https://github.com/nlpai-lab/MIRAGE
GitHub - nlpai-lab/MIRAGE: MIRAGE is a light benchmark to evaluate RAG performance.
MIRAGE is a light benchmark to evaluate RAG performance. - nlpai-lab/MIRAGE
github.com
https://arxiv.org/abs/2504.17137
MIRAGE: A Metric-Intensive Benchmark for Retrieval-Augmented Generation Evaluation
Retrieval-Augmented Generation (RAG) has gained prominence as an effective method for enhancing the generative capabilities of Large Language Models (LLMs) through the incorporation of external knowledge. However, the evaluation of RAG systems remains a ch
arxiv.org
RAG 시스템을 평가하기는 요소들이 너무 많다.
Retriever이 잘 못 되었을 경우, Generation이 잘 못 되었을 경우, 이미 내제적으로 바로 답변을 할 수 있는 등 다양하다!
이러한 변인을 통제하기 위해 만들어진 벤치마크다.

논문에서 사용한 4가지 경우의 수이다.
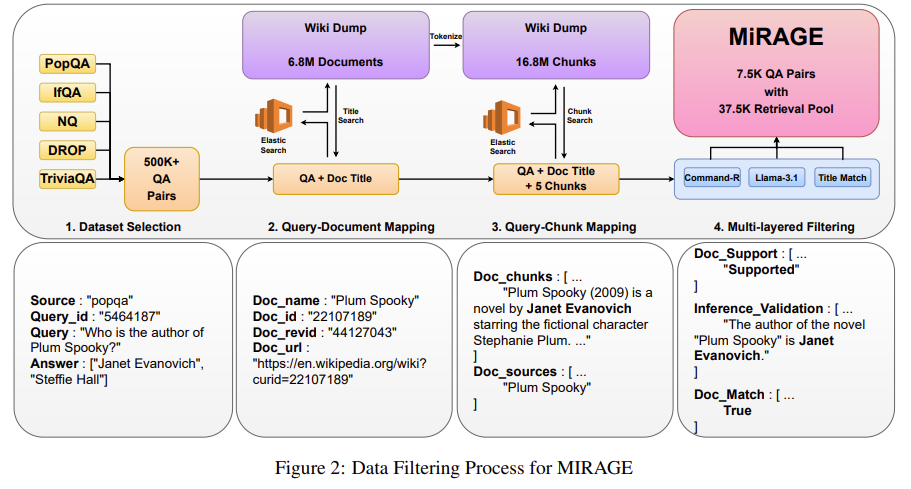
다양한 QA셋을 수집한다
여기서 기준은 위키 기반으로 되어 있고, answer span이 존재하며, 문서 title이 연결 가능한 구조여야 한다.
=> Multi hop 은 여기서 빠지게 되어 버림
그럼 Data pair가 500k가 넘는데 쿼리를 통해 Doc를 역추적하여 QA와 Doc가 매칭되도록 구성한다.
여기서 61k dataset 구성됨
그 후 문서를 330 토큰 사이즈로 청킹(110, 550 토큰보다 성능이 좋았었음)하고, top-5로 정렬
그 후 필터링을 통해 데이터 정제를 진행
1. Context가 충분히 답변할 수 있도록 주어지는지 확인
2. Llama-3.1-8B를 통해 Context를 주지 않아도 답변을 잘 하는지 확인
3. 쿼리 당 최소 하나의 관련 청크가 있도록 정확히 매핑 진행
인간 평가도 높은 수준의 일치율 나왔음
그리하여 37.8k Doc와 7.56k Query로 구성됨
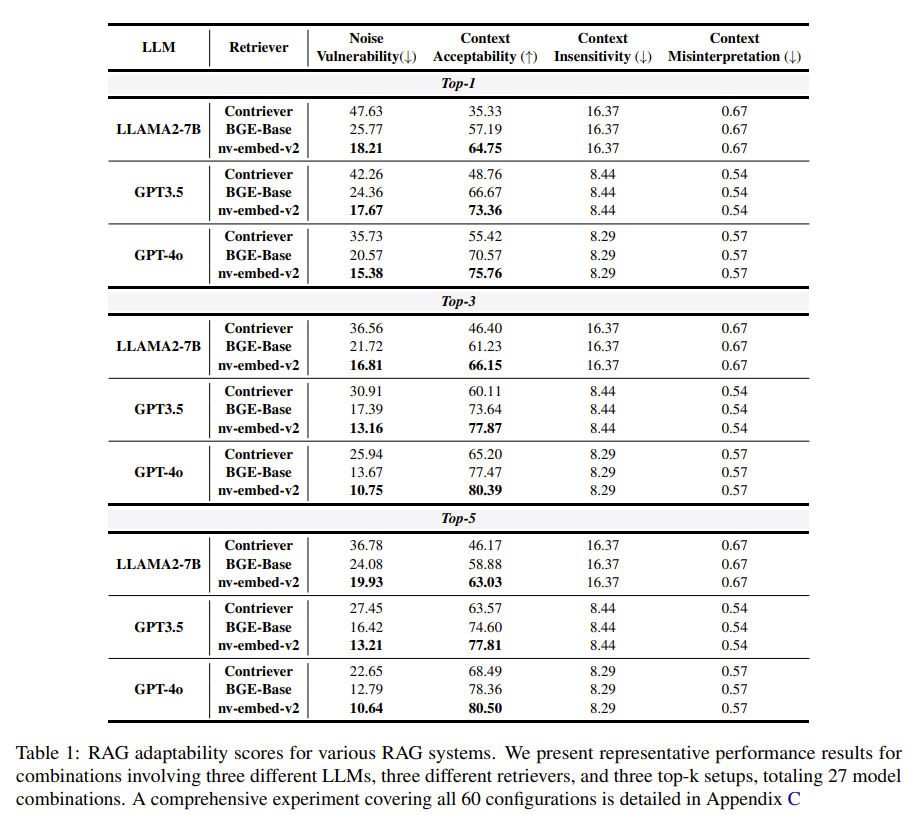
LLama2-7B는 노이즈에 민감하며, nv-embed 성능 좋음!
GPT 모델이 역시 좋은 성능을 보여주는 것을 볼 수 있다.
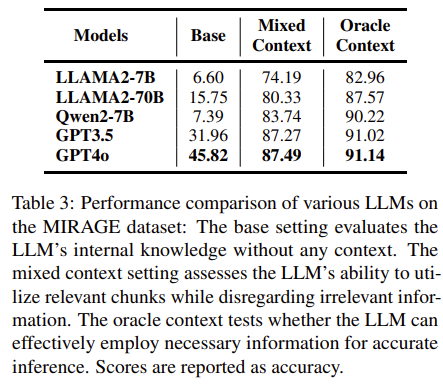
이 표를 기반으로 다른 실험을 진행할 것 같네요 ㅎㅎ
| 📌 문제 상황 | - 기존 RAG 평가 방법은 retrieval과 generation의 복합적 상호작용을 정량적으로 분리 평가하지 못함 - 평가에 사용되는 retrieval pool이 지나치게 커서 비효율적 - LLM 기반 평가 (ex. GPT-4) 의존이 높아 비용과 재현성에 문제 |
| 🧠 목적 | - retriever + LLM 조합별 RAG 성능을 세밀하게 평가할 수 있는 lightweight 벤치마크 제안 - context 활용 능력과 noise 민감성까지 평가할 수 있는 정량적 지표 제공 |
| ⚙ 방법론 | ① QA 데이터 5종(PopQA, NQ, TriviaQA, etc.)에서 7.5K 쌍 수집 ② Wikipedia 문서에 쿼리 역매핑 → 문서 chunk(330 tokens)로 분할 ③ Command-R + LLaMA-3.1로 relevance 필터링 ④ 사람 검증(95% 일치, α=0.85)으로 라벨 품질 확보 ⑤ Base / Oracle / Mixed 세팅 구성 ⑥ 4가지 지표 정의: Noise Vulnerability, Context Acceptability, Insensitivity, Misinterpretation |
| 📊 실험 결과 | - 총 60개 조합 실험 (LLM × Retriever × Top-1/3/5) - GPT-4o + nv-embed-v2 조합이 최고 성능 (Mixed Accuracy 87.5%) - LLaMA2 계열은 noise에 매우 취약 - Top-3 retrieval이 가장 효과적, Top-5는 noise로 성능 하락 |
| 🎁 기여 | - 정량적 평가 metric 4종 제안 - retrieval vs generation 분석 가능한 구조적 평가 프레임워크 제시 - 작고 효율적인 RAG 벤치마크 (7.5K QA, 37.8K chunk) 공개 - 인간 검증 기반의 정확도 높은 라벨 확보 - 다양한 LLM-Retriever 조합 실험으로 실제 적용 가능성 입증 |
| ⚠ 한계 | - 사전학습 데이터셋 기반이므로 데이터 오염 가능성 존재 - 단일-hop QA에 국한, multi-hop reasoning 평가 불가능 - Oracle 세팅에서 일부 모델이 90% 이상 정확도 → 난이도 제한 - 데이터셋 간 비율 불균형 (ex. NQ 비중 큼) - 일부 false label 존재 가능 (소수지만 영향 有) |
🔍 문제 상황 (Problem)
| 기존 한계 | 기존 RAG 벤치마크는 ① 위키 전 범위를 다루어 연산비용이 큼 ② Retrieval과 Generation 간의 상호작용을 간과 ③ GPT-4 같은 외부 LLM에 의존해 비용·재현성에 문제가 있음 |
| 평가의 어려움 | RAG의 retrieval과 generation 성능을 세분화해서 정량적으로 평가하기 위한 체계가 부족함 |
🎯 목표 및 기여 (Goal & Contribution)
- Retrieval과 Generation의 상호작용을 정밀하게 측정할 수 있는 평가 체계 수립
- Top-k chunk 설정에 따라 혼합 노이즈 환경에서도 모델의 민감도 및 활용 능력 평가
- 정량적 평가 metric 4종 제안:
Noise Vulnerability, Context Acceptability, Context Insensitivity, Context Misinterpretation
🧩 방법론 요약 (Methodology)
✅ 데이터셋 구성 (총 7,560 QA pairs)
| 단계 | 설명 |
| 1. QA 데이터 수집 | PopQA, TriviaQA, DROP, IfQA, NQ 등에서 50만 QA 쌍 수집 |
| 2. 위키 문서 매핑 | 2024년 9월 위키백과 덤프 사용 (6.8M 문서 → 16.8M chunk 생성) |
| 3. 문서 chunking | BERT tokenizer로 330-token 단위 chunk 생성 |
| 4. 필터링 | LLM 기반 자동 필터링 + 인간 검증을 통해 oracle chunk와 noise chunk 구분 |
| 5. 최종 세트 | QA 쌍 7,560개, Retrieval chunk 37,800개로 구성 |
⚙ 평가 세팅 (Evaluation Settings)
| 설정 | 설명 |
| Base (AnsB) | Retrieval 없이 LLM 자체 지식으로 응답 |
| Oracle (AnsO) | 정답이 포함된 단일 chunk만 제공 |
| Mixed (AnsM) | 정답 포함 chunk + noise chunk 총 5개 혼합 |
📏 평가 지표 (4가지 RAG 적응성 지표)
| 지표 | 정의 | 해석 |
| 1. Noise Vulnerability | Oracle에선 맞췄지만 Mixed에선 틀림 | Noise에 쉽게 흔들림 |
| 2. Context Acceptability | Oracle과 Mixed 모두 맞춤 | 노이즈 속에서도 문맥 잘 활용 |
| 3. Context Insensitivity | Base와 Oracle 모두 틀림 | 문맥을 전혀 활용 못함 |
| 4. Context Misinterpretation | Base는 맞췄지만 Oracle은 틀림 | 문맥이 들어가자 오히려 성능 저하 (Hallucination) |
📊 실험 결과 요약
🔹 모델 성능 비교
| 모델 | Base | Oracle | Mixed |
| GPT-4o | 45.8% | 91.1% | 87.5% |
| GPT-3.5 | 31.9% | 91.0% | 87.3% |
| LLaMA2-70B | 15.8% | 87.6% | 80.3% |
| LLaMA2-7B | 6.6% | 83.0% | 74.2% |
| Qwen2-7B | 7.4% | 90.2% | 83.7% |
➡ Retrieval 없이 성능 낮은 모델도, retrieval context 주면 큰 향상 확인
🔸 Retriever 성능 (Top-5 기준)
| Retriever | F1 | Recall | NDCG |
| nv-embed-v2 | 73.9 | 96.4 | 89.8 |
| E5-L | 71.4 | 93.0 | 87.4 |
| BGE-L | 68.6 | 92.0 | 85.2 |
| Contriever | 39.8 | 71.4 | 60.0 |
➡ 최신 retriever 모델일수록 더 정확한 chunk를 제공
🔺 RAG 적응성 비교 예시 (Top-5 기준)
| LLM + Retriever 조합 | Noise Vulnerability ↓ | Context Acceptability ↑ |
| GPT-4o + nv-embed-v2 | 10.6% | 80.5% |
| GPT-3.5 + BGE-B | 16.4% | 74.6% |
| LLAMA2-7B + Contriever | 36.8% | 46.2% |
➡ GPT-4o + nv 조합이 가장 견고함. LLAMA2는 noise에 민감
📌 한계 및 향후 방향
| 한계 | 설명 |
| 📁 데이터 중복 가능성 | 일부 QA 쌍이 사전학습된 모델에 포함되었을 위험 |
| 🔁 단일-hop QA 집중 | multi-hop reasoning 평가 불가 |
| ⚖ 데이터 편중 | 특정 QA셋 (예: NQ)에 비해 균형 부족 |
| 🧪 난이도 한계 | Oracle 세팅에선 SOTA 모델이 90% 이상 정확도 |
| ⚠ 라벨 오류 가능성 | 자동화된 필터링 과정에서 소수의 오류 존재 가능 |
📂 전체 정리 표
| 항목 | 내용 |
| 문제 | RAG 성능을 retrieval vs generation 관점에서 세분화 평가하는 체계 부족 |
| 제안 | MIRAGE: 7.5K QA 쌍 + 37.8K retrieval pool로 구성된 metric-intensive benchmark |
| 방법 | 다단계 필터링 + 자동/수동 검증 + 3개 세팅 (Base, Oracle, Mixed) 실험 구성 |
| 지표 | Noise Vulnerability, Context Acceptability, Insensitivity, Misinterpretation |
| 실험 | 60개 RAG 조합 평가 (5 LLM × 5 Retriever × Top-1/3/5) |
| 결과 | GPT-4o + nv-embed-v2 가장 우수, noise에 강건함 |
| 한계 | Multi-hop 미포함, 데이터 중복 위험 존재, 난이도 높지 않음 |
📚 관련 연구 분류 및 핵심 논문 정리
1. 🔄 Retrieval-Augmented Generation (RAG) 개요 및 기초 연구
| 주제 | 설명 | 대표 논문 |
| RAG 개념 정립 | LLM의 파라메트릭 지식 한계를 극복하기 위해 외부 문서를 검색해 활용 | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks |
| Parametric vs. Non-parametric | LLM 내장 지식(parametric)과 검색 지식(non-parametric)의 상호작용 분석 | When Not to Trust Language Models |
| 도메인 적응 & 환각 완화 | RAG는 hallucination 완화 및 도메인 적응에 효과적 | Mitigating LLM Hallucination via Self-Reflection |
2. 📊 RAG 평가 도구 및 프레임워크
| 이름 | 설명 | 한계점 |
| RAGAS | Retrieved context의 품질, 정답성 등을 자동 평가 | 문장 수준 기반의 coarse-grained 평가 |
| ARES | 경량 LLM으로 RAG 응답 평가 | 특정 도메인 또는 설정에 overfit 가능 |
| RAGCHECKER | retrieval과 generation 간 상호작용 분석 | fine-grained지만 전용 벤치마크 부족 |
🔎 MIRAGE의 기여: 위 평가 프레임워크들이 지닌 데이터셋 부족, 범용성 제한을 보완하고, 정량적 metric 4종을 새롭게 정의해 해석력을 높임.
3. 🧠 평가용 QA 데이터셋
| 데이터셋 | 설명 | 단점 |
| TriviaQA | 위키 기반, 95K QA, 다양한 근거 포함 | retrieval pool이 따로 없음 |
| Natural Questions (NQ) | 구글 검색 기반 QA, Wikipedia 문서 연결 | 전체 문서를 대상으로 하므로 느림 |
| PopQA | 엔터티 중심 QA, 단일 정답 존재 | retrieval용 chunk 제공 안됨 |
| DROP | 수치 및 논리 추론 중심 QA | multi-hop 요소가 많음 |
| IfQA | counterfactual QA | 오히려 평가 불안정성 초래 가능 |
🔎 MIRAGE의 기여: 위의 기존 QA 데이터를 기반으로 재가공하여, retrieval chunk까지 포함된 통합 QA-Retrieval 평가용 벤치마크 구성
4. 📐 RAG 전용 벤치마크
| 벤치마크 | 설명 | 한계 |
| RGB (Chen et al., 2024) | 다양한 LLM에 대해 RAG 성능 비교 | retriever 평가 항목은 약함 |
| RECALL (Liu et al., 2023) | LLM이 외부 정보에 대해 얼마나 robust한지 측정 | retrieval + generation 통합 세팅 없음 |
🔎 MIRAGE의 차별점:
- Base/Oracle/Mixed 3단계 실험 설계
- 정확한 chunk mapping
- retriever와 generator의 조합별 분석이 가능한 통합 평가
📌 MIRAGE와 가장 밀접한 논문들 요약
| 논문명 | 주요 내용 | MIRAGE와의 관련성 |
| RAGAS | 정답 일치도, 근거 적합도, 응답 신뢰성 자동 평가 | MIRAGE는 평가 지표를 모델의 적응성 중심으로 확장 |
| ARES | LLM 기반 자동 평가 모델 (judge) 제안 | MIRAGE는 LLM 성능과 retrieval 성능을 분리 및 분석 |
| RGB | 다양한 RAG 세팅 비교 실험 | MIRAGE는 작은 retrieval pool로 실험 효율성과 재현성 확보 |
| RECALL | 반사실적 정보에 대한 RAG robustness 평가 | MIRAGE는 반사실뿐 아니라 혼합 noise 환경 평가 가능 |
📈 연구자로서의 활용 제안
| Retrieval 모델 성능 평가 | 동일 QA 쿼리에서 chunk level recall/F1/NDCG 분석 가능 |
| LLM의 context 활용도 분석 | Base vs Oracle vs Mixed 비교로 context sensitivity 추출 |
| RAG 조합 설계 최적화 | LLM × Retriever 간 Noise Vulnerability 변화 확인 가능 |
| Adversarial Benchmark 확장 | 향후 multi-hop, counterfactual reasoning 세팅 가능 |
📝 결론 요약
- MIRAGE는 기존의 한계를 인지하고, 세밀한 RAG 시스템 분석을 위한 정량적 지표와 효율적 벤치마크 구성을 제시
- RAG 평가 및 관련 벤치마크의 발전 흐름에 있어 현재 시점에서 가장 종합적이고 재현 가능한 접근법을 제공
- MIRAGE는 향후 instruction tuning, robustness, adversarial QA, multi-hop reasoning 연구에서도 활용 가능성이 높음
🏗 MIRAGE 벤치마크 생성 과정 요약
MIRAGE는 retriever와 LLM 평가를 동시에 정밀하게 수행할 수 있도록 설계된 QA + Retrieval 데이터셋입니다.
📌 전체 구성 요약
| 총 QA 쌍 | 7,560개 |
| Retrieval Pool | 37,800개 chunk |
| Chunk 구성 | 1개 정답 포함 (positive), 나머지는 유사하지만 무관한 내용 (negative) |
🧩 데이터셋 구축 단계별 정리
1. Dataset Selection (QA 데이터 선별)
| 선정 기준 | (1) Wikipedia 기반, (2) answer span 존재, (3) 문서 title 연결 가능 |
| 사용된 데이터 | PopQA, Natural Questions, TriviaQA, DROP, IfQA |
| 제외된 데이터 | Multi-hop QA (예: HotpotQA, WikiHop) → 단일-hop QA에 집중 |
🔎 의의: 현실적인 RAG 사용 사례 대부분이 단일-hop QA임을 반영해, retrieval 정확성 중심 평가에 집중
2. Query-to-Document Mapping (쿼리-문서 매핑)
| 절차 | 설명 |
| 위키 덤프 사용 | 2024년 9월 enwiki (6.8M 문서) |
| Mapping 방식 | Elasticsearch로 쿼리를 원래 위키 문서에 역추적 (title 기반) |
| 필터링 기준 | 중복 문서 제거, 매핑 실패 쿼리 제거 → 정확한 문서-질문 정렬 보장 |
🔎 의의: 기존 QA에서 retrieval system 없이 사용된 QA 쌍을 정확한 문서 연결이 되도록 재구성
3. Document Chunking (문서 청킹)
| 절차 | 설명 |
| Tokenizer | BERT-base-uncased 사용 |
| Chunk 길이 | 330 tokens (실험적으로 최적의 길이) |
| 목적 | 문맥 보존 및 sentence-level 단위 유지 |
🔎 의의: retrieval 성능과 generation 안정성의 균형을 고려해 최적화된 chunk 크기 설정
4. Multi-layered Filtering (다단계 필터링)
Step 1: Support Labeling
- 모델: Cohere Command-R 사용
- 목적: chunk가 query에 답할 수 있는 지원 정보 포함 여부 자동 판단 (Supported / Not Supported)
Step 2: Inference Validation
- 모델: LLaMA-3.1-8B Instruct
- 방식: 해당 chunk만 주고 모델이 정답을 생성할 수 있는지 검증
- Filtering: chunk 없이도 답할 수 있는 경우는 제외 → context dependency 보장
Step 3: 문서 제목 검증
- 정답 chunk가 해당 문서 title에서 나왔는지 확인 → 정확한 문서 기반임을 보장
🔎 의의: 정답 chunk의 정확성과 문서 출처의 일관성을 유지함으로써 retrieval 평가 신뢰도 확보
5. Human Validation (사람 검증)
| 검증 수 | 100 query, 총 500 chunk |
| 결과 | 모델과 평균 95% 일치, Krippendorff’s alpha = 0.85 |
| 보조 지표 | Cohen's Kappa = 0.83~0.89 (annotator 간 신뢰도 높음) |
🔎 의의: 자동 필터링의 품질을 인간 검증으로 교차 확인하여 객관성과 신뢰도 확보
✅ 벤치마크의 합당성 평가
🎯 1. 세밀한 성능 분석 가능
- Base / Oracle / Mixed 세팅을 통해 LLM이:
- 내부 지식만으로 답할 수 있는가?
- 정답 chunk를 줄 경우 잘 사용하는가?
- noise chunk가 섞이면 흔들리는가?
- ➜ 이를 기반으로 Noise Vulnerability, Context 활용도 등 세부 지표 측정 가능
🧪 2. 정확하고 작은 Retrieval Pool
- 기존 Wikipedia 전체 (5M+)가 아니라 37.8K chunks로 구성
- ➜ 연산 자원 효율적이며, 재현성 높은 실험 환경 제공
🔍 3. Retriever와 LLM 분리 평가 가능
- LLM만 고정하고 retriever 성능 분석 가능
- retriever 고정하고 LLM 능력만 분석도 가능
- ➜ RAG 시스템 전체를 다층적으로 분석 가능
🔬 4. Label 정확성과 검증 신뢰도 확보
- 자동 필터링 + 인간 검증 조합
- Cohen’s Kappa, Krippendorff’s α 활용한 합리적 검증 설계
⚖ 5. 범용성
- 다양한 LLM, 다양한 retriever에 대해 실험 가능
- Top-k 설정을 조절하며 noise sensitivity도 측정 가능
📌 결론 요약
| 목적 | RAG 평가를 retrieval, generation 모두 고려한 정밀 분해 평가 |
| 구성 | 7.5K QA + 37.8K chunk + 정답/오답 chunk 구성 + base/oracle/mixed 세팅 |
| 생성 과정 | 다단계 필터링 (Command-R, LLaMA-3.1, 사람 검증)으로 정확도 및 신뢰도 확보 |
| 합당성 | 정량 평가 지표, LLM-Retriever 분리 실험, 효율적인 리소스 사용으로 실제 연구에 적합 |
✅ 1. 주요 실험 결과 (Results)
📌 실험 설정 요약
| 항목 | 설명 |
| RAG 구성 | 5개 LLM × 5개 retriever × Top-1/3/5 (총 60조합 실험) |
| 평가 설정 | Base (내부 지식), Oracle (정답 chunk), Mixed (정답 + noise chunk) |
| 평가 지표 | Accuracy + 4가지 RAG 적응성 지표: Noise Vulnerability, Context Acceptability, Context Insensitivity, Context Misinterpretation |
📊 대표 성능 비교 예시 (Mixed Context Accuracy)
| LLM | Retriever | Accuracy (Mixed) | Noise Vulnerability ↓ | Context Acceptability ↑ |
| GPT-4o | nv-embed-v2 | 87.5% | 10.6% | 80.5% |
| GPT-3.5 | BGE-Base | 87.3% | 16.4% | 74.6% |
| LLaMA2-7B | Contriever | 74.2% | 36.8% | 46.2% |
🔍 분석:
- 최신 LLM(GPT-4o) + 강력한 retriever(nv-embed-v2) 조합이 가장 강건
- 작은 모델일수록 noise에 더 취약
- Top-3 수준에서 가장 성능이 좋고, Top-5는 noise가 증가해 성능 저하 발생
🧾 2. 결론 (Conclusion)
논문에서 제시한 결론은 다음과 같습니다:
🧠 MIRAGE의 장점 요약
- Retrieval과 Generation 성능을 분리하여 분석 가능
- Base / Oracle / Mixed 입력 구성으로 노이즈 민감도 및 문맥 활용 능력 평가
- Metric 중심 설계로 모델 약점 식별 및 최적 조합 도출 가능
- 적은 연산 리소스로도 재현 가능 → 효율성과 실용성 확보
“MIRAGE는 단순한 성능 비교를 넘어, RAG 시스템이 어떤 정보에 민감하게 반응하고, 어떤 상황에서 실패하는지를 정량적으로 보여주는 프레임워크이다.”
⚠ 3. 한계 (Limitations)
| 한계 항목 | 설명 |
| 🧠 모델 사전 학습 데이터 오염 가능성 | TriviaQA, NQ 등 공공 QA셋 기반이므로 일부 문항이 사전 학습에 포함되었을 가능성 |
| 🔁 단일-hop QA 중심 | 정답이 1개 chunk에 존재하는 구조 → Multi-hop reasoning 평가 불가능 |
| ⚖ 데이터셋 불균형 | NQ 등 일부 QA셋 비중이 높아 retriever가 특정 패턴에 과적합할 위험 |
| 🎯 Oracle 세팅의 낮은 난이도 | 최신 모델들은 Oracle 조건에서 >90% 정확도 → 난이도 한계 존재 |
| ❗ 필터링 오류 가능성 | 자동 라벨링 기반으로 일부 false label 존재 가능성 (소수지만 영향 있음) |
🎁 4. 기여 (Contributions)
| 기여 항목 | 상세 내용 |
| 🎯 정밀 RAG 평가 프레임워크 제안 | Retrieval과 Generation을 독립적으로 평가할 수 있도록 설계 |
| 📊 4가지 적응성 중심 Metric 제안 | Noise Vulnerability, Context Acceptability, Context Insensitivity, Misinterpretation |
| 🔍 다양한 모델 조합 분석 실험 | 60개 조합에 대해 Top-k 설정별 RAG 민감도 실험 수행 |
| 🧩 고품질 데이터셋 구축 | 7,560 QA 쌍 + 37,800 chunk + 필터링 및 인간 검증 기반의 고정확도 구성 |
| ⚖ 경량화된 평가 가능 | 대규모 위키 덤프 없이도 정확도 높은 RAG 평가 가능 (retrieval 효율 향상) |
📌 한눈에 정리
| 항목 | 요약 |
| 결과 | GPT-4o + nv-embed-v2 조합이 가장 noise에 강함, LLM 성능별 문맥 활용도 차이 큼 |
| 결론 | MIRAGE는 retrieval과 generation을 분리·정량적으로 평가 가능하게 하는 최초의 metric 중심 벤치마크 |
| 한계 | 단일-hop 중심, 데이터 오염 가능성, oracle 정확도 높아 난이도 제한 |
| 기여 | 정량 지표 4종 제안 + retriever-LLM 조합별 평가 가능 + 효율적이고 재현 가능한 벤치마크 공개 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| EMB와 GEN을 한꺼번에 - GEM: Empowering LLM for both Embedding Generation and Language Understanding (1) | 2025.07.16 |
|---|---|
| USER-LLM: Efficient LLM Contextualization with User Embeddings (3) | 2025.07.13 |
| DPR - Dense Passage Retrieval for Open-Domain Question Answering (6) | 2025.07.10 |
| TriviaQA 논문 확인 및 평가 코드 작성 (6) | 2025.07.08 |
| DoGe 관련 논문 조사 6 - Synthetic QA Data, SELF-ROUTE (0) | 2025.07.08 |