생성 모드” 트리거(soft prompt) | Vin와 연결해 토큰 생성 | 캡션 CE(생성) |
| PoolAggregator | V에서 전역/영역 특징 추출 | MeanPool(V) 또는 RoIAlign(V,R) | Stage-1: 전역, Stage-2: 영역 |
| h4(선형 헤드) | 세밀 리트리벌 전용 헤드 | RoIAlign→h1→h4 | h4만 학습(정렬 보존) |
5) 학습 절차를 코드처럼(요지)
Stage-1 (전역·대규모)
- V ← ViT 특징맵 → MeanPool(V).
- v = h1(MeanPool(V)), Vin = h3(v).
- 텍스트 뒤에 [EMB]를 붙여 마지막 히든을 t로 추출.
- InfoNCE(v↔t)로 LEmb 계산; [CAP] + Vin + 텍스트로 LGen 계산.
- L = LEmb + LGen로 역전파(가중합 없이).
Stage-2 (영역·경량 업데이트)
- 주어진 박스/마스크 R에 대해 RoIAlign(V,R).
- 생성: [CAP]→[CAP_i]로 바꾸고 h3와 소프트 프롬프트만 업데이트.
- 리트리벌: h1 출력 위에 선형 헤드 h4를 얹고 h4만 학습.
- 이렇게 세밀 능력을 추가하면서 Stage-1 정렬은 보존.
6) 왜 이 설계가 먹히나? (디자인 합리성)
- 한 LLM, 두 역할의 공존성: 임베딩은 [EMB]의 마지막 히든, 생성은 [CAP]+Vin 기반 출력 분기라 출발점/목적이 다르면서도 가중치 공유로 상호 이득을 보게 설계. 실제로 두 목적을 가중치 조정 없이 합해도 잘 학습됨(경험적).
- 효율성: Stage-1에서 전역 mean-pool을 쓰면 대규모 배치로 InfoNCE를 튼튼히 학습 가능. 이후 Stage-2에서 일부 모듈만 만져 세밀 능력을 저비용으로 부착.
- 정렬 보존: 세밀 리트리벌은 h4만 학습(Identity 초기화)하여 전역 제로샷 성능을 흐트러뜨리지 않음.
7) 재현 팁(실무 적용 시 체크)
- 텍스트 임베딩 포인트: [EMB] 마지막 히든을 항상 사용(평균/첫 토큰 아님).
- Pool 전략 스케줄링: Stage-1은 MeanPool(대규모 배치), Stage-2는 RoIAlign으로 영역 정밀화.
- 모듈 업데이트 범위: 생성=h3/소프트 프롬프트만, 리트리벌=h4만. 기존 정렬을 보존한 채 세밀 능력만 올린다.
결과(Results)
- 임베딩·분류 성능: ViT-Large+TinyLlama 구성에서 COCO/Flickr 리트리벌과 ICinW 제로샷 분류가 OpenCLIP과 대등하며 CLIP을 크게 상회합니다. 평균 ICinW는 66.3%로 OpenCLIP(66.1)과 유사, CLIP(61.8)보다 높습니다.
- 캡셔닝 성능: Flamingo-9B보다 우수, ClipCap(COCO에 파인튜닝) 대비 COCO는 열세지만 NoCaps에선 우세합니다. 구체 수치로 COCO CIDEr 110.9, NoCaps CIDEr 100.7 보고.
- 장문 텍스트 기반 리트리벌(L-DCI): R@1이 +5%p 이상 개선되며, 입력 해상도 336에서 추가 향상. 개선은 학습 목적이 아니라 텍스트 모듈(LLM)의 이점에서 기인함을 비교로 확인.
- 2-Stage(미세화) 효과: Stage-2 적용 시 L-DCI R@1이 약 +5%p 상승(예: 49.4→54.1). 시각화에서도 Stage-2가 질의-영역 정밀 정합을 확실히 회복/강화함을 보여줌.
- 동일 모델로 영역 캡션·지역 리트리벌 수행: 추가 학습 없이도 영역 단위 캡션·파인그레인드 검색이 가능함을 정성/정량으로 제시.
결론(Conclusions)
- 한 개의 LLM에 임베딩(대조학습)과 생성(오토레그 캡션)을 함께 담아도 유의미한 성능 충돌이 없다는 것을 실증.
- 제안한 PoolAggregator와 멀티-스테이지(MeanPool→RoIAlign)가 파인그레인드 과제(영역 캡션/지역 리트리벌)에 효과적이며, 장문 리트리벌에서 LLM 텍스트 모듈의 이점을 확인.
- 통합 패러다임으로 리트리벌·분류(OpenCLIP급)과 캡셔닝(경쟁력)을 동시에 달성.
기여(Contributions)
- 텍스트 모듈 단일화: [EMB]/[CAP] 트리거와 h1/h2/h3 연결로 임베딩·생성 목적을 단일 LLM 안에 캡슐화하여 모달리티 통합을 전진시킴.
- PoolAggregator + 2-Stage 학습: 전역(MeanPool)→영역(RoIAlign)으로 이어지는 설계로 효율과 미세 능력을 동시에 확보.
- 균형형 성능의 실증: 임베딩 벤치마크에서 경쟁력을 유지하면서 생성 성능도 보존·확장함을 대규모 실험으로 제시.
한계(Limitations)
- Stage-1 텍스트 품질 제약: 대규모 alt-text는 노이즈/상세 부족으로, 캡션 손실이 원하는 세부 표현까지 끌어올리기엔 제한적.
- 영역 데이터 부재: Stage-1에 리전 수준 데이터가 부족하여 파인그레인드 능력이 즉시 발현되지 않음(소량 리전 데이터만으로 부트스트랩 가능).
- 생성 과제 범위: 본 논문은 주로 캡셔닝에 초점을 맞췄으며, 일반 언어 데이터 추가의 영향 등은 후속 연구 과제로 남김.
한 줄 정답
- 예전(많은 기존 방식): Vision encoder + Text encoder + Text decoder(총 3개 경로)
- MM-GEM: Vision encoder + (하나의) LLM (+ 아주 얇은 프로젝션 h1/h2/h3)
→ 즉, 텍스트 인코더를 없애고 LLM 하나가 “인코더+디코더” 역할을 겸함. 프로젝션은 세 모듈을 대체한 게 아니라, 비전/텍스트 공간을 가볍게 이어주는 브리지예요.
전/후 구조 비교
기존 파이프라인(예: BLIP류/하이브리드) MM-GEM| 비전 경로 | ViT 등 Vision encoder | 동일: Vision encoder 유지 |
| 텍스트 경로(임베딩) | Text encoder로 문장 임베딩 생성 | LLM 한 개가 [EMB] 토큰의 마지막 히든을 문장 임베딩으로 사용(= 인코더 역할) |
| 텍스트 경로(생성) | Text decoder로 캡션 생성 | 같은 LLM이 [CAP] + Vin(이미지 컨텍스트)로 오토레그 생성(= 디코더 역할) |
| 접합/정렬 | 보통 별도 헤드/크로스어텐션 | 얇은 프로젝션 h1/h2/h3로 공간 정렬 |
프로젝션이 하는 일(“대체”가 아니라 “정렬/브리지”)
- h1: V → VEmb
ViT 특징을 대조학습(InfoNCE)용 이미지 임베딩 공간으로 투영. - h2: (텍스트 히든/Wout) → WEmb
텍스트 임베딩도 같은 임베딩 공간으로 살짝 맞춤(구현에 따라 [EMB] 마지막 히든이나 출력헤드 표현을 선형 변환). - h3: VEmb → Vin
이미지 임베딩을 LLM 입력 토큰과 함께 쓸 수 있는 컨텍스트로 변환(캡션 생성에 사용).
즉, 프로젝션은 무거운 인코더를 대신하는 게 아니라,
- 이미지/텍스트 임베딩 공간을 맞추고(h1/h2),
- 이미지를 LLM이 읽을 수 있는 입력 형태(Vin)로 바꿔 생성에 주입(h3)합니다.
흐름 예시로 감 잡기
- 리트리벌(임베딩 모드):
이미지 → ViT → MeanPool → h1 → v
텍스트+[EMB] → LLM → (마지막 히든 → h2) → t
→ InfoNCE 로 v↔t 정렬 - 캡션(생성 모드):
이미지 → ViT → MeanPool → h1 → h3 → Vin
입력: [Vin, [CAP], "A", "cat", ...] → LLM이 다음 토큰 예측으로 캡션 생성
결론
- 맞는 부분: “예전엔 3경로였고, MM-GEM은 텍스트 인코더를 없애서 경로를 단순화했다.”
- 보완할 점: “프로젝션으로 전부를 대체한 게 아니라, 비전 인코더는 그대로 두고, LLM 하나가 인코더+디코더를 겸하도록 만들었으며, **프로젝션(h1/h2/h3)**은 공간 정렬/연결을 위한 얇은 브리지다.”
필요하면, 당신 실험 코드에서 [EMB]/[CAP] 주입 + h1/h2/h3 모듈을 어디에 붙이면 되는지 PyTorch 스켈레톤으로 바로 뽑아줄게요.
한 줄 정답
- 예전(많은 기존 방식): Vision encoder + Text encoder + Text decoder(총 3개 경로)
- MM-GEM: Vision encoder + (하나의) LLM (+ 아주 얇은 프로젝션 h1/h2/h3)
→ 즉, 텍스트 인코더를 없애고 LLM 하나가 “인코더+디코더” 역할을 겸함. 프로젝션은 세 모듈을 대체한 게 아니라, 비전/텍스트 공간을 가볍게 이어주는 브리지예요.
전/후 구조 비교
| 파이프라인(예: BLIP류/하이브리드) | MM-GEM | |
| 비전 경로 | ViT 등 Vision encoder | 동일: Vision encoder 유지 |
| 텍스트 경로(임베딩) | Text encoder로 문장 임베딩 생성 | LLM 한 개가 [EMB] 토큰의 마지막 히든을 문장 임베딩으로 사용(= 인코더 역할) |
| 텍스트 경로(생성) | Text decoder로 캡션 생성 | 같은 LLM이 [CAP] + Vin(이미지 컨텍스트)로 오토레그 생성(= 디코더 역할) |
| 접합/정렬 | 보통 별도 헤드/크로스어텐션 | 얇은 프로젝션 h1/h2/h3로 공간 정렬 |
프로젝션이 하는 일(“대체”가 아니라 “정렬/브리지”)
- h1: V → VEmb
ViT 특징을 대조학습(InfoNCE)용 이미지 임베딩 공간으로 투영. - h2: (텍스트 히든/Wout) → WEmb
텍스트 임베딩도 같은 임베딩 공간으로 살짝 맞춤(구현에 따라 [EMB] 마지막 히든이나 출력헤드 표현을 선형 변환). - h3: VEmb → Vin
이미지 임베딩을 LLM 입력 토큰과 함께 쓸 수 있는 컨텍스트로 변환(캡션 생성에 사용).
즉, 프로젝션은 무거운 인코더를 대신하는 게 아니라,
- 이미지/텍스트 임베딩 공간을 맞추고(h1/h2),
- 이미지를 LLM이 읽을 수 있는 입력 형태(Vin)로 바꿔 생성에 주입(h3)합니다.
흐름 예시로 감 잡기
- 리트리벌(임베딩 모드):
이미지 → ViT → MeanPool → h1 → v
텍스트+[EMB] → LLM → (마지막 히든 → h2) → t
→ InfoNCE 로 v↔t 정렬 - 캡션(생성 모드):
이미지 → ViT → MeanPool → h1 → h3 → Vin
입력: [Vin, [CAP], "A", "cat", ...] → LLM이 다음 토큰 예측으로 캡션 생성
결론
- 맞는 부분: “예전엔 3경로였고, MM-GEM은 텍스트 인코더를 없애서 경로를 단순화했다.”
- 보완할 점: “프로젝션으로 전부를 대체한 게 아니라, 비전 인코더는 그대로 두고, LLM 하나가 인코더+디코더를 겸하도록 만들었으며, **프로젝션(h1/h2/h3)**은 공간 정렬/연결을 위한 얇은 브리지다.”
필요하면, 당신 실험 코드에서 [EMB]/[CAP] 주입 + h1/h2/h3 모듈을 어디에 붙이면 되는지 PyTorch 스켈레톤으로 바로 뽑아줄게요.